MLPR → Course Notes → w8a
PDF of this page
Previous: Backpropagation of Derivatives
Next: Netflix Prize
$$\notag
\newcommand{\I}{\mathbb{I}}
\newcommand{\N}{\mathcal{N}}
\newcommand{\ba}{\mathbf{a}}
\newcommand{\bb}{\mathbf{b}}
\newcommand{\be}{\mathbf{e}}
\newcommand{\bff}{\mathbf{f}}
\newcommand{\bh}{\mathbf{h}}
\newcommand{\bm}{\mathbf{m}}
\newcommand{\bmu}{{\boldsymbol{\mu}}}
\newcommand{\bnu}{{\boldsymbol{\nu}}}
\newcommand{\bu}{\mathbf{u}}
\newcommand{\bx}{\mathbf{x}}
\newcommand{\g}{\,|\,}
\newcommand{\nth}{^{(n)}}
\newcommand{\te}{\!=\!}
\newcommand{\ttimes}{\!\times\!}
$$
Autoencoders and Principal Components Analysis (PCA)
One of the purposes of machine learning is to automatically learn how to use data, without writing code by hand. When we started the course with linear regression, we saw that we could represent complicated functions if we hand-engineered features (or basis functions). Those functions can then be turned into “neural networks”, where — given enough labelled data — we can learn the features that are useful for classification automatically.
For some data science tasks the amount of labelled data is small. In these situations it is useful to have pre-existing basis functions that were fitted as part of solving some other task. We can then fit a linear regression model on top of these basis functions. Or perhaps use the basis functions to initialize a neural network, and only train for a short time.
The basis functions could come from fitting another supervised task. For example, neural networks trained on the large ImageNet dataset are often used to initialize the training of image recognition models for tasks with only a few labels.
We may also wish to use completely unlabelled data, such as relevant but unannotated images, text or other data related to our task. Recently (2018–19), there has been an explosion of interest in Natural Language Processing in using pre-trained deep neural networks based on unlabelled data (see the Further Reading for papers).
Autoencoders solve an “unsupervised” task: find a representation of feature vectors, without any labels. This representation might be useful for other tasks. An autoencoder is a neural network representing a vector-valued function, which when fitted well, approximately returns its input: \[
\bff(\bx) \approx \bx.
\] If we were allowed to set up the network arbitrarily, this function is easy to represent. For example with a single “weight matrix”: \[
\bff(\bx) = W\bx, \quad \text{with}~W=\I,~\text{the identity}.
\] Constraints are required to find an interesting representation that might be useful.
Dimensionality reduction: One possible constraint is to form a “bottleneck”. We use a neural network with a narrow hidden layer with \(K\ll D\) units: \[\begin{align}
\bh &= g^{(1)}(W^{(1)}\bx + \bb^{(1)})\\
\bff &= g^{(2)}(W^{(2)}\bh + \bb^{(2)}),
\end{align}\] where \(W^{(1)}\) is a \(K\ttimes D\) weight matrix, and the \(g\)’s are element-wise functions. If the function output manages to closely match its inputs, then we have a good lossy compressor. The network can compress \(D\) numbers down into \(K\) numbers, and then decodes them again, approximately reconstructing the original input.
One application of dimensionality reduction is visualization. When \(K\te2\) we can plot our transformed data as a 2-dimensional scatter-plot.
When an autoencoder works well, the transformed values \(\bh\) contain most of the information from the original input. We should therefore be able to use these transformed vectors as input to a classifier instead of our original data. It might then be possible to fit a classifier on smaller inputs using less labelled data. Transforming our data with no additional input from the outside world can’t add information to our vectors, an observation known as the “data processing inequality”.
Denoising and sparse autoencoders: Fitting an autoencoder with a high-dimensional hidden layer gives features that are easier to separate with a linear classifier. A regularization strategy that enables setting \(K\!\ge\!D\) is the denoising autoencoder: randomly set some of the features in the input to zero, but try to reconstruct the original uncorrupted vector. Then if \(K\te D\) the best strategy is no longer for \(W^{(1)}\) to be the identity matrix. The hidden units should represent common conjunctions of multiple input features, so that missing features can be reconstructed. Alternatively, sparse autoencoders only allow a small fraction of the \(K\) hidden units to take on non-zero values. That limitation forces the network to represent the input vector as a linear combination of a small number of different “sources”. A large number, \(K\), of different sources are possible, but only a few can be used for each example.
A linear autoencoder sets the activation functions above to \(g^{(1)}(a) = g^{(2)}(a) = a\). It turns out that the best square error for a linear auto-encoder can still be obtained when re-writing the transformations in the restricted form: \[\begin{align}
\bh &= W^{(1)}\bx + \bb^{(1)} = V^\top(\bx -\bar{\bx})\\
\bff &= W^{(2)}\bh + \bb^{(2)} = V\bh + \bar{\bx}.
\end{align}\] The first step centres the input by subtracting the mean \(\bar{\bx} = \frac{1}{N} \sum_n \bx\nth\), and then transforms to a \(K\)-dimensional `hidden’ representation using a \(D\ttimes K\) matrix \(V\). The second step transforms back up to the high \(D\)-dimensional space, and re-centres the points around the mean. The parameters in the two transformations are shared, which turns out not to be a limitation.
The method of Principal Components Analysis (PCA) identifies a matrix \(V\), which if used in the above autoencoder achieves the best possible square error. There are three advantages over fitting the autoencoder with gradient methods: 1) The solutions for different hidden layer sizes \(K\) are nested: for a given input vector, the extracted feature \(h_1\) is the same in the solutions for all \(K\), \(h_2\) is the same for all \(K\!\ge\!2\), and so on. 2) This constraint makes the solution unique, so we fit the same parameters every time. 3) The parameters can be found using standard linear algebra operations.
We compute the covariance matrix of the points \(\Sigma = \frac{1}{N}\sum_n (\bx\nth-\bar{\bx})(\bx\nth-\bar{\bx})^\top\). Recalling the material on multivariate Gaussians, the covariance can be used to describe an ellipsoidal ball that summarizes how the data is spread in space. Some axes of the ellipsoid are often very short, and the data is “squashed” into a ball that only significantly extends in some directions. The eigenvectors of the covariance matrix point along the axes of the ellipsoid, and the longest axes are the eigenvectors with the largest eigenvalues. (You can take this statement on trust, or work through Q4b of tutorial 2 again.)
PCA measures the displacement of a data-point from the mean \(\bar{\bx}\) along the \(K\) most elongated axes of the ellipsoid. To do that, it sets the columns of the transformation matrix \(V\) to the \(K\) eigenvectors of the covariance matrix associated with the largest \(K\) eigenvalues.
Example Matlab/Octave code:
% Find top K principal directions:
[V, E] = eig(cov(X, 0));
[E, id] = sort(diag(E), 1, 'descend');
V = V(:, id(1:K)); % DxK
x_bar = mean(X, 1);
% Transform down to K-dims:
X_kdim = (X - x_bar) * V; % NxK
% Transform back to D-dims:
X_proj = (X_kdim * V') + x_bar; % NxD
Example Python code:
# Find top K principal directions:
E, V = np.linalg.eig(np.cov(X.T))
id = np.argsort(E)[::-1]
V = V[:, id[:K]] # (D,K)
x_bar = np.mean(X, 0)
# Transform down to K-dims:
X_kdim = np.dot(X - x_bar, V) # (N,K)
# Transform back to D-dims:
X_proj = np.dot(X_kdim, V.T) + x_bar # (N,D)
An illustration for \(D\te2\) and \(K\te1\) is below (the red line is V[:,0] in Python):
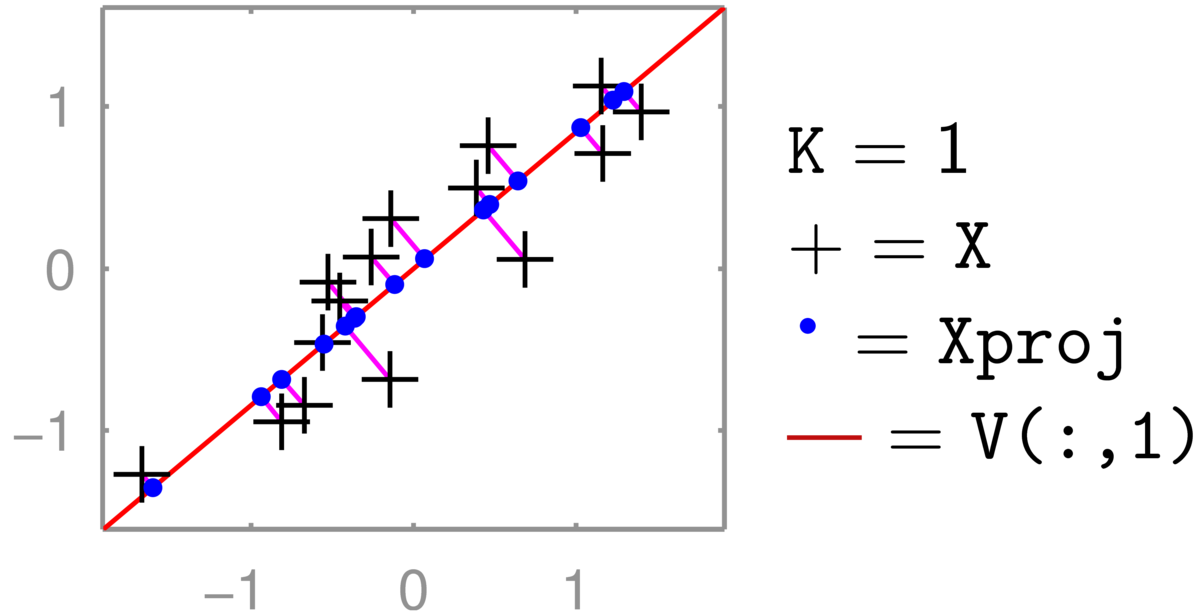
The two-dimensional coordinate of each \(+\)’s is reduced to one number, giving the position along the red line that it has been projected onto (the principal component). Transforming back up to two dimensions gives the coordinates of the \(\bullet\)’s in the full 2-dimensional space. These projected points (for zero-mean data \(XVV^\top\)) are constrained to lie along a one-dimensional line. (See also the related discussion in Q5 of the background material self-test.) The position along the second principal axis has been lost.
The eigenvectors of a covariance matrix are orthogonal, so if all the dimensions are kept, that is \(K\te D\), then \(VV^\top = \I\), and no information is lost.
We can replace a feature vector \(\bx\) with a linear transformation \(A\bx\) in any model. The transformation \(A\) could even be generated at random (no fitting, so no risk of overfitting!). Alternatively the transformation could be seen as \(K\ttimes D\) extra parameters, and fitted as part of the model (like in a neural network). PCA is a way to fit a sensible transformation, but without fitting (and possibly overfitting) to a specific task.
PCA is widely used, across many different types of data. It can give a quick first visualization of a dataset, or reduce the number of dimensions of a data matrix if overfitting or computational cost are concerns.
An example where we expect data to be largely controlled by a few numbers is body shape. The location of a point on a triangular mesh representing a human body is strongly constrained by the surrounding mesh-points, and could be accurately predicted with linear regression. PCA describes the principal ways in which variables can jointly change when moving away from the mean object. The principal components are often interpretable, and can be animated. Starting at a mean body mesh, one can move along each of the principal components, showing taller/shorter people, and then thinner/fatter people. The later principal components will correspond to more subtle, less interpretable combinations of features that covary.
A striking PCA visualization was obtained by reducing the dimensionality of \(\approx 200,000\) features of people’s DNA to two dimensions (Novembre et al., 2008). The coordinates along the two principal axes closely correspond to a map of Europe showing where the people came from(!). The people were carefully chosen.
As is often the case with useful algorithms, we can choose how to put our data into them, and solve different tasks with the same code. Given an \(N\ttimes D\) matrix, we can run PCA to visualize the \(N\) rows. Or we can transpose the matrix and instead visualize the \(D\) columns. As an example, I took a binary \(S\ttimes C\) matrix \(M\) relating students and courses. \(M_{sc} \te 1\), if student \(s\) was taking course \(c\). In terms of these features, each course is a length-\(S\) vector, or each student is a length-\(C\) vector. We can reduce either of these sets of vectors to 2-dimensions and visualize them.
The 2D scatter plot of courses was somewhat interpretable:
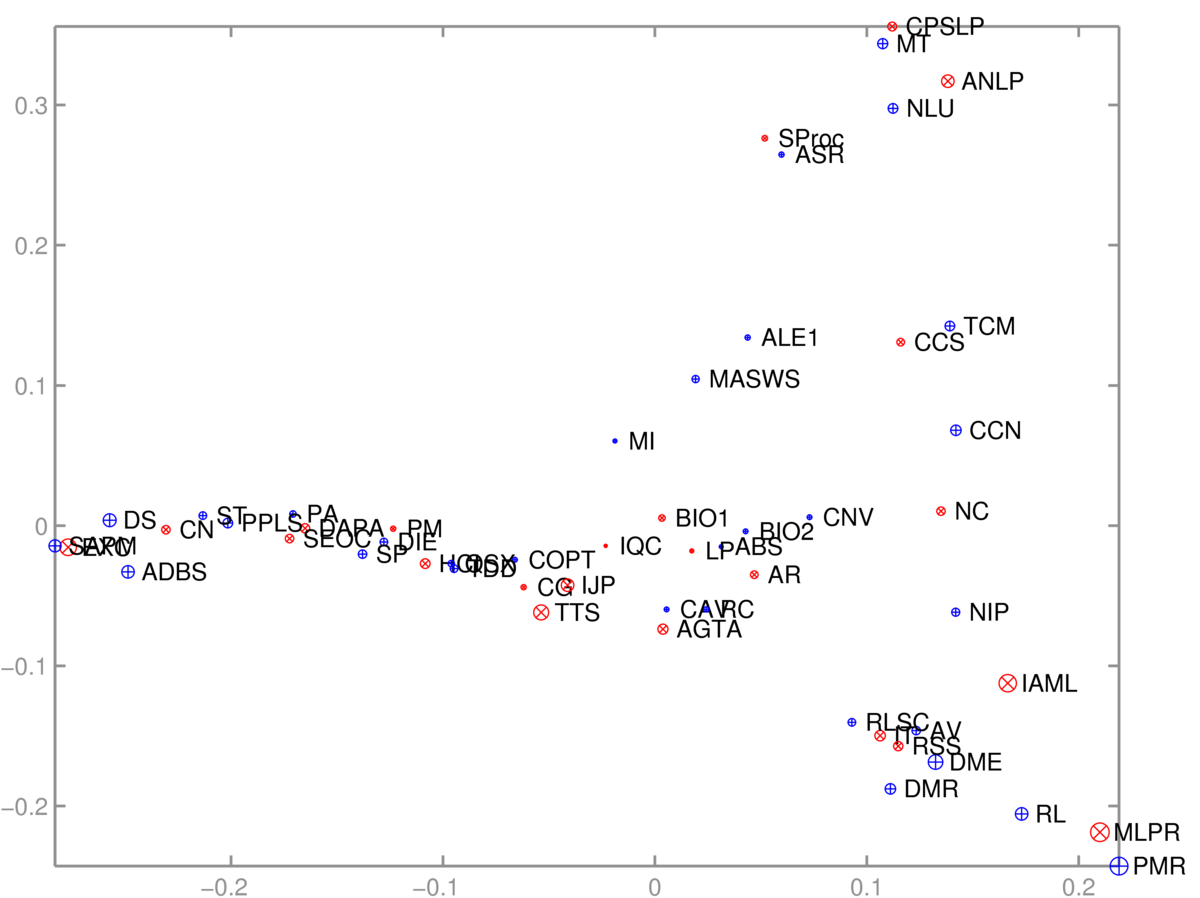
One axis (roughly) goes from computer-based applications of Informatics, through theory to broader applications. The other goes from cognitive/language applications down to machine learning. The algorithm had no labels, just which courses are taken together.
A scatter plot of students was less interpretable. I didn’t find obvious groups corresponding to the topics (suggested groups of courses) in the Informatics MSc handbook:
Finally, PCA doesn’t always work well. One of the papers that helped convince people that it was feasible to fit deep neural networks showed impressive results with non-linear deep autoencoders in cases where PCA worked poorly: Reducing the dimensionality of data with neural networks, Hinton and Salakhutdinov (2006). Science, Vol. 313. no. 5786, pp504–507, 28 July 2006. Available from http://www.cs.utoronto.ca/~hinton/papers.html
The units that data are measured in affects the principal components. Given age, weights, and heights of people, it matters if their height is measured in centimeters or meters. The numbers are 100 times bigger if we use centimeters, making the square error for an equivalent mistake in reconstructing height 10,000 times bigger. Therefore, if we use centimeters the principal component will be more aligned with height to reduce overall square error than if we use meters. To give each feature similar importance, it’s common to standardize all features so they have unit standard deviation: but the best scaling could depend on the application.
Given DNA data, \(x_d \in \{\mathtt{A},\mathtt{C},\mathtt{G},\mathtt{T}\}\), we have to decide how to encode categorical data. We could use one-hot encoding. In the example above, Novembre et al. used a lossy binary encoding indicating if the subject had the most common letter or not.
As usual, given positive data, we may wish to take logarithms. There are lots of free choices in data analysis.
The truncated SVD view of PCA reflects the symmetry noted in the MSc course data example above: we can find a low-dimensional vector representing either the rows or columns of a matrix. SVD finds both at once.
The truncated Singular Value Decomposition (SVD) is a standard technique, available in most linear algebra packages. It approximates an \(N\ttimes D\) matrix as a product of three matrices, \[
X \approx U S V^\top,
\] where \(U\) has size \(N\ttimes K\), \(S\) is a diagonal \(K\ttimes K\) matrix, and \(V^\top\) has size \(K\ttimes D\). The columns of the \(V\) matrix (or the rows of \(V^\top\)) contain eigenvectors of \(X^\top X\). The columns of \(U\) contain eigenvectors of \(XX^\top\). The rows of \(U\) give a \(K\)-dimensional embedding of the rows of \(X\). The columns of \(V^\top\) (or the rows of \(V\)) give a \(K\)-dimensional embedding of the columns of \(X\).
When \(K \te \min(N, D)\), SVD exactly reconstructs the matrix. For smaller \(K\), truncated SVD is known to be the best low-rank approximation of a matrix, as measured by square error.
When applied to centred data (the mean feature vector has been subtracted from every row of \(X\), so that \(\sum_n X_{nd} \te 0\) for each feature \(d\)), SVD gives the same solution as PCA. The \(V\) matrix contains the eigenvectors of the covariance (\(\Sigma = \frac{1}{N}X^\top X\), where the \(1/N\) scaling makes no difference to the directions). The \(U\) matrix contains the eigenvectors of the covariance if we were to transpose our data matrix before applying PCA.
Matlab/Octave demo:
% PCA via SVD, for NxD matrix X
x_bar = mean(X, 1);
[U, S, V] = svd(X - x_bar, 0); % Apply SVD to centred data
U = U(:, 1:K); % NxK "datapoints" transformed into K-dims
S = S(1:K, 1:K);
V = V(:, 1:K); % DxK "features" transformed into K-dims
X_kdim = U * S;
X_proj = (X_kdim * V') + x_bar; % SVD approx U*S*V' + mean
Python demo:
# PCA via SVD, for NxD matrix X
x_bar = np.mean(X, 0)
[U, vecS, VT] = np.linalg.svd(X - x_bar, 0) # Apply SVD to centred data
U = U[:, :K] # NxK "datapoints" transformed into K-dims
vecS = vecS[:K] # The diagonal elements of diagonal matrix S, in a vector
V = VT[:K, :].T # DxK "features" transformed into K-dims
X_kdim = U * vecS # = np.dot(U, np.diag(vecS))
X_proj = np.dot(X_kdim, V.T) + x_bar # SVD approx USV' + mean
The simplest probabilistic model of \(D\)-dimensional feature vectors \(\bx\) that lie on a low-dimensional manifold, is to assume they’re Gaussian. The model assumes that a \(K\)-dimensional Gaussian variable was generated, \(\bnu \sim \N(\mathbf{0},\I_K)\), and then transformed up into \(D\)-dimensions, \(\bx = W\bnu + \bmu\), where \(W\) is a \(D\ttimes K\) matrix. Under this model, \(\bx \sim \N(\bmu,\, WW^\top)\). The covariance is low rank, rank \(K\), because it only has \(K\) independent rows or columns. By the construction, all vectors \(\bx\) generated from this model will lie exactly on a linear subspace of dimension \(K\).
A Gaussian with low-rank covariance isn’t able to explain real-world data, which won’t lie exactly on a linear subspace. Specifically the likelihood of such a model will be zero if any data-points lie outside the \(K\)-dimensional subspace. We can explain such deviations by assuming that spherical noise was added to the points from the model of the previous paragraph: \(\bx \sim \N(\bmu,\, WW^\top \!+ \sigma^2\I)\). This is the probabilistic PCA (PPCA) model. In the limit as \(\sigma^2\rightarrow 0\) the low-dimensional explanations of the data will be the same as PCA. But a more sensible model will result by setting non-zero \(\sigma^2\). PPCA is a special case of probabilistic Factor Analysis, which sets the noise to be an arbitrary diagonal covariance matrix.
You will use this material on Q2 and Q3 of Tutorial 5, and briefly in the second assignment.
I train an auto-encoder on a large collection of varied images. You have a small collection of labelled images for a specialized application. Describe how and why my auto-encoder might be useful in building a classifier for your application.
Show from a definition of covariance that an element of the empirical covariance matrix \(\Sigma_{ij}\) is given by \(\big(\frac{1}{N}X^\top X\big)_{ij}\) for an \(N\ttimes D\) design matrix \(X\) that has been centred.
What choices would you consider if you were creating an autoencoder to model binary feature vectors?
We’re not going to ask you to prove things about eigenvectors, or the relationships between eigendecompositions and SVD, or other deep technical details relating to PCA on the exam.
You should know how PCA can be done, because it’s useful. You should also be able to discuss why it may be better or worse than other dimensionality reduction or feature extraction methods you’re asked to consider. Multivariate Gaussians come up a lot in this course, so thinking about PPCA and Factor Analysis may be useful. Again you don’t need to memorize equations, but you could be given the details and then asked about them, just as with other Gaussian models we will cover.
PCA and autoencoders find representations of your original input features. It may be easier to represent and/or learn a function based on features pre-processed with PCA or an autoencoder. However, these are operations done entirely inside your computer, after gathering data. As a reminder, you cannot “add information” about the world by processing your data, on the contrary, you can only lose information.
Bishop covers PCA in Chapter 12.
Murphy’s treatment of PCA: Section 12.2.1 p387–389, and Section 12.2.3 pp392–395.
Barber’s treatment starts in Section 15.2.
There are many online tutorials about PCA, with different levels of detail. The one by Alex Williams looks good.
Goodfellow et al.’s Deep Learning Textbook has much more on autoencoders in Chapter 14.
There are also non-parametric dimensionality reduction methods for visualization, such as t-SNE. These place each data-point at an arbitrary location on a scatter plot, by minimizing a cost function. The cost function says it is good if some properties of the scatter plot match the original high-dimensional data. For example, it is good to approximately preserve the relative distances between points, especially between nearby-points. There are examples where t-SNE gives far better visualizations than PCA does. I’ve also recently (2018) enjoyed using UMAP. However, in other applications (like the MSc data above) the best method of several I tried was simple linear PCA.
We can modify a denoising autoencoder to only compute the loss on the predictions of features that were masked out. It’s possible to turn such a network into a probabilistic model \(P(\bx)\) of the inputs. Such masked autoencoder objectives have also been used in BERT (Devlin et al., 2018), to pre-train representations of text for use in many other Natural Language Processing (NLP) tasks. BERT and its successors are causing big changes in NLP, including (October 2019) how Google search works.
Non-examinable!
In the past I’ve been asked: if \(X\) is a square symmetric matrix, doesn’t the SVD of \(X\) give me the eigenvectors of \(X\)? Yes it does. That’s potentially confusing because above I said that it gives the eigenvectors of \(XX^\top\) and \(X^\top X\). For a square symmetric matrix, the SVD therefore gives the eigenvectors of \(X^2\). These are in fact the same as the eigenvectors of \(X\), so there’s no contradiction.
\(X^2\) is the square function applied to the matrix \(X\). A way to apply a function to a square matrix is to decompose the matrix using its eigendecomposition \(X = U \Lambda U^{-1}\), apply the function to the diagonal elements of \(\Lambda\) (in this case square the values), and then put the matrix back together again. The eigenvectors don’t change! For a square symmetric matrix, the SVD and the eigendecomposition are the same thing.
It may interest you to know that other functions are applied to matrices in this way. For example the matrix exponential of a square matrix (expm in Matlab, scipy.linalg.expm in Python), equal to \(X+\frac{1}{2}X^2 + \frac{1}{3!}X^3 + \frac{1}{4!}X^4+\ldots\), can be computed by taking the eigendecomposition, exponentiating the eigenvalues, and putting the matrix back together again.
MLPR → Course Notes → w8a
PDF of this page
Previous: Backpropagation of Derivatives
Next: Netflix Prize
Notes by Iain Murray and Arno Onken