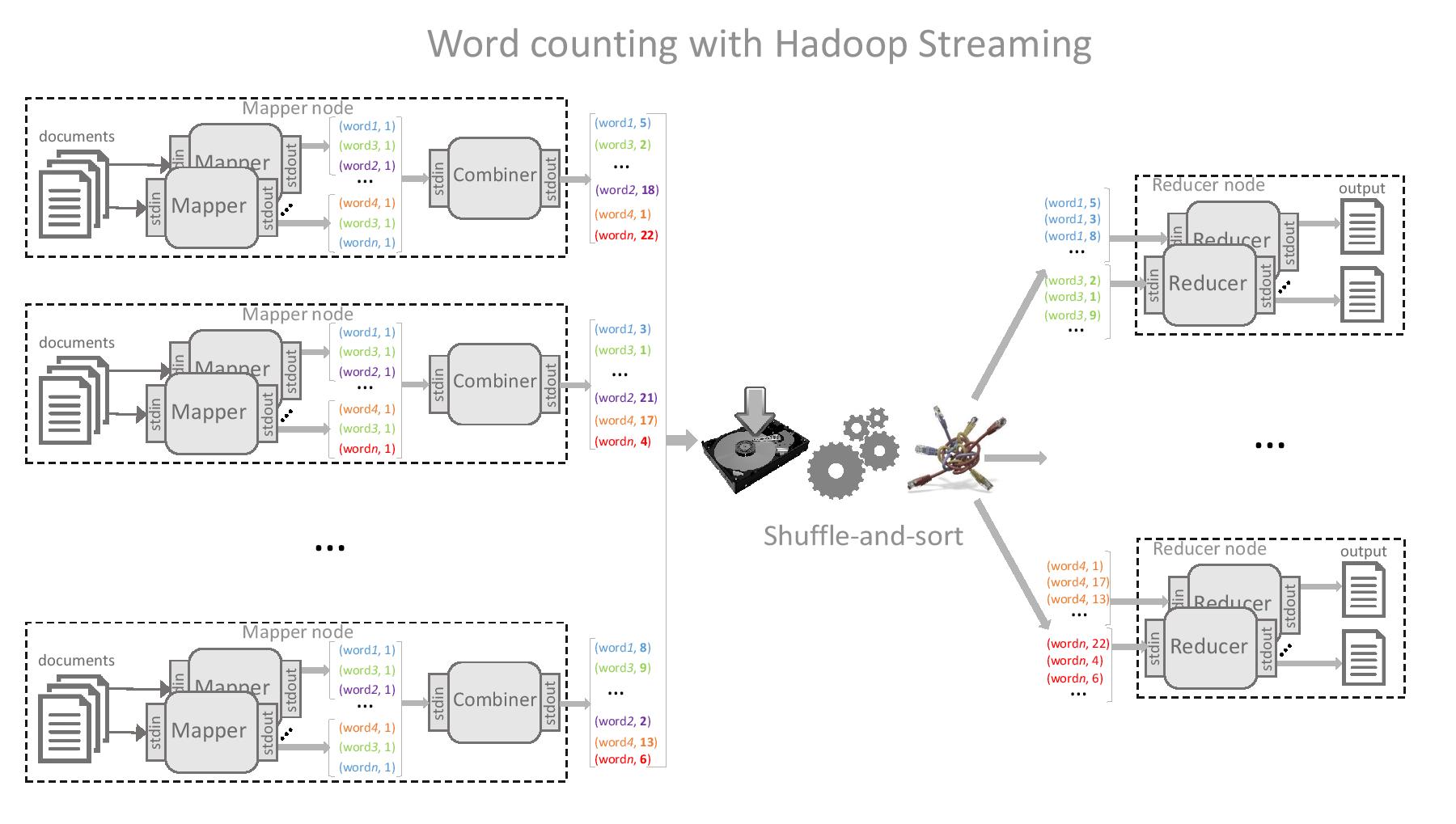
Supplementary Material - Designing a Solution using Hadoop Streaming
EXC 2019: Antonios Katsarakis, Chris Vasiladiotis, Dmitrii Ustiugov, Volker Seeker, Pramod Bhatotia
Based on previous material from Matt Pugh & Artemiy Margaritov
Introduction to MapReduce
MapReduce is a distributed data processing model proposed by Google for processing large amounts of data on computer clusters. MapReduce is well illustrated by the following picture (the image is taken from here):
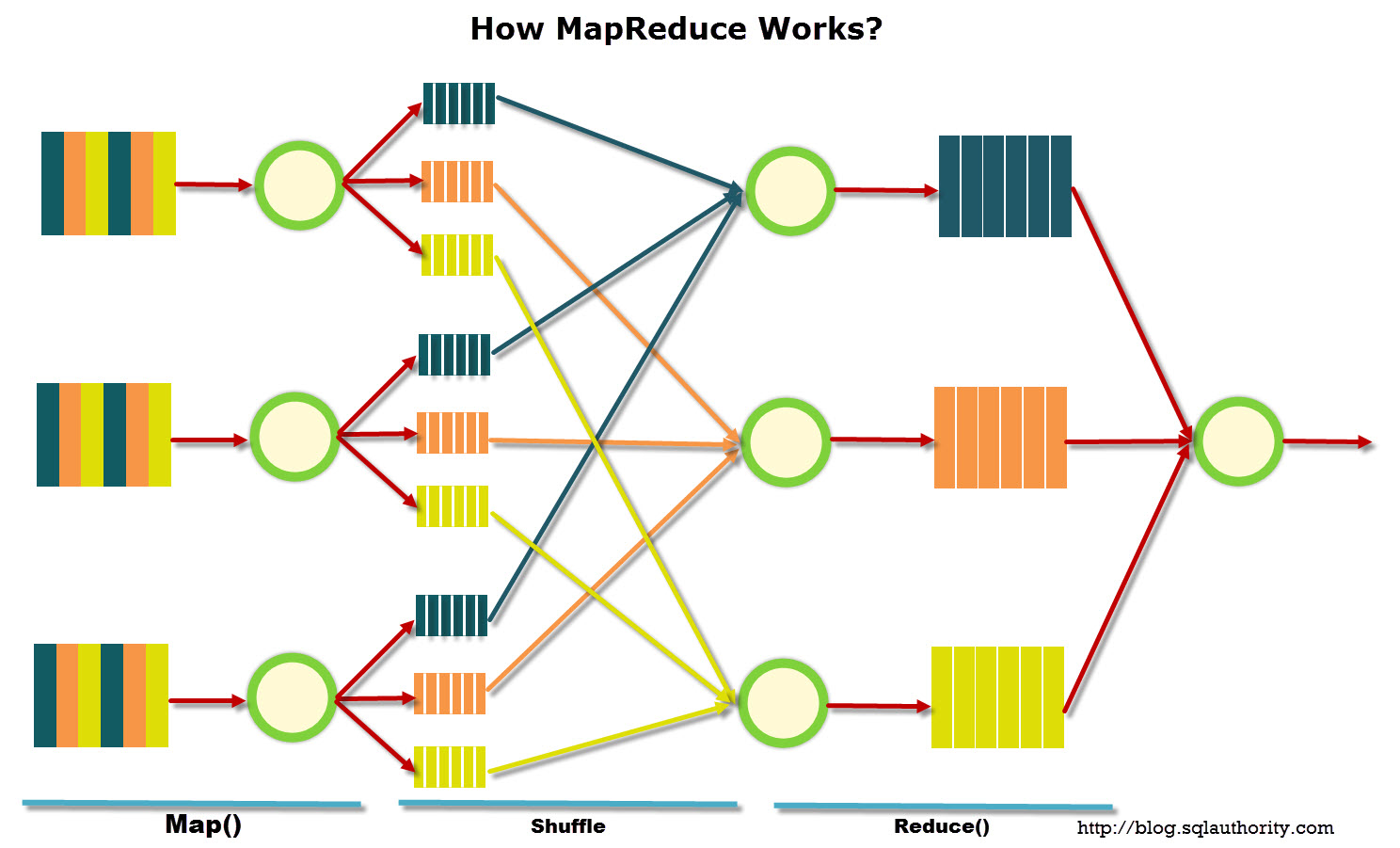
MapReduce data processing model assumes that the data is stored on several machines in a distributed manner and organized in the form of some records. Data processing takes place in 3 stages:
Map Stage. At this stage, the data is preprocessed using a map function which is defined by a user. The goal of the map stage is to preprocess and filter the data. The map function is applied to each input record one by one. As a result, the map function produces a set of key-value pairs for each input record. A set means that the map function can (1) not produce anything, or (2) can issue only one key-value pair, or (3) can give out several key-value pairs. A user defines what will be the keys and values produced by the map function. Key-value pairs with the same key will be processed by one instance of the reduce function later.
Shuffle stage. At this stage, all key-value pairs produced during the map stage are sorted by key and distributed across the machines in the cluster.
Reduce stage. The reduce function computes the final result for each group of key-value pairs with the same key. MapReduce model guarantees that key-value pairs with the same key are processed by the same reduce function. The set of all values returned by the reduce function is the final result of the MapReduce job. The reduce function is also set by user.
Let’s consider an example task – counting the number of words in the title of movies of our IMDB database
using the primaryTitle field (a string) in title.basics.tsv file under /data/supplementary/ in HDFS.
This table has the following format:
tconst\ttitleType\tprimaryTitle\toriginalTitle\tisAdult\tstartYear\tendYear\truntimeMinutes\tgenres
Notice that the field delimiter is the '\t' character.
The word counting task is the following:
given a set of title entries, find how many times a word is encountered in the primaryTitle of that set.
Assuming the set of titles is large, one can assume a title to be an input for one map function. Then, the map and reduce functions will be:
#!/usr/bin/python2.7
def map_function(title):
fields = title.strip().split('\t') # Split title to fields
primaryTitle = fields[2] # Select the required field
for word in primaryTitle.strip().split(): # Split primary title by words
yield word, 1 # Use a word as a key
def reduce_function(word, values):
yield word, sum(values) # Calculate how many times each word was encountered
The map function converts an input title into a set of pairs (word, 1). At the shuffle stage, the pairs are sorted based on the word. Finally, the reduce function sums the units at the value position of these pairs, returning the final answer for each word.
Important facts about MapReduce:
- All instances of the map function work independently and can work in parallel, including working on different machines of the cluster.
- All instances of the reduce function work independently and can work in parallel, including on different machines of the cluster.
- Shuffle stage represents a parallel sort, so Shuffle can also work on different cluster machines.
- The map function is often used on a machine where the data is stored. This allows reducing data transmission over the network.
- MapReduce job is always a full scan of all the data; there are no indexes or partial reads.
MapReduce programs with Hadoop Streaming
Introduction to Streaming Jobs
The simplest way to launch a MapReduce job on Hadoop is to use Hadoop Streaming interface. Hadoop Streaming interface assumes that map and reduce functions are implemented as programs which accept data from stdin and write the result to stdout.
Understanding how
stdinandstdoutare used in Python is key to using the Hadoop Streaming API, make sure you are comfortable with these concepts before proceeding. You can learn more about standards streams on wikipedia.
The program that executes the map function is called a mapper. The program that executes the reduce function is called, respectively, a reducer.
Lines from the stdout of the mapper process are converted into
key/value pairs by splitting them on the first tab character
('\t', which is the default splitting character but can be changed). The key/value pairs are fed to the stdin of the combiner (will be explained later) and/or reducer which further process them. Finally, the reducer writes to stdout which is the final output of the program. Everything will become much clearer through examples later.
IMPORTANT NOTE: for Hadoop to know how to properly run your Python scripts, you must include the following line as the first line in all your mappers, combiners, and reducers:
#!/usr/bin/python2.7
Mapper
Let’s implement a mapper for the word counting task using Hadoop Streaming interface.
Hadoop Streaming interface assumes that one line taken from stdin corresponds to one input record. Thus, the map function is called once for each line. Consequently, in order to implement a mapper for the Hadoop Streaming interface, one needs to call a map function for each line of the input. In our example task – word counting – each title is represented as one line of the input to a mapper.
With Hadoop Streaming, the mapper should emit key-value pairs by sending them to stdout.
Sending key-value pairs to stdout is just printing.
Note that a delimiter (note that '\t' is the default delimiter, but we use | in all our examples)
should be used between key and value for correct processing of a key-value pair during the shuffle stage.
The implementation of the mapper for the word counting task described above with Hadoop Streaming is this:
#!/usr/bin/python2.7
# mapper.py
import sys
def map_function(title):
fields = title.strip().split('\t') # Split title to fields using the data delimeter
primaryTitle = fields[2] # Select the required field
for word in primaryTitle.strip().split(): # Split primary title by words
yield word, 1 # Use a word as a key
for line in sys.stdin:
# Call map_function for each line in the input
for key, value in map_function(line):
# Emit key-value pairs using '|' as a delimeter
print(key + "|" + str(value))
Important facts about the mapper
- Using Hadoop Streaming, a mapper reads from
stdinand writes tostdout - Keys and values are delimited by
'|'(however, note that the default delimiter is'\t') - Records are split using newlines
Reducer
The output of a mapper is sorted in the shuffle stage and is grouped by key. The resulting set of key-value pairs goes to reducer’s stdin with one key-value pair per line. All the pairs corresponding to one key:
- guaranteed to be received and processed by the same reducer instance (MapReduce guarantee)
- sent to the input of a reducer sequentially (if one reducer will be selected to process several different keys, its input will be grouped by key).
For the word counting task, the output of the mapper is grouped by word. As a result, each reducer will receive all key-value pairs corresponding to the same word. Only after all the key-value pairs for this word are received, the reducer can start receiving key-value pairs for another word. Consequently, a reducer needs to track all the key-value pairs corresponding to the same word and accumulate the values of all of them. If a key-value pair for next word is received, it means that the previous word has been processed and the sum of the accumulated values is the final result for the previous word. The reducer outputs the word with the sum of accumulated values as a key-value pair. The reducer outputs to stdout by printing, similarly to the mapper. The implementation of the reducer for word counting task with Hadoop Streaming is below:
#!/usr/bin/python2.7
# reducer.py
import sys
def reduce_function(word, values):
# Calculate how many times each word was encountered
return word, sum(values)
prev_key = None
values = []
for line in sys.stdin:
# Parse key and value
key, value = line.strip().split('|')
# If key has changed then one can finish processing the previous key
if key != prev_key and prev_key is not None:
result_key, result_value = reduce_function(prev_key, values)
print(result_key + "|" + str(result_value))
values = []
prev_key = key
values.append(int(value))
# Don't forget about the last value!
if prev_key is not None:
result_key, result_value = reduce_function(prev_key, values)
print(result_key + "|" + str(result_value))
Efficiency
Combiner
During the shuffle stage, the result of the map stage is written to disk, sorted and then transmitted over the network to the machines where the reduce stage runs. As a result, if the size of the output of the map stage is large, the shuffle stage can be computationally difficult which can cause a significant delay. Such behaviour is not reasonable for tasks where the map and reduce functions are simple and do not incur long latency. For example, in the word counting task, map and reduce functions are computationally simple while mappers emit one key-value pair per word in a dataset which can be very large. One way to simplify the shuffle stage is to reduce the size of the output of the map stage by combining. Combining means “pre-reducing” the results of multiple mappers which run on the same machine. If a machine generates less output during the map stage, then less data goes to the shuffle stage. As a result, less data is written to disk, sorted and transferred over the network which can accelerate a MapReduce job. Enabling combining does not require a change in reducers. Indeed, with combining, the reducers will just receive partially reduced results which does not affect correctness.
To achieve this with Hadoop Streaming, one can define a combiner – a program that “pre-reduces” a part of mapper’s output generated by one machine. The combiner is very similar to the reducer – the combiner accepts the output of a few mappers and outputs a partially reduced result. For the word counting task, the combiner can be identical to the reducer. An important difference of a combiner from a reducer is that not all values corresponding to one key are sent to the same combiner. Note that Hadoop Streaming does not guarantee that the combiner will be executed at all for the output of the mapper. Therefore, the combining function is not always applicable (for example, in the case of calculating a median value by a key). Nevertheless, in those problems where the combining function is applicable, its use allows achieving a significant increase in the speed of execution of the MapReduce task.
For the word-counting task, we could simply reuse the reducer logic from above for making partial aggregation. The memory-efficient version of reducer provided below also can be used as a combiner.
In-Mapper Combiner
Another strategy – in-mapper Combiners – is designed to save time and reduce network traffic by doing some aggregation within the mapper itself using memory. With allocating an associative array, one can count words in mapper instead of emitting a lot of key-value pairs. In the case of the word count task, this would effectively mean storing a counter for each word in an associative array and emitting word-counter pair after finishing the processing. We must manage memory use though, so we can bound the size of the in-memory dictionary such that if it gets too large, we emit the key/value pairs. This will likely mean that the same key (word) with different values will be emitted many times. This is acceptable as we will scan a sorted list of incoming values in the reducer anyway, it acts as a trade-off - saving some network bandwidth whilst not capturing all elements before emitting the final values.
This would replace both the mapper.py and whichever combiner.py from above.
#!/usr/bin/python2.7
# mapper.py
import sys
from collections import defaultdict
word_dict = defaultdict(int)
MAX_SIZE = 100
def map_function(title):
fields = title.strip().split('\t') # Split title to fields
primaryTitle = fields[2] # Select the required field
for word in primaryTitle.strip().split(): # Split primary title by words
yield word, 1 # Use a word as a key
for line in sys.stdin:
# Call the map_function for each line in the input
for key, value in map_function(line):
# Agregate value for a word locally
word_dict[key] += value
# To keep O(1) space, we bound the size of our memory footprint
if len(word_dict) > MAX_SIZE:
for key, value in word_dict.items():
print(key + "|" + str(value))
word_dict.clear()
# Emit leftover key-value pairs and use '|' as the delimiter
for key, value in word_dict.items():
print(key + "|" + str(value))
Space Complexity
Space complexity is a measure of the amount of working storage an algorithm needs. In other words, space complexity shows how much memory an algorithm needs in the worst case at any point of execution. In practice, programmers are concerned about how the required memory size grows with the size of the input. The dependency of required memory size from the size of the input is usually represented in big O notation. As a result, space complexity in big O notation describes the limiting behaviour of required memory size as a function of input size with input size tending toward infinity. For example, if an algorithm is said to have O(N) space complexity, it means that the algorithm needs linearly more memory if the size of its input grows linearly.
The programs which can work with constant memory size regardless of the input size are said to have O(1) space complexity. We will consider such programs memory-efficient.
Let’s analyse the efficiency of reducer implementation from the section Reducer. One can see that the list values is not limited in size and can use more memory with the size of the input data growing (assuming the worst case of input data with only one word repeated multiple times). This means that the reducer’s space complexity is not O(1). As a result, such an implementation is not memory-efficient implementation. To make a reducer more memory-efficient, one can replace an array with a counter and increment the counter when a key-value pair with the same key is processed. In practise, the counter memory requirements do not depend on the size of the input. As a result, this solution does not require more memory if the size of the input grows. Consequently, the reducer with a counter is more memory-efficient. Below we amend the reducer to make it more memory-efficient:
#!/usr/bin/python2.7
# memory-efficient_reducer.py
import sys
prev_word = None
value_total = 0
for line in sys.stdin: # For ever line in the input from stdin
line = line.strip() # Remove trailing characters
word, value = line.split("|", 1)
value = int(value)
# Remember that Hadoop sorts mapper output by key, and the reducer takes these keys sorted
if prev_word == word:
value_total += value
else:
if prev_word != None: # Write result to stdout
print(prev_word + "|" + str(value_total))
value_total = value
prev_word = word
if prev_word == word: # Don't forget the last key/value pair
print(prev_word + "|" + str(value_total))
Conclusion
In this lab, we studied the MapReduce concepts and the Hadoop Streaming infrastructure. The picture below shows how the word counting task is performed with Hadoop Streaming. In the next lab – Hadoop Streaming using Python – you will learn how to launch a MapReduce job with Hadoop Streaming.