|
When you're working in an imperative object oriented language such as Java, most objects are mutable: their data can change, e.g. an object's state can change as a result of it being sent a message. Some are immutable: their data can't change. For example, objects of Java class String are immutable. Although you can send a String s a message - you can write s.toLowerCase(), for example - to ask it to calculate a new String, this does not change s's state. Instead, it returns a new String object with a different state from s's state. This is not inevitable, it's a design choice: Smalltalk, for example, has mutable String objects. Immutable objects tend to be easier to reason about, but harder to program with. (Much more could be said here.) I suggest as a rule of thumb that the more you tend to think about your class as something that is so small and basic it should be in some class library you didn't have to write, the more likely it is that you should make it immutable. A widely acknowledged mistake in the design of the Java standard library is that it has a mutable Date class; see the Joshua Bloch lecture later in this course. (An illustration of how hard it can be to correct design mistakes if you don't have control over other software that depends on yours is that even though it's been widely agreed to be a mistake for more than 10 years, it has not proved possible to correct this in later releases of the Java library!)
An interesting subtlety is whether, if object p has a reference to object q, we should count the state of object q as also being part of p's state. Normally we wouldn't: we'd include the fact that p is linked to this particular object q as part of p's state, but we'd stop there. You should bear in mind that if you take this definition, a consequence is that p's behaviour on receiving a certain message could change, even without p's state changing in the meantime.
Behaviour is a more inclusive term than interface. The interface of an object is usually understood to be the messages an object can receive and some specification of what it will do in response. Behaviour includes all the details. You design the behaviour; you want your clients to rely on the interface. (And, as we'll discuss later when we get to Liskov substitutivity, one problem is that sometimes they actually rely on more than what you think of as the interface!)
(It wasn't an accident that that example relied on the object being mutable. If objects of the same class have identical state and are immutable, then you have (by definition) no way to tell the difference between them. So although we could argue about whether immutable objects still have identity or not, at least we won't have to worry about it; we could assume two immutable objects with the same state were the same object and it wouldn't get us into any trouble. This is why immutable objects are easier to reason about.)
The overall behaviour of the system in a given scenario comes from the requirements, and is recorded in the use case text. We can choose how to approach the task:
The process of class design is not really algorithmic - practice usually includes elements of all these approaches, and requires human intelligence and practice.
However you do it, you want to end up with classes which have low coupling (minimise the dependencies between classes) and high cohesion (make each class represent the whole of an easily describable abstraction), and present an interface to the world that has an appropriate balance of sufficiency (give clients enough operations so that they can do what they need to), completeness (give them all the operations they might reasonably want) and primitiveness (only provide the operations that really need access to the underlying data). (Grady Booch Object Oriented Design with Applications, p123ff).
These things are in tension. For example, if you are wondering whether to split a class into two because you think it's actually representing two different concepts, doing so may increase cohesion, but at the same time, it may introduce coupling (e.g. between the two new classes) that wasn't visible before. Increasing the completeness of an interface (e.g. by adding a utility method that several of your clients want, even though they could implement it themselves using already existing operations) tends to reduce its primitiveness, and vice versa. That's just how it is...
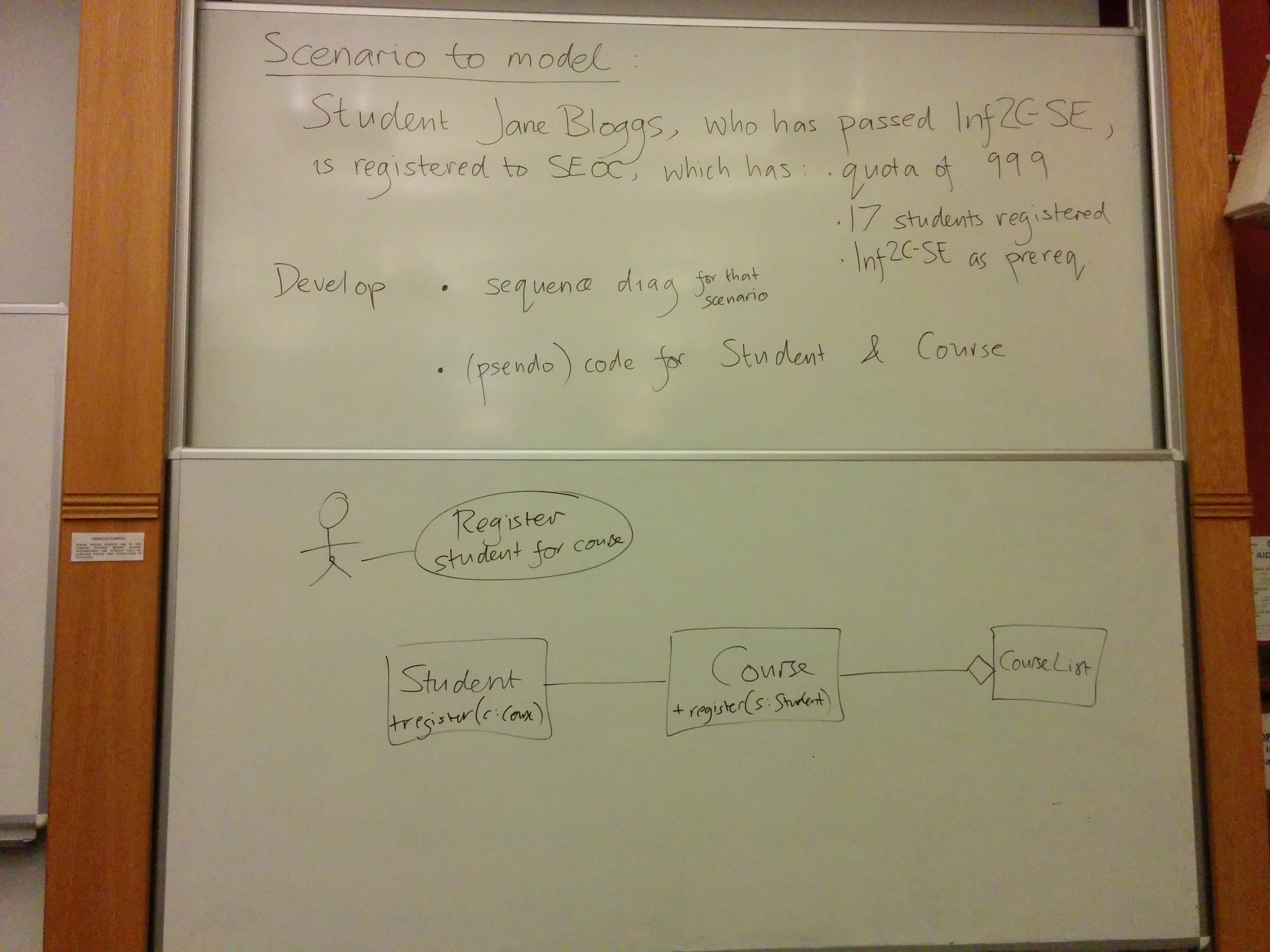
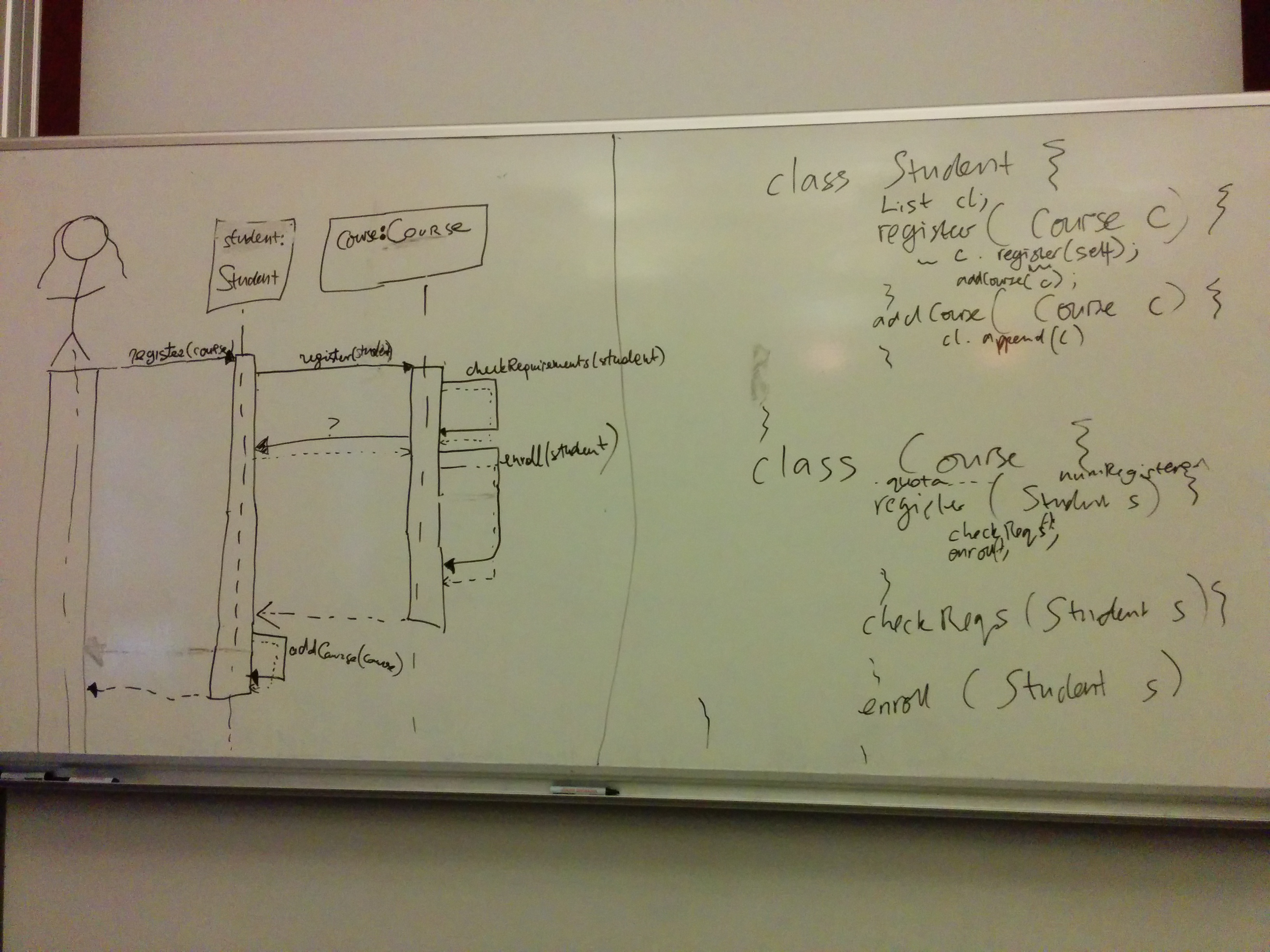
When you choose the operations for your classes to implement, try to add value. If you expect the users of your Student objects to want to find out whether a student satisfies certain prerequisites, offer an operation that does what the users want; don't just return a bunch of data and make them do the work. I tied myself in knots trying to explain this in the lecture. A better explanation, had I thought of it at the time, might have been: suppose we start off only modelling "standard" Edinburgh undergraduates, but now we have to let our Student class also represent students who have come from abroad with different qualifications. Suppose the university has some kind of procedure that validates that a given student's previous experience is suitable for letting them take a course that has Inf2C-SE as a prerequisite. If client code says s.satisfiesPrerequisites("SEOC") then we can easily incorporate the special case reasoning inside the Student class, and the client code won't have to change. If, however, client code says s.getCourses() and then does its own computation to check prerequisites, the client code will have to change to handle the special case reasoning, and either the Student class will have to expose some kind of interface to allow clients to check whether the student is a special one, or the course record will have to lie about what courses the student has taken, perhaps having to invent other associated data such as the year the course (that was not taken!) was taken, and ... yuck.
The real question is: in your real development context, is it appropriate for the Student object to have the responsibility to report what classes the student has passed, or to have the responsibility to check whether a given course has been passed? Taking on responsibilities has a cost, and you should only let your classes do it if you think the responsibility is a reasonable one. At the same time, nobody wants irresponsible classes!
We considered which class should have the responsibility to do the validation. Could be Student, could be Course. Some people introduced an extra class just to have the responsibility of registering a student for a course, reducing Student and Course to dumb data objects. I explained that I wasn't convinced about this, because dumb data classes (though sometimes appropriate... see links in the mail I sent) are not in the spirit of OO. Putting the functionality that operates on the data elsewhere prevents us from encapsulating the data, meaning that potentially all our software is vulnerable to having to change if the data, or its format, changes.
Further things we considered briefly, if at all:
Suppose the workflow of a Board of Studies goes something like this:
A course proposal has to be written, reviewed, and then either accepted and published, or rejected and the notice of rejection distributed.
The user opens a new task and fills in initial details (details may be updated at any time). Normally, the user then marks the task as in progress until it's been done, then as closed. However, any time before the task is closed, it may be deferred. A deferred task can be reopened (so that it can be re-evaluated), or marked as being in progress. A closed task may be reopened (for evaluation) if more information comes to light. Eventually the closed task is archived, after which nothing more can happen to it.
Draw a protocol state machine diagram for Task.
Note: in the process, you have defined (part of) an API for Task.
(This is extracted from a casestudy we did last year on the Borg Calendar - more details at link. We won't do that this year as I don't think it would work with such a large group, but you might find it interesting, especially if you are yearning for a large body of code to study the design of.)
perdita@inf.ed.ac.uk)
|
Informatics Forum, 10 Crichton Street, Edinburgh, EH8 9AB, Scotland, UK
Tel: +44 131 651 5661, Fax: +44 131 651 1426, E-mail: school-office@inf.ed.ac.uk Please contact our webadmin with any comments or corrections. Logging and Cookies Unless explicitly stated otherwise, all material is copyright © The University of Edinburgh |


{kind=link}
{kind=link}