Individual Practical (07-08): Diagrams for Searchable Database
Abstract view of distributed hash table
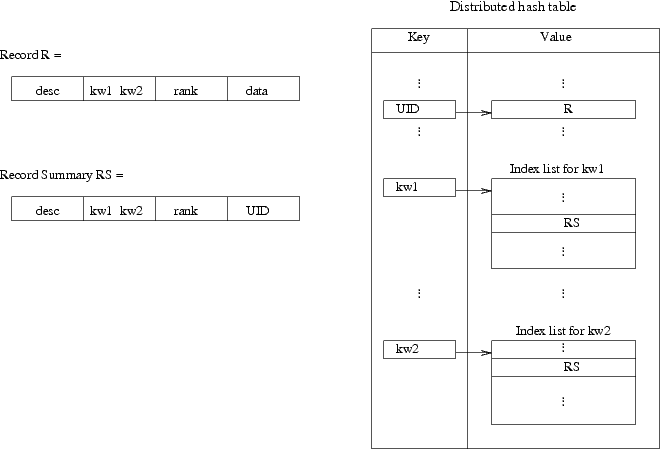
This shows how an entry for a record and its associated summaries
ought to be stored in a distributed hash table. On the left are
representations of a record R with two key words kw1 and kw2 and an
associated record summary RS , where the data is replaced by some
unique identifier UID for the record.
On the right is an abstract view of the distributed hash table.
The view is abstract because it does not show how the table is
split up amongst the tables local to each node in the distributed
ring. The record is stored as a value with a uniquely generated
identifier as the key, and a record summary is stored in the index
list associated with each key word.
Example database configuration
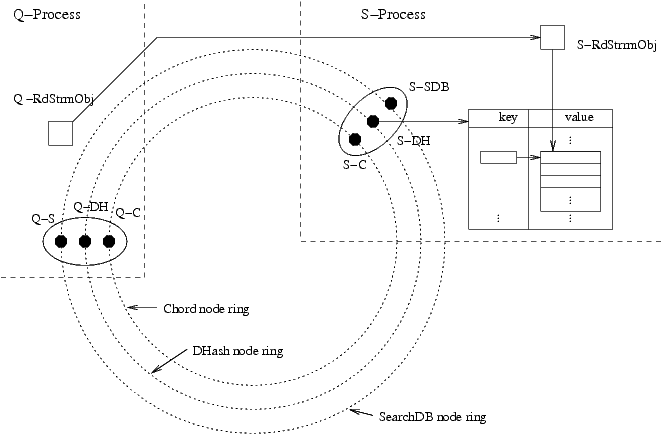
This picture depicts a scenario in which a client of the
searchable database initiates a search by calling a query method
on a SearchDB node Q-S. This node is linked to a DHash node Q-DH
which is linked to a Chord node Q-C and all these nodes reside in
some process Q-process. We assume the query is a conjunction of
keywords, some possibly negated. This query method selects a
primary keyword to use for this search and locates the node-triple
in the ring responsible for storing the index list associated with
this triple. The triple and the associated index list are shown
on the right of the diagram. The node triple and the index list
are all on the heap of some process S-process. Through a method
call sequence detailed below, a readable stream S-RdStream is
created in the S-process that filters out from this index list the
record summaries that match the query formula, ordering the
summaries with the highest ranked first. Back in the Q-Process
another readable stream object Q-RdStream is created which has a
remote reference to S-RdStream. Q-RdStream is returned back to
the client who initiated the query.
If the query had been of form `A OR B' where A and B were simply
conjunctions of keywords, then two storage nodes would be located,
one for holding the index list for some primary keyword from A,
the other holding the index list for some primary keyword form
B. The Q-RdStream would then have remote references to two
readable streams, one in each of the processes holding a storage
node, and would merge these two streams together.
Use of distributed hash table application nodes
In Part 2, SearchDB nodes take on the role of being the
`application nodes' of the provided Part 2 distributed hash table.
The diagram here shows how the distributed hash table code for
interfacing to application nodes is used in query processing.
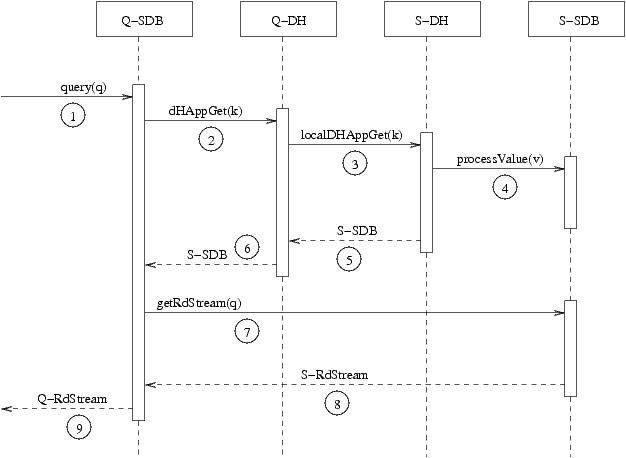
This is an approximation of a Message Sequence Chart or UML
Sequence Diagram. Each column is for one of the objects from the
previous figure and time runs down the diagram. The sequence of
events depicted is:
- The client initiates a query by calling the query(q) method on the
Q-SDB SearchDB object with some Boolean query q as argument.
- The query(q) method identifies a primary key k and,
by calling dHAppGet(k) on the DHash node Q-DH, asks the
distributed hash table for the searchable database node
handling the key's value (the index list associated
with k).
- The dHAppGet(k) invocation identifies the DHash node holding
the local map for k as S-DH, and, by RMI, invokes the
localDHAppGet(k) method on S-DH.
- The localDHAppGet(k) invocation does not simply return the
value corresponding to key k, as localGet(k) does. Instead it
passes the index list value v onto the
SearchDB node S-SDB associated with S-DH by calling the
processValue(v) method on the S-SDB object.
The processValue(v) invocation on S-SDB just temporarily stores
the index list value v in some instance field of S-SDB, just as
the value is stored in the provided example SimpleDHAppImp class.
- The localDHAppGet(k) invocation on S-DH finishes by returning
a remote reference to S-SDB.
- In turn, the dHAppGet(k) invocation returns this remote reference
to S-SDB to the query() method running on the Search DB node Q-SDB
handling the query.
- By invoking the method getRdStream(q) on the SearchDB
node S-SDB, the query() method passes the Boolean query q to S-SDB
which is caching a reference to the index list for the primary key
k of q.
- The getRdStream(q) execution uses the Boolean query q
to create and return a readable stream S-RdStream of record
summary objects that satisfy the query.
- The query(q) method finishes its execution by wrapping a remote
reference to S-RdStream with its own readable stream that buffers
the stream.
Paul Jackson,
Paul.Jackson (@) ed.ac.uk
Last modified: Mon Nov 26 17:32:35 GMT 2007

