Git - Source Code Control
Software Engineering Large Practical
No Tutorials
There seems to be a little confusion over whether or not there are any
tutorials. There are no tutorials so you do not need to worry about
attending any.
Today's Lecture
- I will talk about your source code control mechanism,
git
- Since I want your proposal to be stored under source code control, I'd better say something about it now
- I will start with a very brief tutorial
- What you need to know for this practical
- I will then try to motivate more sophisticated use
Basic Source Code Control
As I stated previously the first thing to do is to initialise your repository
$ mkdir selp # Call it something sensible
$ cd selp
$ git init
$ editor README.md
$ git add README.md
$ git commit -m "Initial commit including a README"
The main point
- After each portion of work, commit to the repository what you have done
- Everything you have done since your last commit, is not recorded
- You can see what has changed since your last commit, with the
status and diff commands:
$ git status
# On branch master
nothing to commit (working directory clean)
Staging and Committing
- If I edit a file the
git status command will tell me
what has changed
$ editor README.md
$ git status
# On branch master
# Changed but not updated:
# (use "git add ‹file›..." to update what will be committed)
# (use "git checkout -- ‹file›..." to discard changes in working directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
Unrecorded and Unstaged Changes
- A
git diff at this point will tell me the changes I have
made that have not been committed or staged
$ git diff
diff --git a/README.md b/README.md
index 9039fda..eb8a1a2 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,2 @@
I am going to write a new web site.
+The web site will rank video games for difficulty.
Staging and Committing
- When you commit, you do not have to record all of your recent
changes. Only changes which have been staged will be recorded
- You stage those changes with the
git add command.
To Add is to Stage
- If I stage that modification and then ask for the status
I will be told that there are staged changes waiting to be committed
- To stage the changes in a file use
git add
$ git status
# On branch master
# Changed but not updated:
# (use "git add ‹file›..." to update what will be committed)
# (use "git checkout -- ‹file›..." to discard changes in working directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
$ git add README.md
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD ‹file›..." to unstage)
#
# modified: README.md
#
Viewing Staged Changes
- At this point
git diff is empty because there are no
changes that are not either committed or staged
- Adding
--staged will show differences which have
been staged but not committed
$ git diff # outputs nothing
$ git diff --staged
diff --git a/README.md b/README.md
index 9039fda..eb8a1a2 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,2 @@
I am going to write a new web site.
+The web site will rank video games for difficulty.
New Files
- Creating a new file causes git to notice there is a file which is not
yet tracked by the repository
- At this point it is treated equivalently to an unstaged/uncommitted change
$ editor mycode.mylang
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD ‹file›..." to unstage)
#
# modified: README.md
#
# Untracked files:
# (use "git add ‹file›..." to include in what will be committed)
#
# mycode.mylang
New Files
- Slightly tricky,
git add is also used to tell git to start
tracking a new file
- Once done, the creation is treated exactly as if you were modifying an
existing file
- The addition of the file is now treated as a staged but uncommitted change
$ git add mycode.mylang
# On branch master
# Changes to be committed:
# (use "git reset HEAD ‹file›..." to unstage)
#
# modified: README.md
# new file: mycode.mylang
#
Committing
- Once you have staged all the changes you wish to record,
use
git commit to record them
- Give a useful message to the commit
$ git commit -m "Added more to the readme and started the implementation"
[master a3a0ed9] Added more to the readme and started the implementation
2 files changed, 2 insertions(+), 0 deletions(-)
create mode 100644 mycode.mylang
A Clean Repository Feels Good
- After a commit, you can take the status, in this case there are no changes
- In general though there might be some if you did not stage all of your changes
$ git status
# On branch master
nothing to commit (working directory clean)
Ignoring Files
- Compiling and running your application may well produce files that
you do not wish to be recorded in the repository
- Git will “complain” about untracked files
- Your .gitignore file is used to ignore them
$ cat .gitignore
*.py[cod]
# editor backup files
*~
# C extensions
*.so
Ignoring Files
- Don't forget to store your .gitignore file itself in the repository
$ git add .gitignore
$ git commit -m "Added a .gitignore file"
Finally git log
- The
git log command lists all your commits and their messages
$ git log
commit a3a0ed90bc90e601aca8cc9736827fdd05c97f8d
Author: Allan Clark ‹author email›
Date: Wed Sep 25 10:26:57 2013 +0100
Added more to the readme and started the implementation
commit 22de604267645e0485afa7202dd601d7c64c857c
Author: Allan Clark ‹author email›
Date: Wed Sep 25 10:17:45 2013 +0100
Initial commit
Minimal Workflow for the Lazy
- For the really lazy among you
- Simply remember two things:
- Whenever you create a new file
git add it
- Once you have done one portion of work, commit all your changes with:
git commit -a -m "Fixed bug ..."
- When you actually want to use the SCC features you can read about them then
More on the Web
- Clearly this was a very short introduction
- More can be found at the git book online at:
- And countless other websites
Keep In Mind
- Although named the Software Engineering Large Practical,
the effort and resources expended means that this is firmly in the
category of pretty small projects
- Most of this advice applies more fully to larger scale
projects with multiple developers
- However it is well worth building up the skills now
when you do not need them, such that when you do,
you do not mess up
Source Code Control - Problems
- Solves two main problems:
- Allows two or more developers to concurrently work on
the same project
- Records a history of changes made so that you can revert to
any version
Concurrent Development
- Previously solved using multiple files and good modularisation
- Multiple developers literally worked on different files
- Turns out we're not very good at modularisation
- And we're certainly not good at foresight modularisation
- Once you have the interfaces set up there is not much work left to do
Concurrent Development
- You may think that this does not apply to you as this is an
individual project
- That is to assume that you may not take on multiple roles yourself
- Even the most single-minded of you will at least:
- Develop new code
- Fix issues in existing code
Concurrent Development
- You can attempt to do these two things simultaneously, I'll briefly
attempt to convince you to do otherwise
- But I know I will fail
- I know you will disregard this advice and do your own thing anyway
- But at least then I'm not culpable
Branching

Branching
- Let us suppose you have a nice clean source code repository
- You have some modules with nice clean interfaces
- You decide today is the day that you will implement new feature X
- You can simply start implementing and committing as you go
Branching
- During your development of new feature X,
you realise that interface A
is not general enough to properly aid the development of feature X
- So now you have to modify interface A
- and perhaps even “the” implementation of A
- In short, you wish the code base had been in a different state
before you started the development of new feature X
Branching
- You should have started a new branch feature-x
- Once you discover that deficiency of interface A:
- Revert back to the master branch
- This will have none of the changes which began the implementation of feature X
- Fix the interface of A there
- Switch back to your feature-x branch
- Rebase the changes to interface A here
- Continue development of feature X
Branching
- This is the hard part: convincing you that this is worth it
- Now your history of changes has logically separated pieces of work
Branching
With simply commiting as you go:
- Created three new tests for the intended new feature X, it currently fails
- began the implementation of feature X, one of the three acceptance tests passing
- Updated the interface of A to add an extra parameter to the get_info method
- Match the updated interface of A within the implementation
- Updated the doc-comment for the updated interface of get_info method ...
- Updated the implementation of feature X all three acceptance tests now passing
- Cleaned up the new code for the implementation of feature X
- Fixed the tests broken by the update for the get_info method of interface A
- Created a new test for the extra parameter in the get_info method of interface A
- Added a new acceptance test for feature X
Branching
Branching and rebasing:
- Updated the interface of A to add an extra parameter to the get_info method
- Match the updated interface of A within the implementation
- Updated the doc-comment for the updated interface of get_info method ...
- Fixed the tests broken by the update for the get_info method of interface A
- Created a new test for the extra parameter in the get_info method of interface A
- Created three new tests for the intended new feature X, it currently fails
- began the implementation of feature X, one of the three acceptance tests passing
- Updated the implementation of feature X all three acceptance tests now passing
- Cleaned up the new code for the implementation of feature X
- Added a new acceptance test for feature X
Branching
- Why on earth do you care?
- Why would you want a history full of logically separated pieces of work?
- Because you may wish to revert any one of them
- Suppose, you fix interface A but continued development of
feature X makes you realise that this new feature
is ill-conceived:
- Perhaps it is infeasible to develop
- Or perhaps you see another way to provide the same functionality
- Now you may wish to revert the implementation of feature X
- But the new interface A is possibly still better than the previous
one, so you wish to keep that
Historical “Versions”
- This is why source code control mechanims are often called
“Revision Control Systems”
- Note that we are not talking about each explicitly marked and
labelled version, but each and every logically point in development
that has lead to the current state of affairs
- Although being able to revert to a labelled version is also useful
A common error
/*
* 12/26/93 (seiwald) - allow NOTIME targets to be expanded via $(<), $(>)
* 01/04/94 (seiwald) - print all targets, bounded, when tracing commands
* 12/20/94 (seiwald) - NOTIME renamed NOTFILE.
* 12/17/02 (seiwald) - new copysettings() to protect target-specific vars
* 01/03/03 (seiwald) - T_FATE_NEWER once again gets set with missing parent
* 01/14/03 (seiwald) - fix includes fix with new internal includes TARGET
* 04/04/03 (seiwald) - fix INTERNAL node binding to avoid T_BIND_PARENTS
*/
Why is Version Control Important
- Standard answer: “bug fixes must be back ported to older versions”
Why is Version Control Important
- Suppose you develop GolfApp 1.0
- You begin development of GolfApp 2.0
- Unfortunately someone discovers a security bug in GolfApp 1.0
- You need to revert back to the source code of GolfApp 1.0 to fix the bug for those users
- You cannot wait until you release GolfApp 2.0
- You also cannot fix the bug there and release what you have
- That source code may contain many unfinished and untested features
- Or you may not wish to give new features to GolfApp 1.0 users who have not paid for them
The Point
- Again you may think this does not apply to you because you have only
one release to make
- This allows you to revert to previous versions in order to locate
when a bug was introduced
- This can help greatly in locating the source of a bug
- This history of changes also helps other people (including your future
self) understand why the code is the way it is
- This is very helpful when you wish to change something without breaking anything
Why is that line like that?
- Suppose you're reading the linux kernel source code
- You're in ipc/msg.c
git log -S'msq = msq_obtain_object_check(ns, msqid);' ipc/msg.c
commit 41a0d523d0f626e9da0dc01de47f1b89058033cf
Author: Davidlohr Bueso
Date: Mon Jul 8 16:01:18 2013 -0700
ipc,msg: shorten critical region in msgrcv
do_msgrcv() is the last msg queue function that abuses the ipc lock Take
it only when needed when actually updating msq.
Signed-off-by: Davidlohr Bueso
Cc: Andi Kleen
Cc: Rik van Riel
Tested-by: Sedat Dilek
Signed-off-by: Andrew Morton
Signed-off-by: Linus Torvalds
commit 3dd1f784ed6603d7ab1043e51e6371235edf2313
Author: Davidlohr Bueso
Date: Mon Jul 8 16:01:17 2013 -0700
ipc,msg: shorten critical region in msgsnd
do_msgsnd() is another function that does too many things with the ipc
:
commit 41a0d523d0f626e9da0dc01de47f1b89058033cf
Author: Davidlohr Bueso
Date: Mon Jul 8 16:01:18 2013 -0700
ipc,msg: shorten critical region in msgrcv
do_msgrcv() is the last msg queue function that abuses the ipc lock Take
it only when needed when actually updating msq.
Signed-off-by: Davidlohr Bueso
Cc: Andi Kleen
Cc: Rik van Riel
Tested-by: Sedat Dilek
Signed-off-by: Andrew Morton
Signed-off-by: Linus Torvalds
commit 3dd1f784ed6603d7ab1043e51e6371235edf2313
Author: Davidlohr Bueso
Date: Mon Jul 8 16:01:17 2013 -0700
ipc,msg: shorten critical region in msgsnd
do_msgsnd() is another function that does too many things with the ipc
object lock acquired. Take it only when needed when actually updating
msq.
Signed-off-by: Davidlohr Bueso
Cc: Andi Kleen
Cc: Rik van Riel
Signed-off-by: Andrew Morton
Signed-off-by: Linus Torvalds
commit ac0ba20ea6f2201a1589d6dc26ad1a4f0f967bb8
Author: Davidlohr Bueso
Date: Mon Jul 8 16:01:16 2013 -0700
ipc,msg: make msgctl_nolock lockless
While the INFO cmd doesn't take the ipc lock, the STAT commands do
acquire it unnecessarily. We can do the permissions and security checks
only holding the rcu lock.
This function now mimics semctl_nolock().
Signed-off-by: Davidlohr Bueso
Cc: Andi Kleen
Cc: Rik van Riel
Signed-off-by: Andrew Morton
Signed-off-by: Linus Torvalds
Debugging Help
- Suppose you write some new test input, try it out, and find that it
causes your application to crash
do{ revert to previous commit/version
re-compile and re-run your new test
flag = does the program still crash
} while(flag)
Committing
- When and what to commit?
- The easy answer is it should be “one unit of work”
- Defining one unit of work is difficult but if you have to use the
word ‘and’ to describe it, there is a good chance you have
more than one commit there
- Note that my previous example was therefore bad
$ git commit -m "Added more to the readme and started the implementation"
[master a3a0ed9] Added more to the readme and started the implementation
2 files changed, 2 insertions(+), 0 deletions(-)
create mode 100644 mycode.mylang
- It is bad because it is doing two separate things, indicated by the
use of the word ‘and’, not because it updates
more than one file
Committing
- Your commit should be improving the project. It should be improving
one portion of it:
- The code
- The documentation
- The tests
- And it should be improving that one part in one way:
- Improving functionality
- Improving readability
- Improving maintainability
- Improving performance
XKCD Signal
- XKCD is a popular web comic
- It has an associated IRC channel
- As with many large communities it faced a problem of a large
noise to signal ratio
- A large part of the problem is that frequently asked questions are
not read and hence re-asked
- Common debates are hence frequently re-hashed
XKCD Signal
- In a
blog post the xkcd creator outlines a proposal to deal with this
- It has been implemented as the ROBOT9000 bot-moderator
- The rule it enforces is a simple one:
- ”You are not allowed to repeat anything anyone has already said”
XKCD Signal
- You can read about the specifics here
- But some obvious questions arise:
- Question: Isn't this limiting?
- Answer:
You're underestimating the versatility of natural language and the sheer
number of possible sentences
XKCD Signal
- You can read about the specifics here
- But some obvious questions arise:
- Question: Can't I just game it by tagging extra nonsense on?
- Answer:
Yes, but the focus is on dealing with unwitting noise generators. Those
who are actively attempting to destroy the conversation can be otherwise banned.
XKCD Signal
- You can read about the specifics here
- But some obvious questions arise:
- Question:What happens if I just want to answer someone with a yes/no?
- Answer:
Expand slightly e.g. “I agree, ... because ...”
What has this got to do with SCC?
- A persistent problem is the lack of meaningful commit messages
- “fixed a bug”
- “More work”
- “Fixes.”
- “Updates”
- “big commit of all outstanding changes”
- “commit everything”
- “commit”
What has this got to do with SCC?
- I hope to give some good advice on this writing good commit messages
- But it is notoriously difficult to enforce
- One could easily enforce a minimum length, but this would only solve
part of the problem and in some cases would not actually be appropriate
- A sneakier idea; copy the “Do not repeat” rule from XKCD-Signal
- “Do not use a commit message which has been used previously”
Non-repeating Commit Messages
- When I say “used previously”
do I mean in the same repository?
- Beginner level: yes, I mean in the same repository
- Advanced level: no, I mean in any repository that exists
for any project
- It should not really matter, it is hard to accept that a commit message
used for an entirely different project is appropriate for your one
Non-repeating Commit Messages
- Said in a whingey voice:
“But I really did just fix a typo in the README”
- You can probably expand on that a little
- However, of course some violations of this rule will be worse than others
- Similarly just because you pass this rule, does not mean you have a useful commit message
- Gaming this by adding superfluous characters is definitely wrong
Non-repeating Commit Messages
- In order to check the advanced level I will need a corpus of repositories
- I might use github for this. You certainly should not
be repeating a commit message used for an entirely different repository
- But I will at least check your commit messages against all other
repositories submitted for this practical
More Advice
- The commit message should be a summary of the actual ‘diff’
- Part of the point of the commit message is so that a reader can avoid looking
at the actual ‘diff’
- The reader is looking in the history for a reason. Most likely they are
trying to find the source of an issue. Help them.
More Advice
- You should at least make clear the purpose of the commit
- Is it?
- A bug fix
- A feature addition
- A conflict resolution between two branches
- Style enhancements
- On what scale? A single fixed spelling error, or reformating
all of the code?
- A refactor of some portion of the code
- Addition of a test
- Updating of documentation
- Optimisation
More Advice
- Even once the purpose is described, try to explain the reason
for that purpose
- Some times this will be obvious, for example if the purpose of the commit
is to fix a bug
- Even then, you may wish to explain why that is fixable now rather
than earlier
- Others, really require an associated why. In particular a refactor.
Summary of the Main Advice
- Small frequent commits. Each commit should do one thing
- Ask yourself is it plausible that you might wish to revert some of the
changes in a commit but not all of them?
- If so, you almost certainly have more than one commit's worth of work
- A person looking through your history is most likely looking for the
source of a bug, or trying to figure out why a certain bit of code
is the way it is. In either case help them.
- Some people branch for any new unit of work. You should at least branch
if you start doing two things at once
Micro Commits
- It is possible to commit too little a portion of work
- But for this practical we will ignore that possibility (unless you're clearly gaming the system)
- Just a note: small style enhancements are usually not too small
- “I just fixed a small typo in a comment, no one could possibly wish to revert to
the code before I fixed the typo”
- Probably not, but what are you about to do?
- Someone may well wish to revert to the code immediately after
you fixed the typo
Micro Commits
- If you commit code such that the “build is broken”
it is certainly not an appropriate commit
- If the code fails to compile, or has a syntax error (for dynamic languages)
- If this is the case you are likely committing too little
- Though this could also be caused by over-shooting an appropriate commit
- In other words you have 1 and a half commits worth of work
- Or 2 and a half, or X plus 1/y commits worth of work
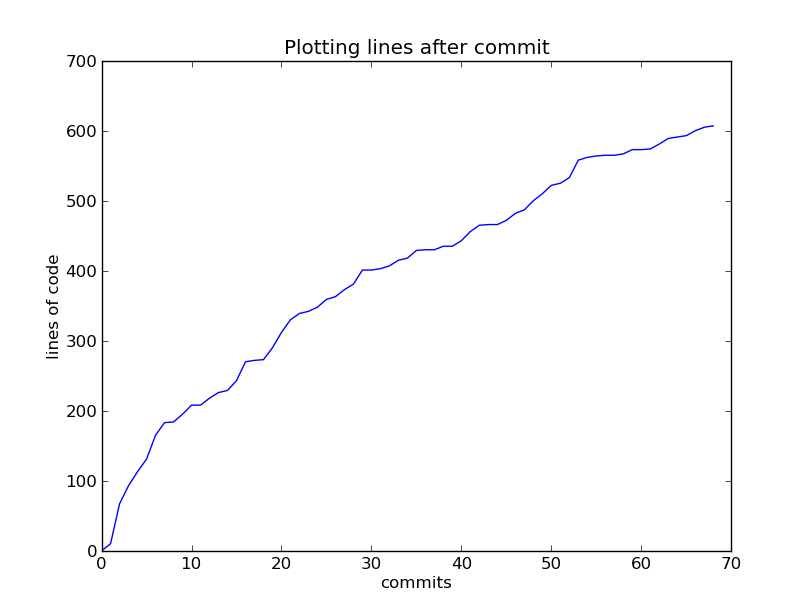
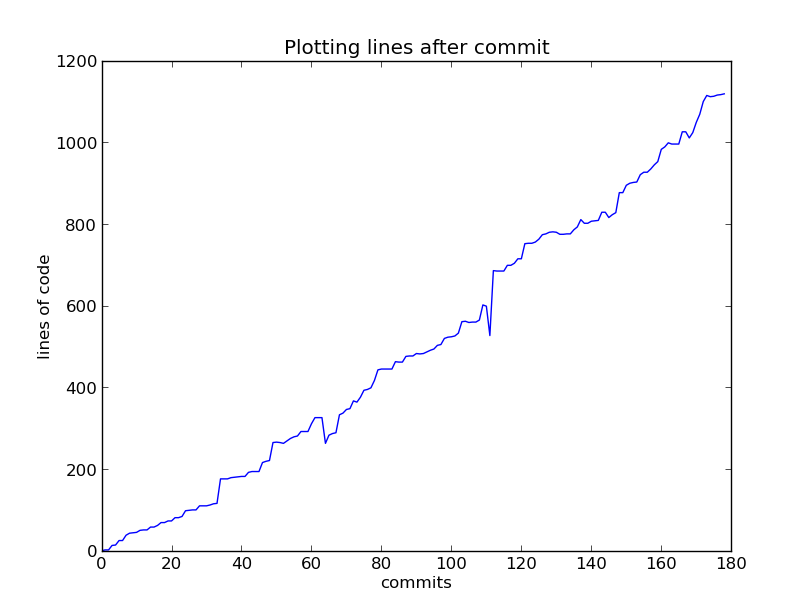
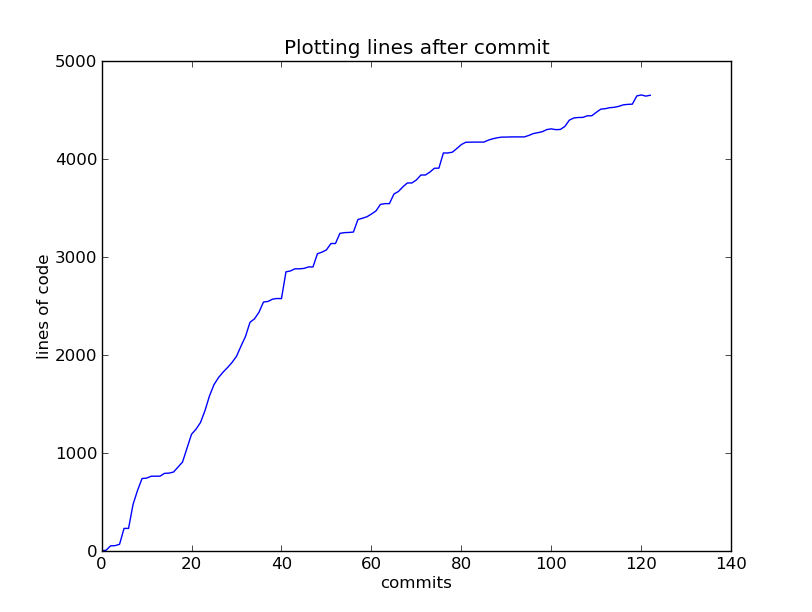
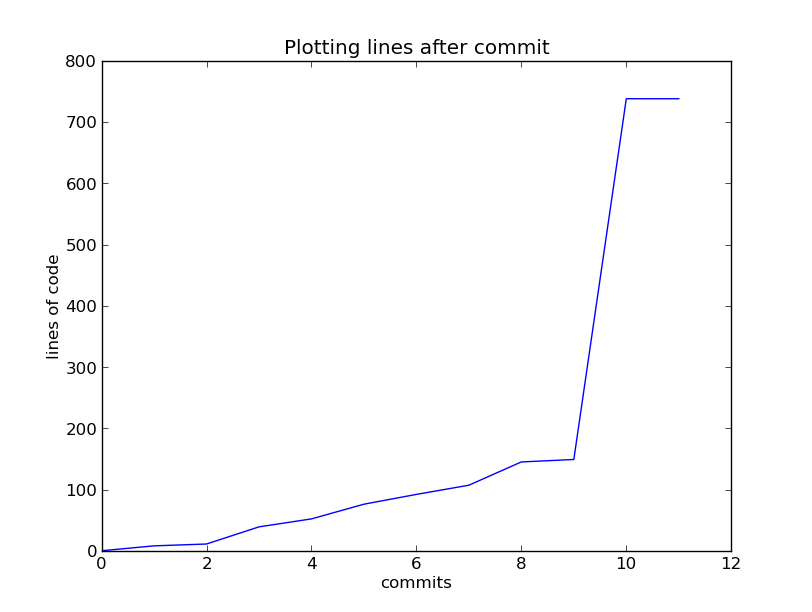
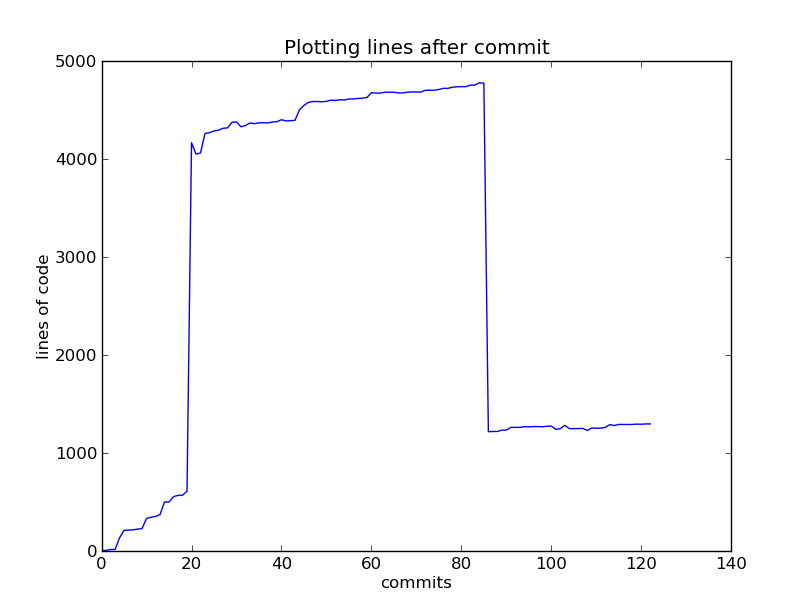
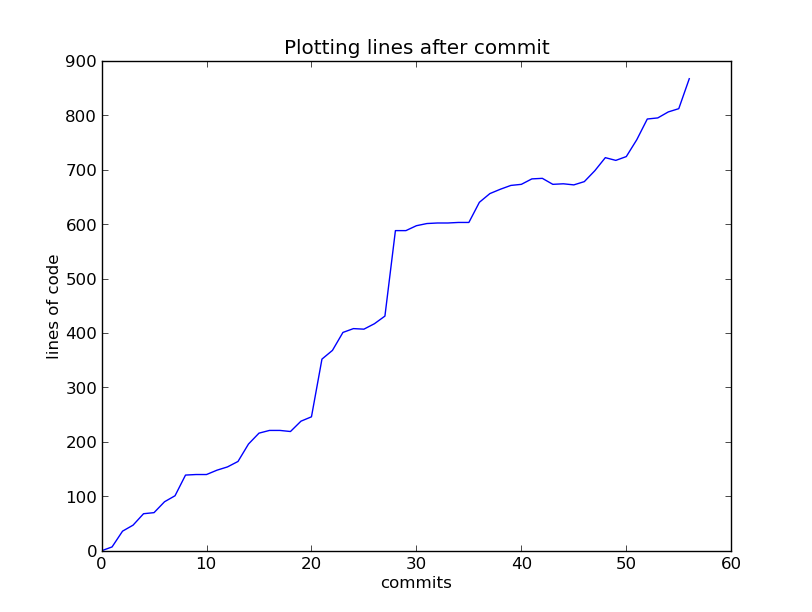
Git Lines
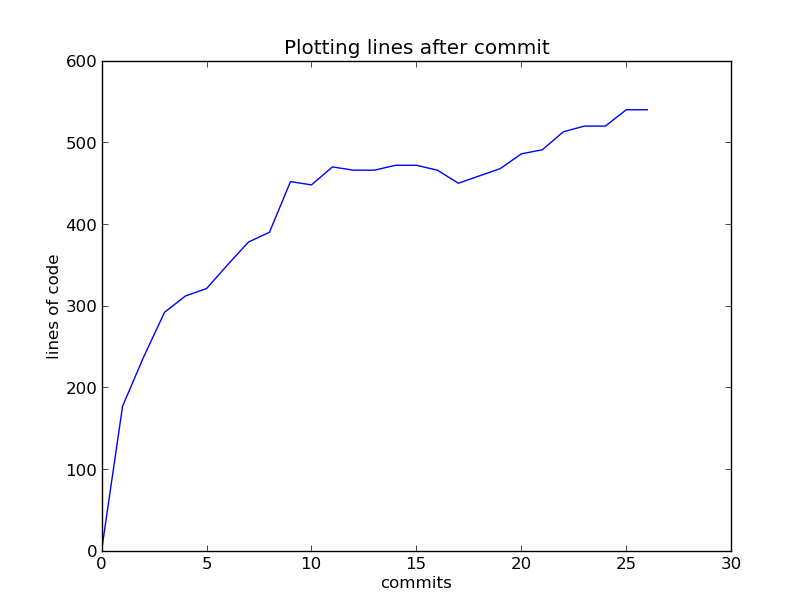
Git Lines
Other Software Development Tools
- Source code control is just one of many development tools:
- Issue Tracking Software
- Profilers
- Debuggers
- Testing frameworks
- Static Analysers
- Automatic Documentation Generators
- IDEs/Good Editors with plug-ins
Square Wheels
- All such tools have an initial investment of time to learn to use them
- But generally that investment of time is well worth it in the long run
Small/Large Projects
- As I stated at the start, you could easily do this project
without source code control
- You might not even utilise its backtracking features
- But building up the habit will be invaluable to you
when you do need it
- You will certainly need it for the system design project
External Git Advice
- There are literally millions of web pages offering git support and
advice
- Go forth and explore
Proposal: Word of Caution
- The
diff algorithm used by SCC is line based
- If you only take newlines for paragraphs you will cause larger than necessary diffs
- Programmer editor tend to implement a word-wrap feature that inserts a newline character
- Other editors just display the long-line on multiple lines but do not insert newline characters