
Neural machine translation | Coursework 1
Your task is to implement a neural machine translation pipeline by extending a simple baseline model. In each part of the coursework you will be asked to implement a different extension.
Getting started [20 marks]
To get started, you need to setup your virtual environment. If you do not already have Anaconda, install it now:
wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh
bash Miniconda3-latest-Linux-x86_64.sh
rm Miniconda3-latest-Linux-x86_64.sh
We will create a new environment called mtenv (the commands will work with both Anaconda 2 and 3):
conda create --name mtenv python=3
source activate mtenv
conda install seaborn pandas matplotlib
pip install tqdm
pip install chainer
conda install ipython
conda clean -t
If you have access to a GPU, run pip install cupy before pip install chainer to enable CUDA support.
You can leave the environment by running source deactivate mtenv.
Now get the code.
git clone https://github.com/ida-szubert/INFR11062
You’ll find a directory data containing English and Japanese parallel data (from a tutorial that you may find helpful), a model directory containing a pretrained Japanese-to-English neural translation model, and three python files:
-
nmt_config.pycontains configuration parameters, some of which you will be asked to experiment with. In particular, pay close attention to the model and training parameters towards the end of the file. You may also adjust thegpuidparameter if you have access to a GPU, which will make training times faster (but they will still take considerable time to train, so you should give yourself plenty of time even if you have a GPU). -
nmt_translate.pytrains a translation model (if one is not already present) and translates test sentences. You will not need to modify this script. -
enc_dec.pycontains a simple translation model, specified using the chainer library. You will need to understand and modify this code as instructed below in order to complete the coursework. Doing so should give you a good idea of how a neural machine translation system works, at a level of detail that you can’t get from lectures or reading.
Run the following commands:
source activate mtenv
ipython
In [1]: %run nmt_translate.py
You should see a message indicating that a pre-trained model has been loaded. To translate using this model, do:
In [2]: _ = predict(s=10000, num=10)
This displays translations of the first 10 japanese sentences of the dev set. To view predictions on training set do:
In [3]: _ = predict(s=0, num=10)
Most of these translations will be poor. To find better translations from this model, we can add filters based on precision and recall of each translation with respect to a reference translation.
The following statement will only display predictions with recall >= 0.5
In [4]: _ = predict(s=10000, num=10, r_filt=.5)
The following statement will only display predictions with precision >= 0.5
In [5]: _ = predict(s=10000, num=10, p_filt=.5)
This model is still quite basic and trained on a small dataset, so the quality of translations is poor. Your goal will be to see if you can improve it.
The current implementation in enc_dec.py encodes the sentence using a bidirectional LSTM: one passing over the input sentence from left-to-right, the other from right-to-left. The final states of these LSTMs are concatenated and fed into the decoder, an LSTM that generates the output sentence from left-to-right. The encoder is essentially the same as the encoder described in Section 3.2 of the 2014 paper that now forms the basis of most current neural MT models. The decoder is simpler than the one in the paper (it doesn’t include the context vector described in Section 3.1), but you’ll fix that in Part 3.
Before we go deeply into modifications to the translation model, it is important to understand the baseline implementation, the data we run it on, and some of the techniques that are used to make the model run on this data.
Q1. [10 marks] The file enc_dec.py contains explanatory comments to step you through the code. Five of these comments (A-E) are missing, but they are easy to find: search for the string __QUESTION in the file. A sixth comment (F) is missing from file nmt_translate.py. For each of these cases, please (1) add explanatory comments to the code, and (2) copy your comments to your answer file (we will mark the comments in your answer file, not the code, so it is vital that they appear there). If you aren’t certain what a particular function does, refer to the chainer documentation.(However, explain the code in terms of its effect on the MT model; don’t simply copy and paste function descriptions from the documentation).
In preparing the training data, word types that appear only once are replaced by a special token, _UNK. This prevents the vocabulary from growing out of hand, and enables the model to handle unknown words in new test sentences (which may be addressed by postprocessing).
Q2. [10 marks] Examine the parallel data and answer the following questions.
- Plot (choose sensible graphs) the distribution of sentence lengths in the English and Japanese and their correlation. What do you infer from this about translating between these languages?
- How many word tokens are in the English data? In the Japanese?
- How many word types are in the English data? In the Japanese data?
- How many word tokens will be replaced by _UNK in English? In Japanese?
- Given the observations above, how do you think the NMT system will be affected by differences in sentence length, type/ token ratios, and unknown word handling?
Part 2: Exploring the model [30 marks]
Let’s first explore the decoder. It makes predictions one word at a time from left-to-right, as you can see by examining the function decoder_predict in the file enc_dec.py. Prediction works by first computing a distribution over all possible words conditioned on the input sentence. We then choose the most probable word, output it, add it to the conditioning context, and repeat until the predicted word is an end-of-sentence token (_EOS).
Q3. [10 marks] Decoding
- Currently, the model implements greedy decoding, of always choosing the maximum-probability word at each time step. Can you explain why this might be problematic? Give language specific examples as part of your answer.
- How would you modify this decoder to do beam search—that is, to consider multiple possible translations at each time step. NOTE: You needn’t implement beam search. The purpose of this question is simply for you to think through and clearly explain how you would do it.
- Often with beam search (and greedy decoding), the decoder will output translations which are shorter than one would expect, as such length normalization is often used to fix this. Why does the decoder favour short sentences? What is a problem that length normalization can introduce?
The next two questions ask you to modify the model and retrain it. Implementing the modifications will not take you very long, but retraining the model will.
NOTE. I recommend that test your modifications by retraining on a small subset of the data (e.g. a thousand sentences). To do that, you should change the USE_ALL_DATA setting in nmt_config.py file to False. The results will not be very good; your goal is simply to confirm that the change does not break the code and that it appears to behave sensibly. This is simply a sanity check, and a useful time-saving engineering test when you’re working with computationally expensive models like neural MT. For your final models, you should train on the entire training set.
Q4. [10 marks] MOAR layers!
- Change the number of layers in the encoder = 2, decoder = 3. Retrain the system.
- Draw a diagram showing this new architecture (you may ignore the memory cell of the LSTM).
- What effect does this change have on dev-set perplexity, BLEU score and the training loss (all in comparison to the baseline)? Can you explain why it does worse/better on the dev set than the baseline single layer model? (For reference, the baseline was trained for 12 epochs.) Can you explain why it does worse/better on the training set than the baseline? Is there a difference between the dev set and training set performance? Why is this case?
As a basis for your comparison, here are results for the baseline model (using chainer 3.4.0):
- dev set BLEU: 14.47
- dev set perplexity: 32.60
- average training set loss during last epoch: 4.68
You will get different results depending on your chainer version, and should report the version you use. Here are baseline results using chainer 1.24:
- dev set BLEU: 17.60
- dev set perplexity: 42.08
- average training set loss during last epoch: 3.58
To train a new model, you have to modify nmt_config.py with your required settings - the number of layers you wish to use, layer width, number of epochs and a name for your experiment.
As an example, let’s define a new model with the size of hidden units in the LSTM(s) as 100, and 2 layers for both the encoder and the decoder:
# number of LSTM layers for encoder
num_layers_enc = 2
# number of LSTM layers for decoder
num_layers_dec = 2
# number of hidden units per LSTM
# both encoder, decoder are similarly structured
hidden_units = 100
And set the number of epochs equal 1 or more (otherwise the model will not train):
# Training EPOCHS
NUM_EPOCHS = 10
To start training a model with updated parameters execute the bash script:
./run_exp.bat
After each epoch, the latest model file is saved to disk. The model file name includes the parameters used for training. As an example, with the above settings, the model and the log file names will be:
model/seq2seq_10000sen_2-2layers_100units_{EXP_NAME}_NO_ATTN.model
model/train_10000sen_2-2layers_100units_{EXP_NAME}_NO_ATTN.log
Q5. [10 marks] An important but simple technique for working with neural models is dropout, which must be applied in a particular way to our model. Implement the method of dropout described in this paper. This change should require no more than one or two lines, but will test your understanding of the code (because you need to identify where it should go).
Retrain you model.
- You should also explain where you added dropout to the code and what parameters you used for it.
- How does dropout affect the results, compared to the baseline? As in the previous question, your answer should explain the changes to perplexity and BLEU in the dev set, and training set loss.
- It is not always the case that both BLEU and perplexity improve. Sometimes BLEU improves and perplexity degrades or vice-versa. This is unexpected as they are both meant to measure the quality of the translations. Explain why this can happen.
Part 3: Attention [50 marks]
The last change you will implement is to augment the encoder-decoder with an attention mechanism. For this, we expect you to use a very simple model of attention, _global attention with dot product_, as described in this paper. This is the simplest model of attention, and reasonably effective in many settings. As a practical matter, at each time step it requires you to take the dot product of the decoder hidden state with the hidden state of each input word (itself the concatentation of forward and backward encoder LSTM hidden states). The results should be passed through the _softmax_ function (i.e. exponentiated and normalized) and the resulting distribution should be used to interpolate the input hidden states to produce a context vector used as additional input to the decoder.
Q6. [20 marks] Implement the attention model described above. You will find placeholders in the code to save the hidden states of the encoder and return an array of attention weights. Using this API will help ensure that your code works correctly.
Q7. [5 marks] Retrain your decoder, and again explain how the change affects results compared to the baseline in terms of perplexity and BLEU on the dev set, and training set loss.
Q8. [10 marks] Visualize the evolution of the attention vectors for five decoded sentences, using the provided code. Do they seem reasonable? Why or why not? Base your argument in evidence from the data. You’ll need to understand the Japanese words to do this effectively (use Google Translate). If the attention does not look reasonable, is it still a better translation than the baseline model? If it is, what does this say about attention?
We provide a function, plot_attention to plot attention vectors. A plot will be generated and stored in the model directory. To do this
set plot=True in the predict function.
_ = predict(s=10000, num=1, plot=True)
This will output a heatmap of the attention vectors and save the plot as model/sample_10000_plot.png
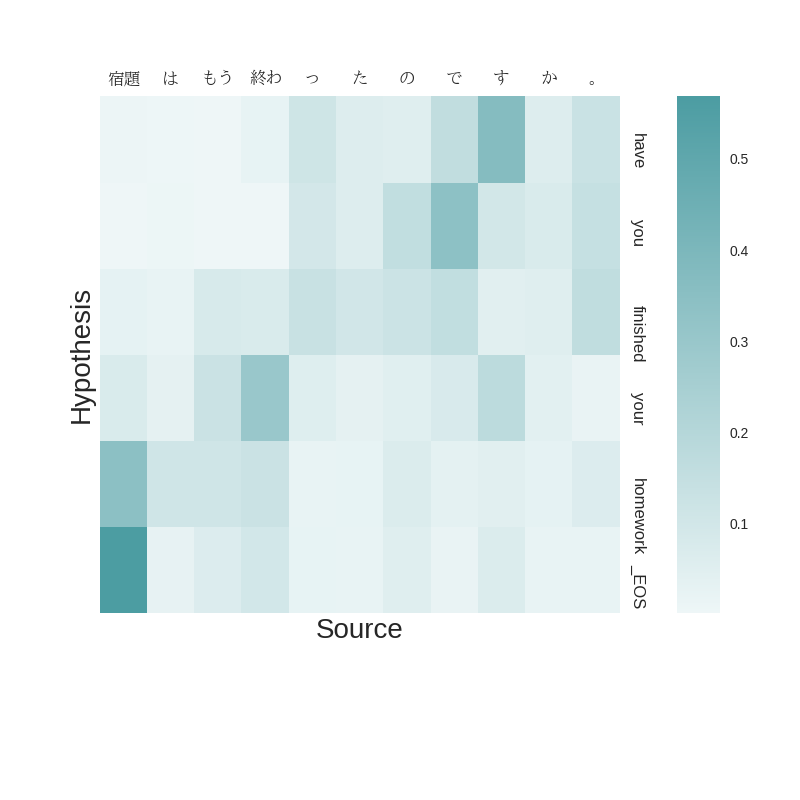
Q9. [15 marks] Where does attention help?
You should have seen that your BLEU and perplexity scores improved when using attention. Can you find any patterns in which type of source-target pairs this improvement is found?
- Come up with hypotheses of what type of source or/and target sentence benefit from attention. Give reasons for your hypothesis.
- Find evidence which tests this hypothesis. You may want to consider using perplexity on individual sentences within the dev set (however you may gather evidence any way you like).
- Evaluate your evidence, does it support your hypothesis? What does your evidence mean?
Ground Rules
-
You must use the overleaf template for your report. You are permitted up to four (4) pages for the main text of your answers and an unlimited number of pages for references and appendices, including plots, figures, diagrams, and long examples. Your appendix should not include any information (e.g. equations) that is essential to understand how you approached your problem or implemented your solution, but supporting figures, especially if they contain concrete evidence illustrating some point, are very welcome.
-
You are encouraged to work in pairs. I encourage you to seek partners with complementary skills to your own. But choose your partner wisely: if you submit as a pair, you agree to receive the same mark for your work. I refuse to adjudicate Rashomon-style stories about who did or did not contribute. If you would like a partner but have no one in mind, you can search for a partner on piazza. You are only permitted to work with one other person; groups of three or more are not allowed. The code and report must be the work of your own pair, and the normal policy on academic misconduct applies.
Once you have agreed to work with a partner, you must [email me with “5636915” in the subject line] Rico.sennrich AT ed.ac.uk Please copy your partner on this email, and include both UUNs in the body of the email. I will then know that a submission received from either UUN should be marked on behalf of both you and your partner, and you should submit your joint report from only one of these UUNs. You may not change partners after you have emailed me. This means that your email consistutes an agreement to the parameters outlined above. It will also help us predict marking load, which may mean you get your results faster. I will ignore emails received after the deadline.
- You must submit these files and only these files.
answers.pdf: A file containing your answers to Questions 1 through 9 in an A4 PDF. Your file must be written in LaTeX using the overleaf template, which you should clone and edit to provide your answers. Answers provided in any other format will receive a mark of zero. Your answers must not exceed 4 pages, so be concise. You are permitted to include graphs or tables on an unlimited number of additional pages. They should be readable. They should also be numbered and the text should refer to these numbers.attention.py: Your modified version ofenc_dec.pyincluding both dropout and attention (or whichever of these you complete, if you don’t complete the assignment).translations.txt: The output of your final model on the test set. Your answers to questions 8 and 9 should refer to translations in this file.
- Your name(s) must not appear in any of the submitted files. If your name appears in either file you will (both) receive a mark of zero.
To submit your files on dice, run:
``` submit mt cw1 answers.pdf attention.py translations.txt
```
Tel: +44 131 651 5661, Fax: +44 131 651 1426, E-mail: school-office@inf.ed.ac.uk
Please contact our webadmin with any comments or corrections. Logging and Cookies
Unless explicitly stated otherwise, all material is copyright © The University of Edinburgh.
Material on this page is freely reuasable under a Creative Commons attribution license,
and you are free to reuse it with appropriate credit. The website is based on source code by Adam Lopez, available on github.