Read through this Wikipedia article carefully.
Discuss the following questions with your partner:
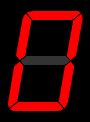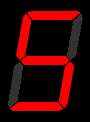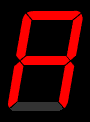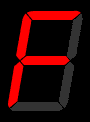
As any user of an electronic calculator knows, the ten Arabic digits can be represented as an array of seven features - three horizontal lines and four vertical lines.
This gives us an idea for encoding the input layer for a letter/word recognition neural network - we have seven input perceptrons, each of which is either on or off.
Is it possible to represent every letter in the English alphabet using these seven feature detectors?
You may want to check out this page for inspiration. Or maybe this one.
The seven segment display is OK, but not particularly good at representing English letters. Can you come up with something better? How many feature detectors (or input perceptrons) do you need?
The basic letter recognition task involves taking a visual image as input and deciding which letter of the English alphabet the input best corresponds to.
Based on the set of feature detectors you came up with in the previous question, and what you know about simple, two-layer, feed forward pattern associator neural networks, sketch out a quick plan for building and training a system that can do this task.
Write down a couple of examples of "dirty" input to the system. What should your trained neural network output for these cases?
The output layer of this pattern associator has a serious deficiency for the letter recognition task - think about how many output perceptrons we want to fire at any one time. What is the problem? How might we go about using lateral inhibition to solve it?
Think about the following questions:
Run the following commands in your UNIX terminal:
[verve]mmcconvi: python
>>> import nltk
>>> from nltk.corpus import brown
>>> flws = [w.lower() for w in brown.words() if len(w)==4 and w.isalpha()]
>>> flws
>>> len(set(flws))
>>> f = nltk.FreqDist(flws)
>>> flws2 = [w for (w,c) in f.items() if c>1]
>>> len(set(flws2))
What does this tell you?
The word recognition task involves taking a sequence of four letters as input and deciding which valid English four-letter-word the input best corresponds to.
Based on the output layer you came up with in the previous question, and what you know about simple, two-layer, feed forward pattern associator neural networks, sketch out a quick plan for building and training a system that can do this task. Would lateral inhibition help?
Write down a couple of examples of "dirty" input to this system. What should your trained neural network output for these cases?
Now we are interested into building a system which combines the previous two networks you designed. The input to this composite system will be a visual representation of a four-letter-word (encoded in terms of letter features) and the output will be the proper English word it is most likely to represent.
Sketch out a combined three-layer network, that incorporates both networks you defined in the previous two questions in an intuitive way.
How many input perceptrons will you need? What will they each represent? How many on each of the other two layers?
The WSE suggests that the letter recognition task is influenced by context. For example, if the letter in positions 2-4 are HIP, then what does this tell us about the letter in position 1? And if the letter in position 1 is a Q, what does this tell us about the letters in positions 2 and 3?
How might you go about improving your combined network to account for the context effect in letter recognition? Think about what extra connections you could add, and whether they should be excitatory or inhibitory.
The relevant model is discussed here. You don't have time to read this just now, but I recommend you come back to it at your leisure. What you should do just now is examine Figures 2, 3 and 4 carefully and compare them with what you came up with. pay particular attention to the the distinction between connections that end in little black dots and those that end with little black triangles.
There is an online simulation of the model here. Read the instructions carefully and play about with it for a bit. Some examples of input sequences to try out are "chip", "ghip", "work", "wor*", etc. Make sure you understand what the output is telling you. You can look at both output words, or just the output letters in particular positions.
Another example of an interactive activation model involves the Jets and Sharks gangs. You can see a visual simulation of this model here. And you can read about it in Ex 2.1 of the PDP manual. Or here.
Play with the visual simulation, hovering over each of the perceptrons to see what happens (Don't click on them yet, just hover!). Think about the following:
The Science of Word Recognition by Kevin Larson.