Computer Science
Large Practical
Introduction
Paul Patras
Housekeeping
- Web: http://www.inf.ed.ac.uk/teaching/courses/cslp/
- One lecture per week
- When: Fridays, 12:10–13:00
- Where: Old Infirmary (Geography) building - Map Room 2.19 (Old Library) – this may change!
- Please ask questions at any time
- Coursework accounts for 100% of your mark
- Office hours: flexible, but email me first (paul.patras@ed.ac.uk)
Restrictions (I)
- CSLP is a third-year undergraduate course only available to third-year undergraduate students.
- CSLP is not available to visiting undergraduate students, or to fourth-year undergraduate students and MSc students, who have their own individual projects.
Restrictions (II)
- Third-year undergraduate students should choose at most one
large practical, as allowed by their degree regulations.
- Computer Science,
Software Engineeringand Artificial Intelligence large practicals. - On most degrees a large practical is compulsory.
- On some degrees (typically combined Hons) you can do the System Design Project instead/additionally.
- Computer Science,
- See Degree Programme Tables (DPT) in the Degree Regulations and Programmes of Study (DRPS) for clarifications.
Clarifications
- SELP is not offered this year, due to a number of unforeseeable circumstances.
- The School of Informatics apologises for this, and has put an important concession in place (I will come back to this shortly).
- Still, you will make extensive use of skills in the engineering of software through the CSLP.
About this course
- So far most of your practicals have been small exercises
- This practical is larger and less rigidly defined than previous course works.
- The CSLP tries to prepare you for
- The System Design Project (in the second semester);
- The Individual Project (in fourth year).
Requirements
- There is:
- a set of requirements (rather than a specification);
- a design element to the course; and
- more scope for creativity.
- The requirements are more realistic than most coursework,
- But still a little contrived in order to allow for grading.
How much time should I spend?
- 100 hours, all in Semester 1, of which
- 8 hours lecture/demonstrating,
- 92 hours practical work.
How much time is that really?
- 12 weeks remaining in semester 1 (Weeks 2 to 13).
- 7.5 * 12 = 90 hours.
- You can think of it as 7.5 hours/week in the first semester.
- This could be one hour a day including weekends.
- You could work 7.5 hours in a single day,
- for example work 9:00-17:30 with an hour for lunch.
Managing your time
It is unlikely that you will want to arrange your work on your large practical as one day where you do nothing else, but one day per week all semester is the amount of work that you should do for the course.
Course lecturers have been asked not to let deadlines overlap Weeks 11-13 because students are expected to be concentrating on their large practical in that time.
Deadlines
The Computer Science Large Practical has two parts:
- Part 1
- Deadline: Thursday 22nd October, 2015 at 16:00
- Part 1 is zero-weighted: it is just for feedback.
- Part 2
- Deadline:
Thursday 17th December
Monday 21st December, 2015 at 16:00 - Part 2 is worth 100% of the marks.
- Deadline:
Scheduling work
- It is not necessary to keep working on the project right up to the deadline.
- For example, if you are travelling home for Christmas you might wish to submit the project early.
- In this case ensure that you start the project early.
- The coursework submission is electronic so it is
possible to submit remotely,
- But you must make sure that your submission works as expected on DiCE.
- This might be easier to do locally, but see working remotely and remote graphical login.
Early submission
Concession
- As compared to last year, work submitted less than a week before the deadline will not be capped at 90%.
- This year you will be benefiting from 1 week+ to work full time on the course after lectures have finished.
- This is incredibly rare in the current university calendar and especially valuable for projects!
Extensions
- Do not ask me for an extension as I cannot grant them.
- The correct place is the ITO who will pass this on to the year organiser (Vijay Nagrajan).
- See the policy on late coursework submission first.
The Computer Science Large Practical
The CSLP Requirement
- Create a command-line application in C.
- The purpose of the application is to implement a
stochastic, discrete-event, discrete time simulator
- (I'll come back to these terms).
- This will simulate an on-demand public transport system for future cities, with stop locations, minibus capacities, user behaviour, etc. specified by input.
The CSLP Requirement (C'tnd)
- The output will be the sequence of events that have been simulated, as well as some summary statistics.
- Input and output formats, and several other requirements are specified in the coursework handout.
- It is your responsibility to read the requirements carefully.
Why Simulators?
- Stochastic simulation is an important tool in physics, medicine, computer networking, logistics, and many other fields.
- Particularly useful to understand complicated processes.
- Can save time, money, effort and even lives.
- Allow running inexpensive experiments of exceptional circumstances that might otherwise be infeasible.
- However, the simulator must have an appropriate model for the real system under investigation, to produce meaningful results.
Example: preventing Internet outages
Source: Internet Census –World map of 24 hour relative average utilization of IPv4 addresses.
Last year CBC news reported that in the U.S. Verizon dumped 15,000 Internet destinations for ~10 minutes.
Preventing Internet outages
- Global Internet routing table has passed 512K routes.
- Older routers have limited size routing tables; when these fill up, new routes are discarded.
- Large portions of the Internet become unreachable, thus online businesses are loosing money.
- Upgrading equipment is expensive and takes time; workarounds are being proposed.
- Ensuring the proposed solutions will work is not trivial.
Preventing Internet Outages
- Testing patches in live networks poses the risk of further disruption.
- Waiting for the next surge is not acceptable.
- Forwarding all traffic for new routes through a default interface has serious implications on routing costs.
- With simulation it is possible to generate synthetic traffic and test patches without disrupting the network.
- It is also possible to evaluate different metrics, e.g. round-trip delays, throughput, propagation latency of routing changes.
Why C?
- Part of the challenge of this practical is to enhance your skills with a procedural language widely used for system programming.
- This is something you should expect when taking a job as a software developer in a company that has clear incentives to use a particular language.
- C is efficient (low execution time), portable, excellent for working directly with the hardware, and also usable for web programming.
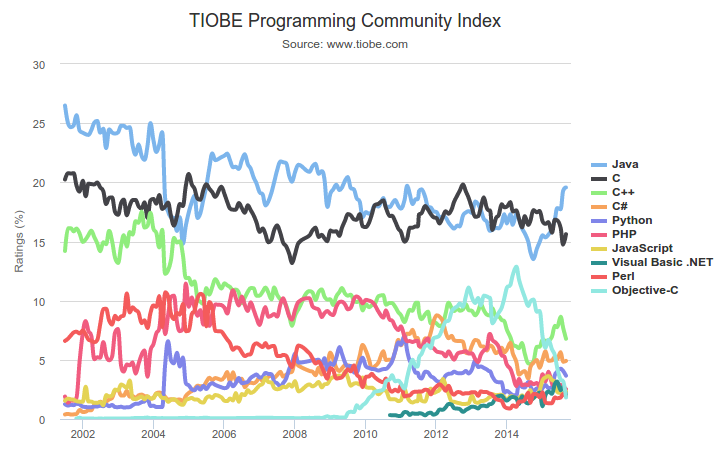
Why C?
- Currently ranked among the most popular programming languages --TIOBE Index, Sept. 2015.
Code Sharing
- Code sharing sites are a great resource but please refrain from using them for this practical.
- This is an individual practical so code sharing is not allowed. Even if you are not the one benefiting.
- It is somewhat likely that in the future you will be unable to publicly share the code you produce for your employer.
Why Simulate an On-demand Public Transport System?
- This approach is currently considered by European city councils as a potential major step towards eliminating the incentives for personal car ownership.
- Reduce carbon emissions in densely populated areas.
- Cut down commute times & improve user satisfaction.
- Limitations of current periodic scheduling practices:
- Buses make unnecessary frequent trips; sometimes take lengthy routes → increased operation costs.
- User demand varies geographically and in time → buses sometimes overcrowded.
Why Simulate an On-demand Public Transport System?
- With simulation we can investigate the impact of different service demand rate and acceptable pick-up delays to trigger scheduling.
- In this practical we will evaluate the efficiency of the transportation process in terms of bus occupancy per unit of travel time, average waiting times, etc.
- Short tolerable waiting times → journeys with fewer passengers; lesser efficiency.
- Longer waiting intervals → more cost efficient, but impacting user satisfaction.
Your Simulator
- Your simulator will be a command-line application.
- It will accept an input text file with the description of the serviced network and
- a set of global parameters: minibus capacity, boarding time, request arrival rate, departure delay, maximum waiting time.
- It should output information about occurring events.
- The strict formats for both input and output are described in the coursework handout.
- You will also need to produce summary statistics that you will later analyse.
Simulation Algorithm
The underlying simulation algorithm is fairly simple:
WHILE {time ≤ max time}
determine the set of events that may occur after the current state
delay ← choose a delay based on the nearest event
time ← time + delay
modify the state of the system based on the current event
ENDWHILE
Simulation Algorithm
WHILE {time ≤ max time}
...
delay ← choose a delay based on the nearest event
...
ENDWHILE
- Some events are deterministic, some occur with exponentially distributed delays.
- I'll explain this in more details, but for now drawing from an exponential distribution can be done by:
−(mean) ∗ log(random(0.0, 1.0))
- Where mean is the average delay, which is the reciprocal of the rate.
Components of the Simulation
Input - Global parameters
- Mini bus capacity
- Boarding/disembarking time
- Request rate
- Pick up interval
- Maximum admissible delay
- Number of buses
- Number of stops
- Matrix representation of the service network
Components of the Simulation
Stops
- Passengers only board or disembark at designated minibus stops.
- Consider users book journeys through e.g. a smartphone application and do not necessarily need to be present at a bus stop.
- New requests are 'queued' at bus stops.
- We are only interested in the back-end (thus will not develop a user app).
Components of the Simulation
Users
- We consider users place requests at exponentially distributed time intervals (with a given mean).
- Randomly choose departure and arrival stops.
- Chosen a desired boarding time that is an exponentially distributed delay after the request time (mean also given as an input parameter).
- Can tolerate a maximum delay after the desired departure time (also given as input).
Components of the Simulation
Minibuses
- Have fixed passenger capacity (given as input).
- Time to board/disembark a passenger is constant (and given as input).
- Scheduling and route calculation are things you have to decided on.
Components of the Simulation
Service network
- We consider a directed graph representation of the bus stop locations and the distances between them.
- The graph is given as an input in matrix form.
- The distances between any two locations are expressed in minutes.
Example
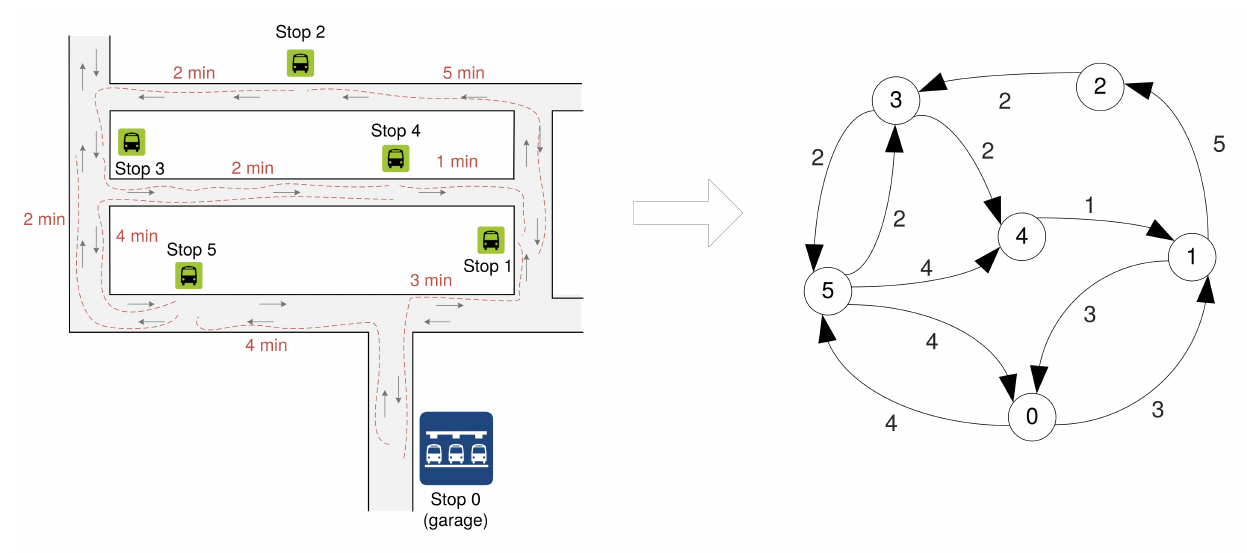
Example
- Matrix representation
map
0 3 -1 -1 -1 4
3 0 5 -1 -1 -1
-1 -1 0 2 -1 -1
-1 -1 -1 0 2 2
-1 1 -1 -1 0 -1
4 -1 -1 2 4 0
Components of the Simulation
Route planning
- The start of a minibus journey can be triggered with any delay.
- Routes of minibuses already in services can be modified as long as this will not alter previously agreed departures.
- Ensure capacity is not exceeded.
Components of the Simulation
Route planning
- Goal: Find the shortest routes that pick up and drop off the largest possible number of passengers that intend to take similar journeys.
- How you achieve this task is your design choice.
- This is a non-trivial problem, so exploring different heuristics is appropriate.
Components of the Simulation
Events
- Your simulator will produce a sequence of events
- New user places a request;
- Request is scheduled for departure at a time instant;
- Request cannot be accommodated;
- Minibus leaves/arrives at a location;
- A passenger boards / disembarks;
- Minibus occupancy changes.
Components of the Simulation
Events
- Your simulator will output a sequence of events in the following format:
‹time› -> new request placed at stop ‹unsigned int› for departure
at ‹time› scheduled for ‹time›
‹time› -> new request placed at stop ‹unsigned int› for departure
at ‹time› cannot be accommodated
‹time› -> minibus ‹unsigned int› arrived at stop ‹unsigned int›
‹time› -> minibus ‹unsigned int› left stop ‹unsigned int›
‹time› -> minibus ‹unsigned int› boarded passenger at
stop ‹unsigned int›
‹time› -> minibus ‹unsigned int› disembarked passenger at
stop ‹unsigned int›
‹time› -> minibus ‹unsigned int› occupancy became ‹unsigned int›
Components of the Simulation
Events
- Depending on the actual event in your simulation, you will replace the variables with real values, e.g.:
- This is valid output in the sense that it is formatted correctly, but may be invalid for semantic reasons.
00:01:20:00 -> new request placed at stop 2 for departure
at 00:01:32:00 scheduled for 00:01:33:00
00:01:25:10 -> new request placed at stop 3 for departure
at 00:01:34:00 scheduled for 00:01:36:00
00:01:28:00 -> minibus 1 left stop 1
00:01:33:00 -> minibus 1 arrived at stop 2
00:01:33:10 -> minibus 1 boarded passenger at stop 2
00:01:33:10 -> minibus 1 occupancy became 4
...
Important!
- Part of your code will be subject to automated testing.
- Strictly abiding to the input/output specification and command line formatting is mandatory.
- Your code may be functional, but you will lose points if it fails on automated tests.
- This is something you should expect with the evaluation of commercial products as well.
Part One & Part Two Assessments
- Part one, is just for feedback. You only need to have a working simulator
- For part two, there are additional requirements:
- Full functionality should be implemented.
- Summary statistics, such as trip efficiency, should be produced.
- Experimentation support, e.g. varying the fleet size to see how this impacts different metrics.
- Validation, checking that the input is valid.
Part One & Part Two Assessments
- These are all specified in the coursework handout, available at: http://www.inf.ed.ac.uk/teaching/courses/cslp/handout/cslp-2015-16.pdf
- This was a brief summary of the major components of the simulation.
- It is no substitute for reading the coursework handout.
- Try to submit an alpha version of your simulator for part 1; it carries zero weight, but will help you for part 2!
The Simulator
Definitions
- In the requirements I have stated that your simulator will be a:
- stochastic,
- discrete event,
- discrete time
- Let's see what each of these terms means.
Stochasticity
- A stochastic process is one whose state evolves “non-deterministically”, i.e. the next state is determined according to a probability distribution.
- This means a stochastic simulator may produce slightly different results when run repeatedly with the same input.
- Therefore it is appropriate to compute certain statistics to characterise the behaviour of the simulated system.
- Remember, these are statistics about the model:
- You hope that the real system exhibits behaviour with similar statistics.
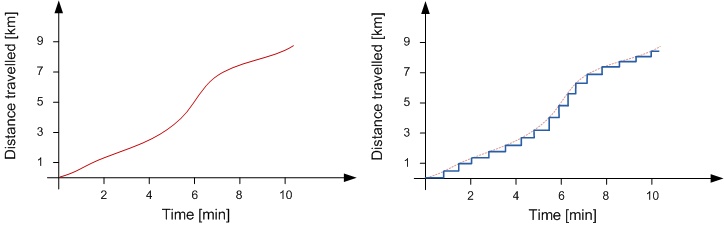
Discrete Events
- Discrete events happen at a particular time and mark a change of state in the system.
- This means discrete-event simulators do not track system dynamics continuously, i.e. an event either takes place or it does not.
- There is no fine-grained time slicing of the states, i.e.
- Generally a state could be encoded as an integer.
- Usually it is encoded as a set of integers, possibly coded as different data types.
- Discrete-event simulations run faster than continuous ones.
Discrete vs Continuous States
- When working with discrete events, it is common to consider that states are also discrete.
- Example:
Discrete Time
- Discrete time simulations operate with a discrete number of points:
- Seconds, Minutes, Hours, Days, etc.
- These can also be logical time points:
- Moves in a board game,
- Communications in a protocol.
- Your task is to write a discrete time simulator.
- Events will occur with second level granularity.
The Exponential Distribution
- Remember that the probability distribution gives the probability of the different possible values of a random variable.
- The exponential distribution describes the time between events in a Poisson process, i.e.
- Events' inter-arrival times are independent (memoryless),
- Events occur with a constant average rate λ.
The Exponential Distribution
- Roughly speaking, the time X we need to wait before an event occurs has an exponential distribution if the probability that the event occurs during a certain time interval is proportional to the length of that time interval.
- Applications:
- Call arrivals at a telephone exchange,
- Radioactive particle decay,
- Air plane arrivals at a large hub.
The Exponential Distribution

- The probability density function (PDF) is given by:
- Describes the relative likelihood that an event with rate λ occurs at time x.
f(x,λ) = λe-λx, ∀ x > 0
The Exponential Distribution
- The probability density function (PDF) is given by:
- The integral of this gives the probability that it occurs within 2 time bounds (but you can largely ignore this).
f(x,λ) = λe-λx, ∀ x > 0
The Exponential Distribution

- The cumulative distribution function (CDF) is given by:
F(x,λ) = 1 - e-λx, ∀ x > 0
The Exponential Distribution
- So if something happens at a rate of 0.5 per unit of time, then the probability
that we will observe it occurring within 1 time unit is:
F(1, 0.5) = 1 - e0.5*1 = 0.393
The Exponential Distribution
- The mean or expected value is given by the reciprocal of the rate parameter.
- In plain English this means that if something occurs at rate r then we can expect to wait 1/r time units on average to see each occurrence.
- If something occurs 7 times per week, you can expect to wait 1/7 of a week (or a full 24 hours) on average between each occurrence.
Exercise
What is the probability that a random variable X is less than its expected value, if X has an exponential distribution with rate λ?
The expected value of an exponential random variable with parameter λ is:
E[X] = 1/λExercise
We need to compute P(X ≤ E[X]) using the distribution function:
P(X ≤ E[X]) = P(X ≤ 1/λ)
= F(x,λ)
= 1 - e -λ*1/λ
= 1 - 1/e
The Memoryless Property
- Formally: P(X > s + t | X > s) = P(X > t), ∀ s, t > 0
- Less formally: The time that we can expect to wait for the next occurrence of some (exponentially distributed) event, is unaffected by how long we have already been waiting for it.
- In the 7 times a week example, if it has been 24 hours since the last occurrence, the expected additional time I have to wait is still 24 hours.
The Memoryless Property
- A quick note, don't confuse these two properties:
- Correct P(X > 100 | X > 80) = P(X > 20)
- Incorrect P(X > 100 | X > 80) = P(X > 100)
The Memoryless Property
- In your simulation, users place new requests at exponentially distributed time intervals.
- That means the next request event does not depend on the previous ones.
- As a result of firing that event, the global state of the simulation changes.
- However local states may not have changed, e.g. a minibus may still be at a certain stop.
How do we sample from a distribution?
Inverse Transform Method
- Let X be a RV with continuous and increasing distribution function F. Denote the inverse by F −1.
- Let U be a random variable uniformly distributed on the unit interval (0, 1).
- Then X can be generated by X = F −1(U).
If we use an exponential CDF for F, then we effectively sample from that distribution by
X = -ln(U)/λSampling exponential distributions in practice
Straightforward, right? (denoting mean = 1/λ)
int r = (int) (-log(rand()/RAND_MAX)*mean);
Well... not quite...
- rand() is known to be implemented poorly.
- You want to draw a RV uniformly distributed on (0,1).
- Seeding properly a pseudo-random generator is tricky.
OK, so what should we do?
xkcd?

Drawing uniformly distributed random numbers
Use a uniform deviate and discard the zero.
double uniform_deviate ( int seed )
{
return seed * ( 1.0 / ( RAND_MAX + 1.0 ) );
}
....
int r;
do
r = uniform_deviate ( rand() );
while (r == 0);
r = (int) (-log(r)*mean);
Seeding rand()
The usual solution is to get the system time.
srand ( (unsigned int) time ( NULL ) );
Note there may be some portability issues with the above. Julienne Walker argues that hashing the system time first is a good solution. For a longer discussion about this and random numbers you can check his web page.
Further reading
- Donald E. Knuth (1998). The Art of Computer Programming, volume 2: Seminumerical Algorithms, 3rd Edition, Addison-Wesley.
- William H. Press et al. (2007). Numerical Recipes: The Art of Scientific Computing, 3rd Edition, Cambridge University Press.
Your Simulators
- Will be Discrete event simulators;
- Will be Discrete time simulators;
- Will make use of the exponential distribution to model user behaviour.
Clarifications
- Boarding time
- The first version of the coursework contained conflicting statements about the time to board/disembark a passenger. This parameter should be given in seconds –the coursework handout has been updated accordingly.
Clarifications
- Question:
- What file format should I expect for the input scripts?
- Answer:
- Input scripts will be given in plain text format (but not necessarily with a .txt extension).
Reminders
- Read the handout carefully. These slides are not a substitute.
- You are encouraged to submit an early version of your simulator for Part 1.
- This is not marked, but it gives you the chance to receive feedback which can help in completing Part 2.
Guest lecture announcement
- Dr George Hazel OBE will give a guest lecture in November (exact date TBC).
- Dr Hazel has extensive experience in all aspects of transport and communications.
- He is currently advising Scottish Enterprise on Smart Mobility as their Smart Mobility Network Integrator.
Simulation Components
Route Planning
Cisco International
Internship Programme
- If you have an interest in computer networks, this is an opportunity to spend 1 year (2016-17) in Silicon Valley.
- Cisco covers salary, housing, travel, etc.
- Application Deadline: 20 October, 2015 (5:00 PM EST).
- Details available at http://myciip.com/
Service Network
- We need an abstract representation of a street map and bus stop locations for the service network.
- We need to model the roads between different locations and the time required to travel these.
- We need to account for the fact that some streets only allow one way traffic.
Example
Leith Walk area in Edinburgh; 20 imagined stop locations
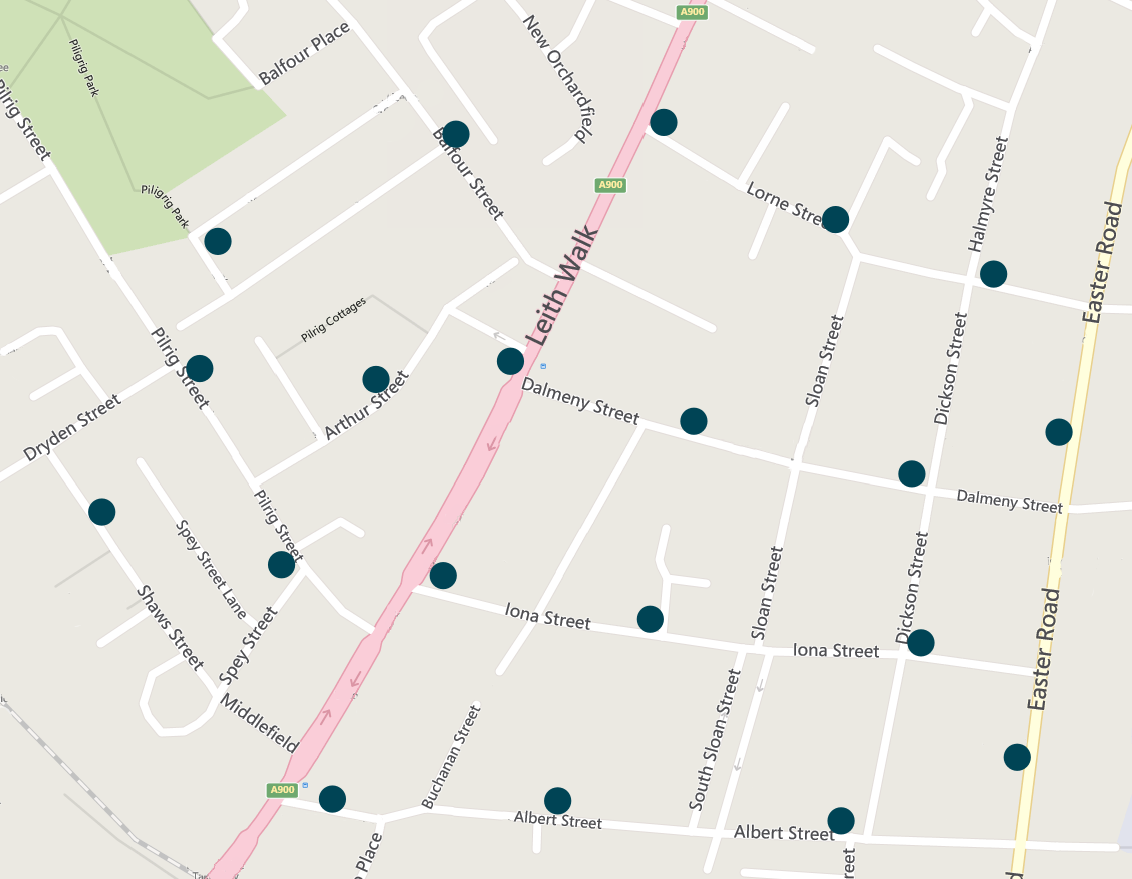
Map source: bing.com
Graph representation
- In mathematical terms such a collection of bus stops interconnected with street segments can be represented through a graph.
- A graph G = (V,E) comprises a set of vertices V that represent objects (bus stops) and E edges that connect different pairs of vertices (links/street segments).
- Graphs can be directed or undirected.
Undirected Graphs
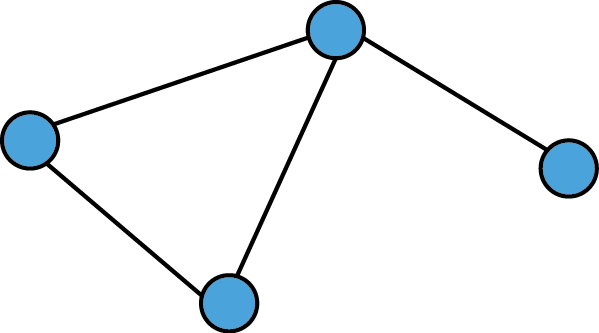
- Edges have no orientation, i.e. they are unordered pairs of vertices. That is there is a symmetry relation between nodes and thus (a,b) = (b,a).
Directed Graphs
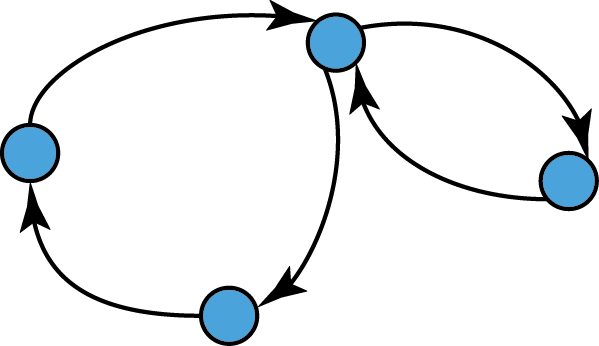
- Edges have a direction associated with them and they are called arcs or directed edges.
- Formally, they are ordered pairs of vertices,
i.e. (a,b) ≠ (b,a) if a ≠ b.
Graph representation in your simulators
- For our simulations we will consider directed graph representations of the service network.
- This will increase complexity, but is more realistic.
Back to the example
This area...
Map source: bing.com
Corresponding Graph
...can be represented by
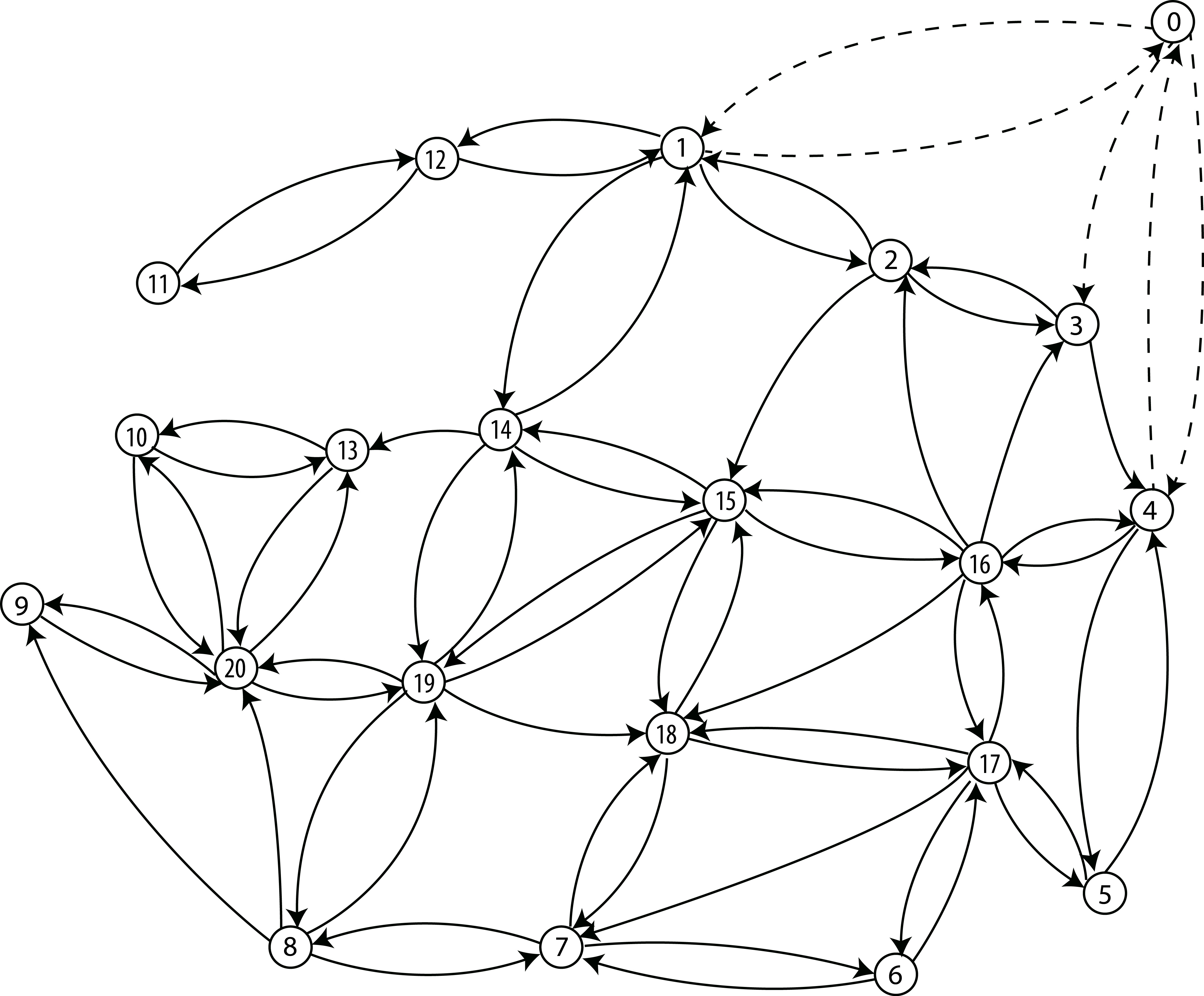
We numbered vertices & added node '0' for the garage.
Weighted Graph
- We also need to model the distances between stop locations.
- We will use a weighted graph representation, where a number (weight) is associated to each arc.
- In our case weights will represent the average travel duration between two stops (vertices) in one direction, expressed in minutes.
Weighted Graph
For our example, this may be
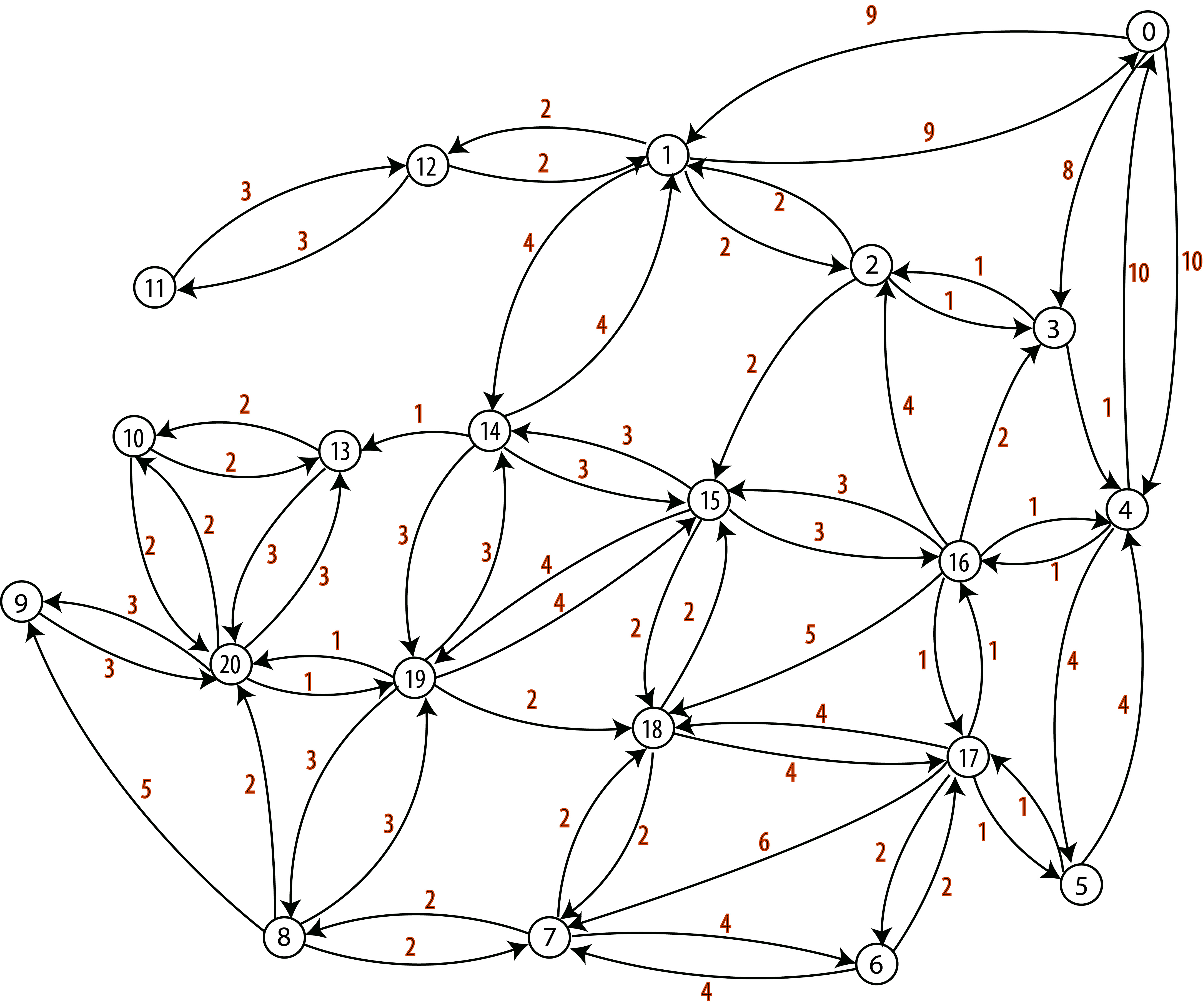
Input Script
- Graph representation of the bus stop locations and distances between them will be given in the input script in matrix form.
- We will consider the garage as bus stop 0. For a service network with N stops, a N x N matrix will be specified.
- The map keyword will precede the matrix.
- Where there is no arc in the graph between two vertices we will use a -1 value in the matrix.
For The Previous Example
0 1 2 3 4 5 ... 19 20
---------------------------------------------------
0| 0 9 -1 8 10 -1 ... -1 -1
1| 9 0 2 -1 -1 -1 ... -1 -1
2|-1 2 0 1 -1 -1 ... -1 -1
3|-1 -1 1 0 1 -1 ... -1 -1
4|10 -1 -1 1 0 4 ... -1 -1
5|-1 -1 -1 -1 4 0 ... -1 -1
.| . . . . . . . .
.| . . . . . . . .
.| . . . . . . . .
19|-1 -1 -1 -1 -1 -1 ... 0 1
20|-1 -1 -1 -1 -1 -1 ... 1 0
*Note that the matrix is not symmetric.
Route Planning
- Minibuses may be scheduled depending on different parameters:
- The maximum time a user is willing to wait (maxDelay).
- The difference between desired departure time of a user (related to pickupInterval) and the time of the request (related to requestRate).
- Based on a set of requests, you must compute the shortest routes that pick up and drop off the largest possible number of passengers that intend to take similar journeys.
Route Planning
- There may not be passengers boarding/disembarking at all the bus stops along a route.
- Thus it may be appropriate to work with an equivalent graph where vertices that do not require to be visited are isolated and equivalent arc weights are introduced.
- Sometimes it may be more efficient to travel multiple times through the same location, even if the route previously serviced passengers who had placed requests there.
The (More) Challenging Part
- Let's refer to the graph of all bus stops where service is required at a given time by "service graph".
- How to partition the service graph and find (almost) optimal routes that visit all vertices in the service graph with minimum cost?
- This is entirely up to you, but I will discuss some useful aspects next.
- You must justify your choice in the final report and comment appropriately the simulator code.
- You may wish to implement more than one algorithm.
Useful terminology
- A walk is a sequence of arcs connecting a sequence of vertices in a graph.
- A directed path is a walk that does not include any vertex twice, with all arcs in the same direction.
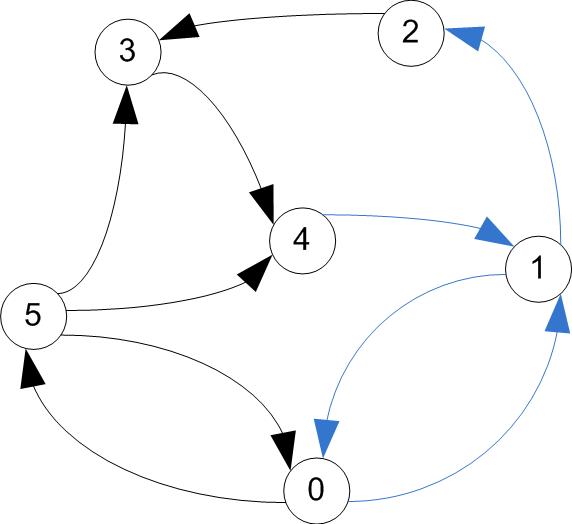
- A cycle is a path that starts & ends at the same vertex.
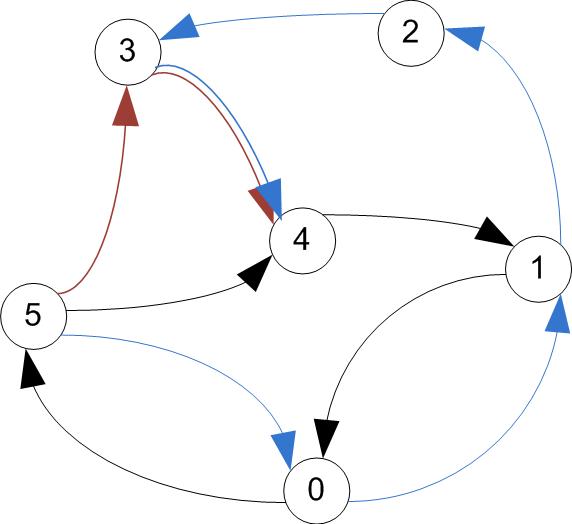
directed paths / cycle
Useful terminology
- A trail is a walk that does not include any arc twice.
- A trail may include a vertex twice, as long as it comes and leaves on different arcs.
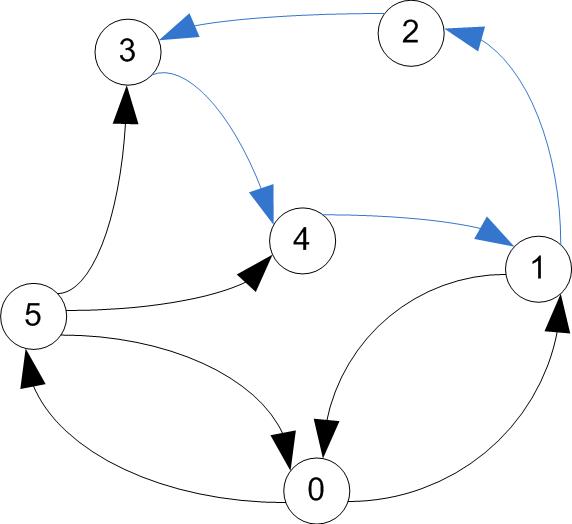
- A circuit is a trail that starts & ends at the same vertex
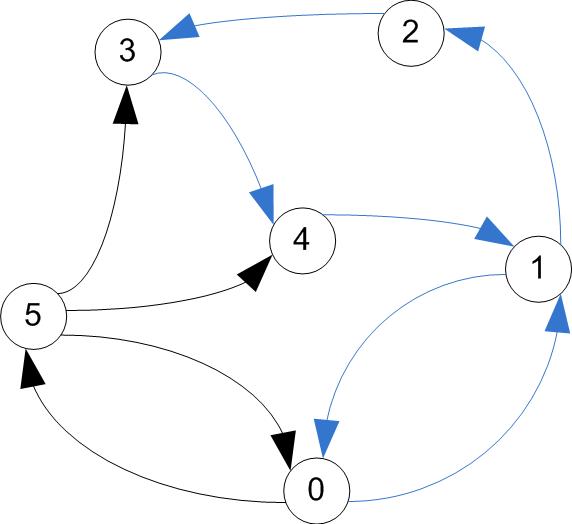
trail / circuit (tour)
Shortest paths
- There may be multiple paths that connect two vertices in a directed graph.
- In a weighted graph the shortest path between two vertices is that for which the sum of the arc costs (weights) is the smallest.
Shortest paths
- There are several algorithms you can use to find the shortest paths on a given service network.
- A non-exhaustive list includes
- Dijkstra's algorithm (single source),
- Floyd-Warshall algorithm (all pairs),
- Bellman-Ford algorithm (single source).
- Each of these have different complexities, which depend on the number of vertices and/or arcs.
- The size and structure of the graph will impact on the execution time.
Floyd–Warshall Algorithm
- A single execution finds the lengths of the shortest paths between all pairs of vertices.
- The standard version does not record the sequence of vertices on each shortest path.
- The reason for this is the memory cost associated with large graphs.
- We will see however that paths can be reconstructed with simple modifications, without storing the end-to-end vertex sequences.
Floyd–Warshall Algorithm
- Complexity is O(N3), where N is the number of vertices in the graph.
- Consider di,j,k to be the shortest path from i to j obtained using intermediary vertices only from a set {1,2,...,k}.
- Next, find di,j,k+1 (i.e. with nodes in {1,2,...k+1}.
- This could be di,j,k+1 = di,j,k or
- A path from vertex i to k+1 concatenated with a path from vertex k+1 to j.
The core idea:
Floyd–Warshall Algorithm
- Then we can compute all the shortest paths recursively as
di,j,k+1 = min(di,j,k, di,k+1,k + dk+1,j,k).
- Initialise di,j,0 = wi,j (i.e. start form arc costs).
- Remember that in your case the absence of an arc between vertices is represented as a -1 value, so you will need to pay attention when you compute the minimum.
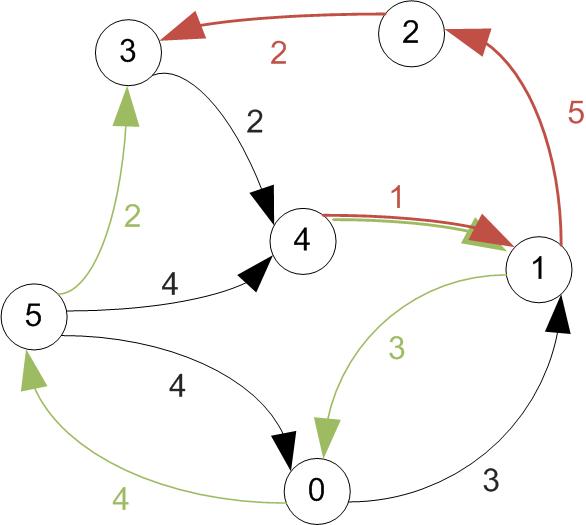
Example
First let's increase vertex indexes by one, since we were starting at 0.
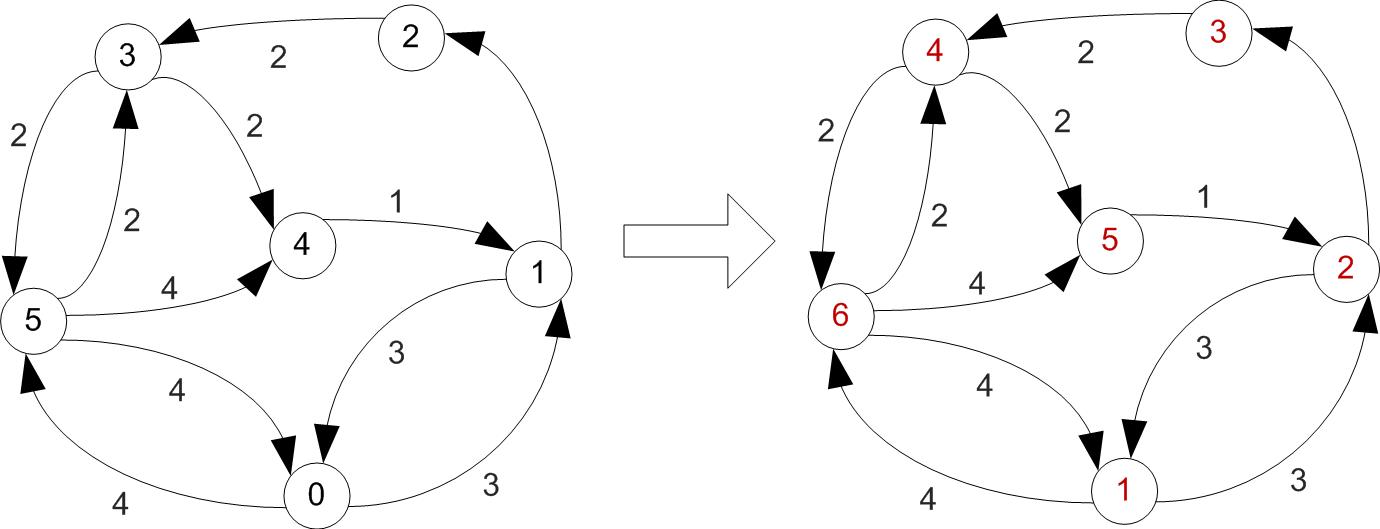
Example
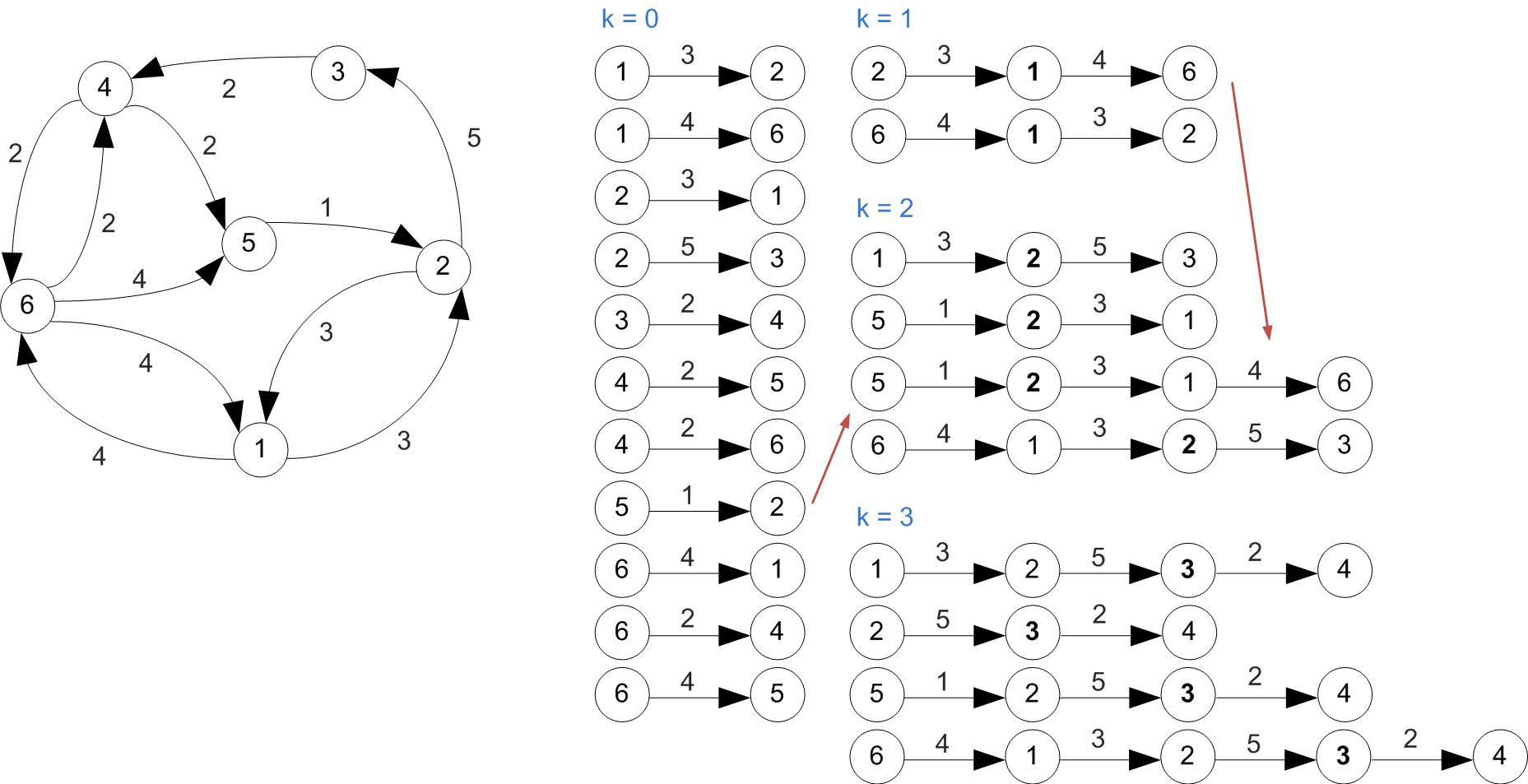
Example (Cont'd)
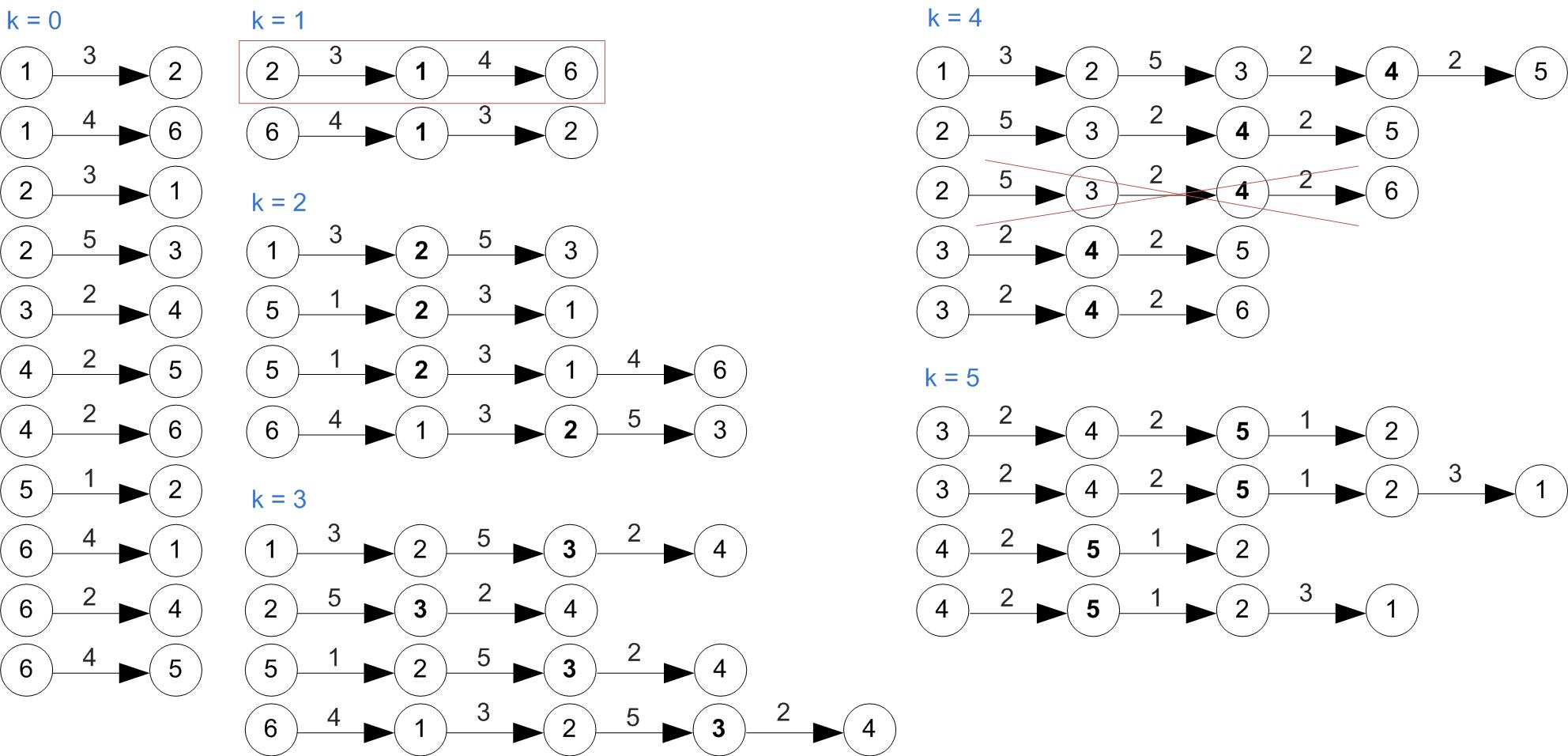
Example (Cont'd)
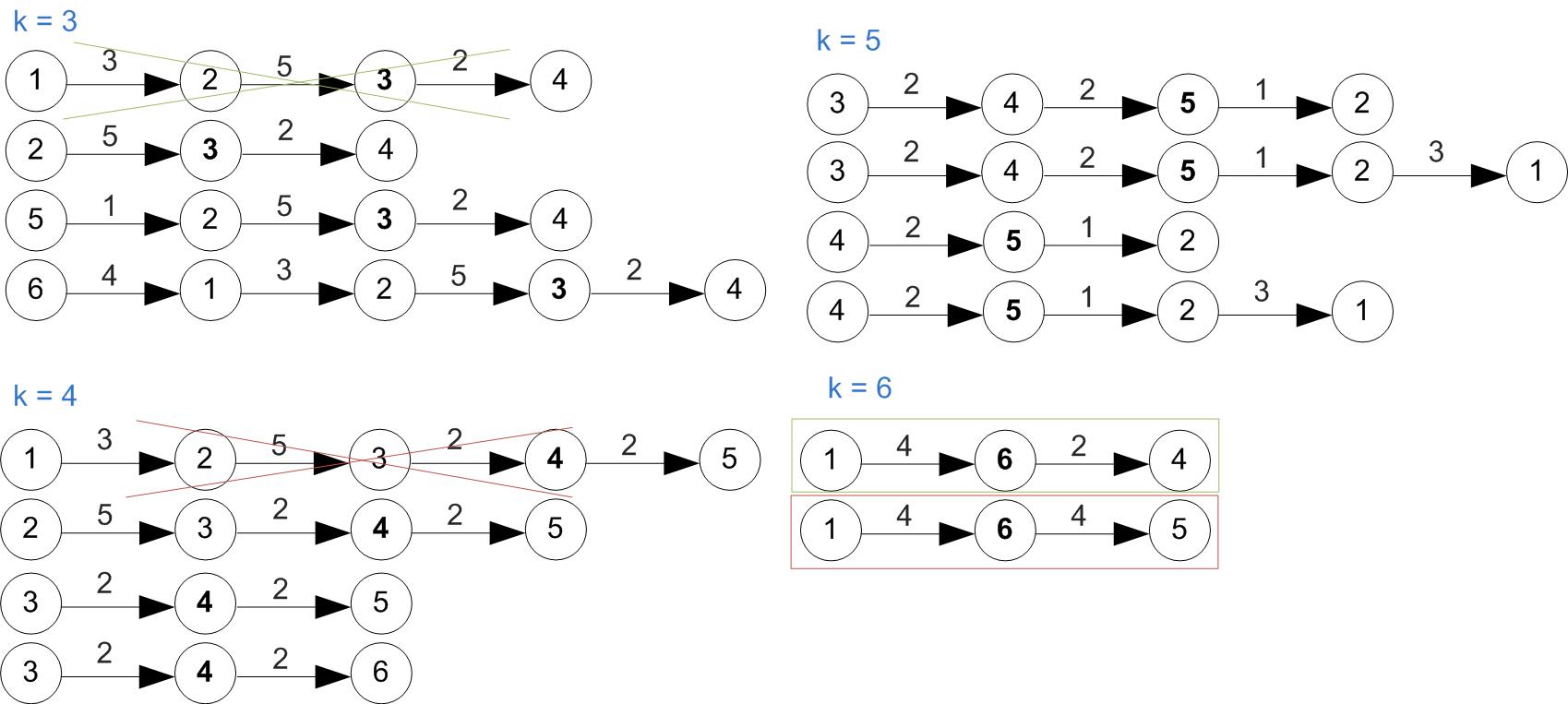
All shortest paths found at this step.
Pseudocode
Denote d the N × N array of shortest path lengths.
Initialise all elements in d with inf.
For i = 1 to N
For j = 1 to N
d[i][j] ← w[i][j] // assign weights of existing arcs;
For k = 1 to N
For i = 1 to N
For j = 1 to N
If d[i][j] > d[i][k] + d[k][j]
d[i][j] ← d[i][k] + d[k][j]
End If
Floyd–Warshall Algorithm
- This will give you the lengths of the shortest paths between each pair of vertices, but not the entire path.
- You do not actually need to store all the paths, but you would want to be able to reconstruct them easily.
- The standard approach is to compute the shortest path tree for each node, i.e. the spanning trees rooted at each vertex and having the minimal distance to each other node.
Pseudocode
Denote d, nh the N × N arrays of shortest path lengths and
respectively the next hop of each vertex.
For i = 1 to N
For j = 1 to N
d[i][j] ← w[i][j] // assign weights of existing arcs;
nh[i][j] ← j
For k = 1 to N
For i = 1 to N
For j = 1 to N
If d[i][j] > d[i][k] + d[k][j]
d[i][j] ← d[i][k] + d[k][j]
nh[i][j] ← nh[j][k]
End If
Reconstructing the paths
To retrieve the sequence of vertices on the shortest path between nodes i and j, simply run a routine like the following.
path ← i
While i != j
i ← nh[i][j]
append i to path
EndWhile
Finding Optimal Routes Given a Set of User Requirements
- Finding shortest paths between different bus stops is only one component of route planning.
- The problem you are trying to solve is a flavour of the Vehicle Routing Problem (VRP). This is a known NP-hard problem.
- Simply put, an optimal solution may not be found in polynomial time and the complexity increases significantly with the number of vertices.
Heuristic Algorithms
- Heuristics work well for finding solutions to hard problems in many cases.
- Solutions may not be always optimal, but good enough.
- Work relatively fast.
- When the number of vertices is small, a 'brute force' approach could be feasible.
- Guaranteed to find a solution (if there exists one), and this will be optimal.
Choosing Route Planning Algorithms
- You have complete freedom to choose what heuristic you implement, but
- make sure you document your choice and discuss its implication on system’s performance in your report.
- It is likely that you will need to compute shortest paths.
- Again, you can choose any algorithm for this task, e.g. Floyd-Warshall, Dijkstra, etc., but explain your choice.
- You can implement multiple solutions, as some may not work for any graph or will perform poorly.
Code Structuring & Coding Strategy
How to structure your work?
- This is for guidance only and I will not go into great detail, to avoid seeing identically structured solutions.
- Part of the practical is structuring it yourself. However, it is
likely you will want at least the following components:
- A parser,
- A representation of the states of a simulation,
- The simulation algorithm,
- Something to handle output,
- Something to analyse results,
- A test suite.
Some Obvious Decisions
- Do you want to parse into some abstract syntax data structure
and then convert that into a representation of the initial state,
- Or could you parse directly into the representation of the initial state?
- Do you wish to print out events as they occur during the simulation,
- Or record them and print them out later?
- Do you wish to analyse the simulation events as the simulation proceeds,
- Or analyse the events afterwards?
Parsing
- You do not necessarily need to start with the parser.
- The parser produces some kind of data structure. You could instead start by hard coding your examples in your source code.
- Though the parsing for this project is pretty simple.
- Hence you could start with the parser, even if this is not complete
before moving on.
- Hard coding data structure instances could prove laborious,
- but doing so would ensure your simulator code is not heavily coupled with your parser code.
Software Construction
- Software construction is relatively unique in the world of large projects in that it allows a great deal of back tracking.
- Many other forms of projects, such as construction, event planning, and manufacturing, only allow for backtracking in the design phase.
- The design phase consists of building the object virtually (on paper, on a computer) when back tracking is inexpensive.
- Software projects do not produce physical artefacts, so the construction of the software is mostly the design.
Refactoring
- Refactoring is the process of restructuring code while achieving exactly the same functionality, but with a better design.
- This is powerful, because it allows trying out various designs, rather than guessing which one is the best.
- It allows the programmer to design retrospectively once significant details are known about the problem at hand.
- It allows avoiding the cost of full commitment to a particular solution which, ultimately, may fail.
More About Refactoring
- Refactoring is a term which encompasses both factoring and defactoring.
- Generally the principle is to make sure that code is written exactly once.
- We hope for zero duplication.
- However, we would also like for our code to be as simple and comprehensible as possible.
Factoring and Defactoring
- We avoid duplication by writing re-usable code.
- Re-usable code is generalised.
- Unfortunately, this often means it is more complicated
- Factoring is the process of removing common or replaceable units of code, usually in an attempt to make the code more general.
- Defactoring is the opposite process specialising a unit of code usually in an attempt to make it more comprehensible.
Factoring Example
#include <stdbool.h>
void primes(int limit) {
int i, x = 2;
while (x <= limit){
bool prime = true;
for (i = 2; i < x; i++) {
if (x % i == 0){
prime = false;
break;
}
}
if (prime) {
printf("%d is prime\n", x);
}
x++;
}
}
Factoring Example
#include <stdbool.h>
void printPrime(int x) {
printf("%d is prime\n", x);
}
void primes(int limit) {
int i, x = 2;
while (x <= limit) {
... // as before
if (prime) {
print_prime(x);
}
x++;
}
}
Factoring Example
To make it more general we have to actually parametrise what we do with the primes once we have found them.
#include <stdbool.h>
void primes(int limit, void (*processPrimes) (int)) {
int i, x = 2;
while (x <= limit) {
... // as before
if (prime) {
(*processPrimes)(x);
}
}
}
Factoring Example
For instance, to print to display
void printPrime(int x) {
printf("%d is prime\n", x);
}
void primes(int limit, void (*processPrimes) (int)) {
int i, x = 2;
while (x <= limit) {
... // as before
if (prime) {
(*processPrimes)(x);
}
x++;
}
}
int main(void) {
primes (100, &printPrime);
...
}
Factoring
- What you should factor depends on the context.
- How likely am I to need more than just prime numbers?
- How likely am I to do something other than print the primes?
- Try to find the right re-usability/time trade-off.
Defactoring
- Numbers such as the number 20 can be factored in different ways
- 2,10
- 4,5
- 2,2,5
- If we have the factors 2 and 10, and realise that we want the number
4 included in the factorisation we can either:
- Try to go directly by multiplying one factor and dividing the other, or
- Defactor 2 and 10 back into 20, then divide 20 by 4.
Defactoring
- Similarly, your code is factored in some way.
- In order to obtain the factorisation that you desire, you may have to first defactor some of your code.
- This allows you to factor down into the desired components.
- This is often easier than trying to short-cut across factorisations.
Defactoring
- Flexibility is great, but it is generally not without cost.
- The cognitive cost associated with understanding the more abstract code.
- If the flexibility is not now or unlikely to become required then it might be worthwhile defactoring.
- It is appropriate to explain your reasoning in comments.
Refactoring Summary
- Code should be factored into multiple components.
- Refactoring is the process of changing the division of components.
- Defactoring can help the process of changing the way the code is factored.
- Well factored code will be easier to understand.
- Do not update functionality at the same time.
Suggested Strategy
- Note that this is merely a suggested strategy.
- Start with the simplest program possible.
- Incrementally add features based on the requirements.
- After each feature is added, refactor your code.
- This step is important, it helps to avoid the risk of developing an unmaintainable mess.
- Additionally it should be done with the goal of making future feature implementations easier.
- This step includes janitorial work (discussed later).
Suggested Strategy
- At each stage, you always have something that works.
- Although you need not specifically design for later features, you do at least know of them, and hence can avoid doing anything which will make those features particularly difficult.
Alternative Inferior Strategy
- Design the whole system before you start.
- Work out all components and sub-components needed.
- Start with the sub-components which have no dependencies.
- Complete each sub-component at a time.
- Once all the dependencies of a component have been developed, choose that component to develop.
- Finally, put everything together to obtain the entire system, then test the entire system.
Janitorial Work
- Janitorial work consists mainly of the following:
- Reformatting,
- Commenting,
- Changing Names,
- Tightening.
Janitorial Work
Reformatting
void function_name (int x)
{
return x + 10;
}
void function_name(int x) {
return x + 10;
}
Janitorial Work
Reformatting
- Reformatting is entirely superficial.
- It is important to consider when you apply this.
- This may well conflict with other work performed concurrently.
- Reformatting should be largely unnecessary, if you keep your code
formatting correctly in the first place.
- More commonly required on group projects.
Janitorial Work
Commenting
- Writing good comments in your code is essential.
- When done as janitorial work this can be particularly useful.
- You can comment on the stuff that is not obvious even to yourself as you read it.
- The important thing to comment is not what or how but why.
- Try not to have redundant/obvious information in your comments:
// 'x' is the first integer argument int leastCommonMultiple(int x, int y);
Janitorial Work
Commenting
Ultra bad:
// increment x
x += 1;
// Since we now have an extra element to consider
// the count must be incremented
x += 1;
Janitorial Work
Changing Names
- The previous example used
xas a variable name. - Unless it really is the x-axis of a graph, choose a better name.
- This is of course better to do the first time around.
- However as with commenting, unclear code can often be more obvious to its author upon later reading it.
Janitorial Work
Tightening
...
FILE *fInput;
fInput = fopen(fileName, "r");
parseInput(fInput);
fclose(fInput);
...
FILE *fInput;
fInput = fopen(fileName, "r");
if (fInput == NULL) {
// Explain to the user ...
printf("Error: %d (%s)\n", errno, strerror(errno));
} else {
parseInput(fInput);
fclose(fInput);
}
Janitorial Work
Tightening
- For some developers this is not janitorial work, since it actually changes in a non-superficial way the function of the code.
- However, similar to other forms, it is often caused by being unable to think of every aspect involved when writing new code.
Janitorial Work
- Most of this work is work that arguably could have been done right the first time around when the code was developed.
- However, when developing new code, you have limited cognitive capacity.
- You cannot think of everything when you develop new code. Janitorial work is your time to rectify the minor stuff you forgot.
- Better than trying to get it right first time is making sure you later review your code.
Janitorial Work
- Remember, refactoring is the process of changing code without changing its functionality, whilst improving design.
- Strictly speaking janitorial work is not refactoring.
- It should not change the function of the code,
- (Tightening might, but generally for exceptional input only.)
- but neither does it make the design any better.
- It should not change the function of the code,
- In common with refactoring you should not perform janitorial work on pre-existing code whilst developing new code.
Common Development Approach
- Start with the main function;
- Write some code, for example to parse the input;
- Write (or update) a test input file;
- Run your current application;
- See if the output is what you expect;
- Go back to step 2.
Do Not Start with Main
- A better place to start is with a test suite.
- This doesn't have to mean you cannot start coding.
- Write a couple of test inputs.
- Create a skeleton “do nothing” parse function.
- Create an entry point which simply calls your parse function on your test inputs (all of them).
- Watch them fail.
Do Not Start with Main
- Code until those tests are green,
- including possibly refactoring.
- Consider new functionality:
- Write a function that tests for that new functionality.
- Watch it fail, whether by generating an error or simply not producing the results required.
- Return to step 1.
- You can write your
mainfunction any time you like.- It should be very simple, as it simply calls all of your fully tested functionality.
Do Not Start with Main
- Any time you run your code and examine the results, you should be examining the output of tests.
- If you are examining the output of your program ask yourself:
- Why am I examining this output by hand and not automatically?
- If I fix whatever is strange about the output can I be certain that I will never have to fix this again?
- Of course sometimes you need to examine the output of your program to determine why it is failing a test. This is just semantics (it is still the output of some test).
Summary
- Refactoring allows you to avoid doing a large amount of upfront design and also avoid producing a big mess.
- Do not change functionality whilst refactoring.
- Your code should be adaptable.
- Do not start with
main, write a test suite instead.
Memory management
Memory management in C
- Memory allocation/deallocation is done differently in C as compared to what you may be used with other languages.
- There is no automatic memory management (garbage collection) and thus the programmer is responsible for releasing dynamically allocated memory when no longer needed.
- Poor memory management can lead to memory leaks → system performance suffers as virtual memory is progressively paged to hard drive. The OS may crash.
Memory allocation
- Two mechanisms are used to allocate memory in C
- Declaring local variables. These are stored in a stack and are automatically freed when they become out of scope (e.g. exiting a function).
int parseInput(FILE *finput) { int N; int array[100]; ... } - Nice, right? Well there's a catch. The compiler needs to know in advance how much memory to allocate (inefficient) and the stack size is limited (not all your variables may fit).
Memory allocation
- Two mechanisms are used to allocate memory in C
- Requesting memory explicitly and storing variables in the heap.
- You can allocate as much memory as the system allows, but you need to take care of releasing it.
...
int N;
int *array;
...
array = (int *) malloc(N * sizeof(int));
free(array);
Segmentation Fault & Co
A few things can go wrong if not careful with variables allocated on the heap.
- Memory leaks → you forget to call free() when variables no longer needed.
- You try to free, but allocation failed or memory already deallocated.
char *fileName = malloc(255*sizeof(char));
if (fileName != NULL) {
...
free(fileName);
}
char *temp = malloc(64*sizeof(char));
memcpy(temp, data, dataLen); // dataLen > 64 gives gives error
Segmentation Fault & Co
- You use an out of bounds array index
int *array = malloc(128*sizeof(int));
int N = 200;
for (i = 0; i < N; i++) { // once i > 127, an error will occur
...
}
struct *listElement;
x = listElement->value;
Segmentation Fault & Co
- You return a pointer to a variable from the stack
int *getCount() {
int n; // Local stack variable
... // count the number of values that
// divide by x in an array
return &n;
}
int main(void){
int *n;
...
n = getCount(); // Stack given up by getCount(),
// &n no longer safe
... // n may be corrupt when needed later
}

Why no garbage collection in C?
- Garbage collection involves constructing a complex data structure for keeping track of allocations and references counting.
- This mechanism increases the complexity of the language and affects the performance (overhead).
- C is meant for designing very fast code, e.g. for operating systems, device drivers, etc.
- High performance is traded for convenience.
Array & String Handling
Allocating arrays & matrices
We discussed how you can allocate memory dynamically for an array of N elements.
int N;
int *array;
array = (int *) malloc(N * sizeof(int));
But, how do you allocate memory for a matrix?
Common mistake
int N;
int **matrix;
matrix = (int **) malloc(N * N * sizeof(int));
Matrix allocation
Remember, you are trying to allocate a pointer to an array of pointers to integers
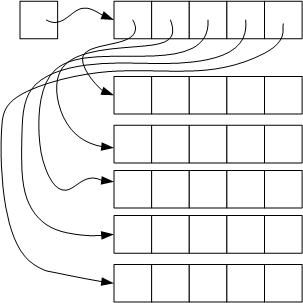
Matrix allocation
Approach 1
int i,N;
int **matrix;
matrix = (int **) malloc(N * sizeof(int*)); // rows
for(i = 0; i < N; i++)
matrix[i] = (int *) malloc(N * sizeof(int)); // columns
// access the (i,j) element by
matrix[i][j] = ...
Approach 2 (define the matrix as an array)
int i,N;
int *matrix;
matrix = (int *) malloc(N * N * sizeof(int));
// and access the (i,j) element by
matrix[i*N+j] = ...
Matrix deallocation
When using the first approach, first deallocate the memory allocated for each row
for(i = 0; i < N; i++)
free(matrix[i]);
free(matrix);
When using the second approach, simply
free(matrix);
What about arrays of structures?
- Imagine the following
typedef struct {
int groupSize;
float* marks;
} GROUP;
int nGroups = 5;
GROUP *g;
- The same principle applies
g = (GROUP *) malloc(nGroups * sizeof(GROUP));
for (i = 0; i < nGroups; i++) {
fscanf(stdin, "%d", &g[i].groupSize);
g[i].marks = (float *) malloc(g[i].groupSize * sizeof(float));
...
}
String handling
- Strings are simply arrays of characters terminated by the ASCII null character '\0'.
char *str;
char string[100];
str = (char*) malloc(100*sizeof(char));
Functions you may use
- Copying
char* strcpy(char *dst, const char *src);
char* strncpy(char *dst, const char *src, int len);
NB: careful with sizes to avoid memory corruption.
Functions you may use
- Comparing
int strcmp(const char *str1, const char *str2);
- <0 if the first character that does not match has a lower value in str1 than in str2;
- 0 if the contents of both strings are equal;
- >0 if the first character that does not match has a greater value in str1 than in str2.
Functions you may use
- Searching
char* strstr(const char *str1, const char *str2);
size_t strlen(const char *str);
Functions you may use
- Tokenising – a string into different tokens according to some delimiter(s):
char *strtok(char *str, const char *delim)
- str broken into smaller strings.
- delim may contain different characters to be used as delimiters.
- Returns a pointer to the last token found or NULL if none found.
- Can be called multiple times to find all tokens.
Functions you may use
Example
const char str[100] = "The quick brown fox jumps over the lazy dog";
const char delim[2] = " ";
char *token;
token = strtok(str, delim); // gets first token
while(token != NULL) { // retrieve all tokens; stop when no more found
printf("%s\n", token);
token = strtok(NULL, delim);
}
Converting strings to numbers
- Converting to floating-point numbers
double strtod(const char *str, char **ptr);
float strtof(const char *str, char **ptr);
char str[11] = "9.50 marks";
char *ptr;
float fVal;
fVal = strtof(str, &ptr);
printf("Number:%.2f\t String:%s\n", fVal, ptr);
// Number:9.50 String: marks
Converting strings to numbers
- Converting to (long) integer numbers
long int strtol(const char *str, char **ptr, int base);
- base must be between 2 and 36.
- if base is 0, the expected form is a decimal/octal/hexadecimal constant.
Converting strings to numbers
Example:
char str[11] = "60 seconds";
char *ptr;
long int liVal;
liVal = strtol(str, &ptr, 10);
printf("Number:%ld\t String:%s\n", liVal, ptr);
// Number:60 String: seconds
Converting strings to numbers
- Question: what will be the output of the following?
char *str;
double fVal;
long int liVal;
liVal = strtol("20.00mm", &str, 10);
printf("Number:%ld\t String:%s\n", liVal, str);
fVal = strtod("1e+2 litres", &str);
printf("Number:%.1lf\t String:%s\n",fVal,str);
liVal = strtol("FFGH", &str, 16);
printf("Number:%ld\t String:%s\n", liVar,str);
Converting strings to numbers
- Answer:
Number:20 String:.00mm
Number:100.0 String: litres
Number:255 String:GH
Note: A good resource for understanding other string manipulation functions is available here.
Code Optimisation
Code Optimisation
- Refactoring is done in between development of new functionality
- Recall this makes it easier to test that this process has not changed the behaviour of your code.
- This is also a good time to do some optimisation
- You should be in a good position to test that your optimisations have not negatively impacted correctness.
When to Optimise?
- When you discover that your code is not running fast enough, it's probably wise to optimise it.
- Often this will come towards the end of the project.
- It should certainly come after you have something deployable.
- Preferably after you have developed and tested some major portion of functionality.
A Plausible Strategy
- Perform no optimisation until the end of the project once all functionality is complete and tested.
- This is a reasonable approach; however:
- During development, you may find that your test suite takes a long time to run.
- Even one simple run to test the functionality you are currently developing may take minutes/hours.
- This can slow down development significantly, so it may be appropriate to do some optimisation at that point.
How to Optimise
- The very first thing you need before you could possibly optimise code is a benchmark.
- This can be as simple as timing how long it takes to run your test suite.
- O(n2) solutions will beat O(n log n) solutions on sufficiently small inputs, so your benchmarks must not be too small.
How to Optimise
Once you have a suitable benchmark then you can:
- Save a copy of your current code;
- Run your benchmark and record the run time;
- Perform what you think is an optimisation on your source code;
- Re-run your benchmark & compare the run times;
- If you successfully improved the performance of your code keep the new version, otherwise revert changes;
- Do one optimisation at a time.
How to Optimise
- However, bear in mind that you are writing a stochastic simulator
- This means each run is different and hence may take a different time to run,
- Even if the code has not changed or has changed in a way that does not affect the run time significantly.
- Simply using the same input several times should be enough to reduce or nullify the effect of this.
Profiling
- Profiling is not the same as benchmarking.
- Benchmarking:
- determines how quickly your program runs;
- is to performance what testing is to correctness.
- Profiling:
- is used after benchmarking has determined that your program is running too slowly;
- is used to determine which parts of your program are causing it to run slowly;
- is to performance what debugging is to correctness.
Benchmarking & Profiling
- Without benchmarking you risk making changes to your program that will lead to poorer performance.
- Without profiling you risk wasting effort optimising a part of code which is either already fast or rarely executed.
Documenting: Source code comments are a good place to explain why the code is the way it is.
Questions?
Updates to the Coursework Handout
Handout Updates
- A couple of updates have been made to the handout.
- These are all minor, but are meant to
- Clarify a few aspects regarding generation of events.
- Tweak the output requirements to simplify the marking process.
- Exemplify summary statistics.
- Clarify output specifications for experiments and introduce delimiter requirements for the output.
- Introduce the requirement of a Makefile.
Handout Updates - Events
- Requests arrive in the system in a stochastic fashion.
- A request comprises:
- desired pick-up time
- source stop
- target (destination) stop
- Time between requests and the delay between a request and its corresponding pick-up time are chosen by sampling exponentially distributed R.V.
- When the mean rate is given as input, the mean delay is computed as the reciprocal of the rate.
- Source and target stops chosen uniformly at random.
Handout Updates - Output
- Specify the destination stop of a request, i.e.
‹time› -> new request placed from stop ‹unsigned int› to
stop ‹unsigned int› for departure at ‹time› scheduled for ‹time›
‹time› -> new request placed from stop ‹unsigned int› to
stop ‹unsigned int› for departure at ‹time› cannot be accommodated
- For example:
00:01:25:10 -> new request placed from stop 3 to stop 8 for departure
at 00:01:34:00 scheduled for 00:01:36:00
Example summary statistics
---
average trip duration 14:30
trip efficiency 7.20
percentage of missed requests 0.10
average passenger waiting time 30 seconds
average trip deviation 1.60
---
Delimit the start and end of the statistics with a '---' sequence.
Output of Experiments
- When running experiments, disable the output of detailed information and instead only display summary statistics.
- To delimit the different experiments, precede the output of each with the following heading:
Experiment #‹experiment no.›: ‹param1› ‹param1-value› ‹param2› ‹param2-value› ...
---
Output of Experiments
- For example:
...
Experiment #4: maxDelay 10 noBuses 15
---
average trip duration 14:30
trip efficiency 7.20
percentage of missed requests 0.10
average passenger waiting time 30 seconds
average trip deviation 1.60
---
Experiment #5: maxDelay 10 noBuses 20
---
average trip duration 12:00
...
Handout Updates - Makefile
- Part of the functionality of your simulator will be automatically tested.
- Therefore, also include a Makefile with your submission.
- Running `make` in the root directory of the submitted project should produce a running application.
CSLP assessment
Assessment Criteria (I)
- Implementation of requirements:
- Parsing
- Input validation
- Correct simulation & correct output
- Summary statistics of simulation results
- Experimentation implementation
- Source code documentation (comments)
Assessment Criteria (II)
- Testing, including sample test input scripts
- Maintainable code
- Code efficiency (optimisations)
- Any additional features
- Written report
Objective & Subjective Criteria
- Some of the items on the above list are objective whilst some are subjective
- Objective criteria are those which are testable
- Subjective criteria are those which are, at least partially, based upon opinion
Objective Assessment Criteria
This first list of implementation requirements are all relatively objective:- Parsing
- Input validation
- Correct simulation & correct output
- Summary statistics of simulation results
- Experimentation implementation
Objective Assessment
- Your application will be put through my own suite of test inputs.
- Some of these test inputs will be inputs you have seen, some will be new.
- Part of the exercise is for you to foresee possible inputs for which
your application would fail
- Either by crashing, or by producing incorrect output.
- Should your application fail any tests I would have to figure out why this happened and objective marking would not be so straightforward.
Objective Assessment
- A good part of the testing will be automated, so you either pass or fail a test.
- Follow the given input/output specification strictly to avoid unpleasant surprises.
Parsing
- Your parser should be able to parse all syntactically valid input scripts.
- I cannot say it much simpler than that.
- There will not be any deliberately tricky tests.
Input Validation
- This is the first task which is not finely specified.
- You have to demonstrate some ingenuity to devise your own rules for what should and should not be valid input.
- You also have to decide which kinds of inputs result in
warnings or errors.
- Specifically those in which the simulation could be started but may result in an error.
- This may depend upon the structure of your simulator.
Correct Simulation & Output
- Here I will be testing whether your simulator follows the requirements correctly.
- The simulator is tested via its output, so these are tested at the same time.
- Having said that, where the output is not correct, the code is inspected to determine why.
- This is part of the reason your code must compile on DiCE
Summary Statistics
- This will test for correctly calculating and reporting the specified summary statistics.
- It is possible to get the simulation incorrect but the summary statistics correct.
- A small tip is to make sure your reported statistics are consistent with each other.
- It might be that you are getting inconsistent results because your simulation is incorrect, in which case you should note this in your README.
Experimentation Implementation
- Whether or not you correctly implement the experimentation of maximum admissible pick up delay and number of buses.
- As before it is possible to get this correct, without getting either (or both) of the simulation and the summary statistics correct.
- As before, if you are getting inconsistent results you should at least note that in your README.
Code efficiency
- Implementing some code optimisations will lead to shorter run times.
- It is possible that you implement everything above correctly, but your simulations take a very long time to complete.
- On the other hand, your code may run fast, but will not have implemented all requirements. This is not considered to be efficient.
Noting Deficiencies
- Use your README file to record any deficiencies you are aware of.
- In general any implementation errors will be treated more indulgently if they are known about.
- Remember, it is generally worse to produce incorrect output than no output at all.
Subjective Assessment
The remaining items are mostly judged subjectively- Source code documentation
- Testing, including sample test input scripts
- Maintainable code
- Any additional features
- Written report
Documentation
- Use appropriate comments to document your code.
- You may develop additional features which, if you do not document, I may not even know about.
- Clear mark and explain the code that you have not authored yourselves.
- Remember that code sharing is not allowed.
Testing
- The practical is intended to write a good simulator.
- You can at least strive for “half decent”.
- Either way, running one test input, is woefully insufficient.
- You also need to be able to investigate the performance of the "on-demand transport operation", what parameters affect this and how.
Maintainable Code
- Highly subjective.
- Remember, reusable code is more difficult to understand.
- But, reusable code is easier to reuse and maintain.
- What is an inexperienced developer to do?
- Try to imagine what you might wish to do in the future.
Maintainable Code
- Trying to justify your choices is likely a good thing.
- Even if your reasoning is flawed, it demonstrates that you have thought about how to design your source code.
- It also shows that you probably could have implemented things in other way, but specifically chose not to.
- A future maintainer at least knows why you made that choice, if they disagree, they can change the code without fear of some other reason they have not yet uncovered.
Additional Features
- This is your chance to be creative and go beyond the implementation of the requested features.
- It perhaps requires some imagination, but imagine you were really going to use your simulator to investigate some real (or other) logistics operation.
- What would be useful to you?
README
- Don't forget to provide me with a README.
- In general this can only help your grade:
- It lets me know good things are deliberate and not fortunate.
- It lets me know that deficiencies are at least known about.
Written report
You should produce a written report that discusses:
- the key building blocks of your design,
- the results of the analyses you performed with different inputs,
- insights gained into system's performance,
- a summary of the most important findings.
Useful things to include in your written report
- Produce graphs based on the numerical output of your simulations to support your findings, especially for experimentation.
- Explain the purpose of the tests carried out and whether the results met your initial expectations. Any lessons learned?
- Motivate your choice(s) of route planning algorithms implemented and discuss their impact on the performance of the system.
Final Points
- The report will have a 25% weight of the final mark.
- There is no minimum number of pages required for the report.
- Present your findings and results clearly.
- Submit the report as a PDF file.
- Students are often worried about losing marks.
- Indeed our own assessment descriptions often talk of losing marks.
- But let's not forget, you start with zero.
Optimising compilation
Optimising compilation
- We already discussed about code optimisation.
- Benchmarking
- Profiling
- It is possible to further optimise your code at compilation
- try to minimise program's execution time;
- try to minimise the amount of memory occupied (less common);
- minimise the consumed power (for mobile devices).
Compiling and Linking
- Compiling is not the same as creating an executable.
- Building an executable involves compilation and linking.
- Your code may compile without errors, but it may fail during the linking phase.
Compiling and Linking
Compilation
- Turning the source code into an 'object' file.
- This is not executable, it only contains the corresponding machine language instructions.
- If you have multiple files, you will have multiple objects
# gcc -c -o "simulator.o" "simulator.c"
# gcc -c -o "utils.o" "utils.c"
The "-c" flag specifies that no linking should be done at this stage.
Compiling and Linking
Linking
- The process of creating a single executable from multiple object files.
- Finds references for the functions that are used in one file but were defined in another.
# gcc -o "simulator" simulator.o utils.o
Compiling and Linking
- This approach allows building large programs without having to redo the compilation every time a file is changed.
- Conditional compilation --compile only source files that have changed;
- Conditional compilation works well when you use some Integrated Development Environment (IDE).
- Otherwise you will have to manually create a makefile and use the make utility, which determines what needs to be recompiled.
Optimising compilation
- When you compile your code, you can set some flags that instruct the compiler to perform some optimisation.
- Note that this often takes more time and requires more memory, but your executable may run faster.
- Example:
# gcc -O3 -o "simulator.o" "simulator.c"
-O<level> instructs the compiler to perform some optimisation.
Optimising compilation
- -O1 - tries to reduce code size and execution time, without performing optimisations that increase compilation time significantly.
- -O2 - performs several optimisations that do not involve a space-speed trade-off. Increases both compilation time and the performance of the generated code.
- -O3 - optimises even more.
- -O0 - reduces compilation time and makes debugging produce the expected results (default).
Check the GCC manual page for more details.
Multiple Files
- Question: Should you spread your implementation across multiple source code files?
- There may be some good reasons to do so:
- Increase code reusability
- Reduces compilation time
- Could help navigating source code faster
Multiple Files
- Not suggesting you should not, but do so for a good reason.
- Given the size of this project, you could try to use as few files as possible.
- Move type definitions, functions, etc. to separate files when that seems necessary.
Should I develop code with or without an IDE?
- This shouldn't make a difference, but you may have good reasons for choosing one of the two approaches.
- Coding using a plain text editor (e.g. vi, nano)
- You can easily code remotely (over ssh) on e.g. a DiCE machine
- Write a makefile yourself (essential if working with multiple files).
- Better control on compilation optimisation.
Should I develop code with or without an IDE?
- Using IDEs
- Nicer keyword highlighting;
- Some auto complete braces/brackets/parenthesis;
- Some may have integrated help for functions;
- Some warn about certain syntax errors as you type;
- Perhaps easier if you are not very experienced in C;
- If you decide to code using an IDE, it's entirely up to you which one you choose (NetBeans C/C++ pack, CodeLite, Eclipse CDT, etc.)
Questions?
Survey Analysis
Survey Analysis
- 16 respondents.
- 62.50% have never written any C code before starting the CSLP.
- 31.25% have only written simple C code.
- 43.75% still have difficulties working across different functions with variables allocated on the heap, BUT the majority think they can learn memory management without guidance.
- If you think this is crucial to your project but cannot figure how out it works, please come and meet me.
Survey Analysis (CONT'D)
- Most of you have done janitorial work, but 3/4 do not write reusable code.
- 94% found the lecture on code structuring and coding strategy useful.
- None of you have performed both code and compilation optimisations.
- Graph theory expertise: 2 camps (the expert crowd smaller though).
- CSLP difficulty: 75% know what they have to do, but think a lot of work is required.
- This is where time management becomes particularly important.
Survey Analysis (CONT'D)
- 15 out 16 received satisfactory answers from me. If you still have doubts, please get in touch!
- A couple of you noted I haven't used the mic it the AT LT. I apologise for that and am correcting it.
- "It would have been more beneficial if the deadline for the first part was much later"
- Finding the right trade off is not straightforward and now it is a bit late, but will improve next year.
Questions & Requests
Experiment vs simulation
- With simulation your are building an abstract model of a real system which you then analyse.
- Experiment may refer to:
- Taking a prototype to a test bed, lab, or operational system, to validate it or make new discoveries.
- Take a course of action when you do not know the outcome, but want to determine it – this is what you do with your simulator.
Questions & Requests
Questions & Requests
"I really disagree with using C"
- Not using a OOP language is making everything unnecessarily hard.
- Relevance of C is questionable (TIOBE index based on search results).
- Missing abstract types, could just use Java or Python instead.
Why C?
- C compiles down to machine code, i.e. you can run code before even having a file system or processes.
- It's ultra fast and portable.
- This is a Computer Science project – I could have asked you to code a device driver, but that would have been extremely tough for people with no C experience (quite an important number).
- TIOBE does not say what is the best programming language – you can check yourselves if C developers are in demand and how they are remunerated ;-)
Questions & Requests
- Input parsing/handling in C – quite specific, but will give some tips and you can come and talk to me.
- Overview of architectural patterns for the simulator
– I will cover some aspects on that today. - A number of you are interested in more techniques for manipulating graphs/perform routing – will cover that during the next lecture without suggesting a particular solution.
Input Parsing
Tips on Input Parsing
- You are given the input parameters in a plain text file.
- There a multiple ways to parse the contents of such files. I will not go into details, but give some tips.
- One approach:
- Read the file line by line with
fgets. - Split the line into tokens.
- Use
strcmp, strtolandstrtodto convert tokens into different data types.
- Read the file line by line with
Tips on Input Parsing
- Another approach:
- Work with
fscanfandsscanfto read. - Advance the file position indicator with
fseek. - May prove trickier when parameters are not encountered in the expected order.
- Work with
- Employing a
switchapproach with multiple cases is likely quite appropriate.
Design Aspects
System/Process Implementation

- Designing and implementing logistics operations, complex processes, and systems involves several steps.
- There is often a feedback loop involved, which allows to refine/improve/extend the system.
Requirements Analysis

- Understand the problem domain and specifications, and identify the key entities involved.
- Build an abstract representation of the system to be able to handle various input scenarios.
System Design

- Dividing the system into components; choosing suitable methodologies for implementation each component.
- Defining appropriate data structures, input/output formats, and so on.
Development

- This is the actual implementation work and is typically coupled with some preliminary testing.
- For source code, janitorial work, refactoring and some optimisations are also performed at this stage.
Testing

- Validation is performed once the system is partially/ entirely developed; also benchmarking and profiling.
- A system's performance evaluation is undertaken (experimentation with different inputs, distributions).
Deployment

- Once the tool (planner, simulator, etc.) has been thoroughly tested it can be deployed in a real setting.
- The input will be based on actual data and inputs may change over time (e.g. based on certain events).
Monitoring

- Once the system is operational, it is possible to gather real measurements and use those to refine the design.
- If new requirements are identified during operation, the system can be further extended.
The Bin Service Process

- Your simulator will be implementing a good bit of what could become a real logistics system.
- Unfortunately you will not have the opportunity to experiment with real data, but (time permitting) you have the flexibility to develop additional features.
Performance Evaluation

- We have discussed the requirements, as well as different design and development aspects for your simulator.
- We will now look into performance evaluation issues. Some of the things I will present may not be needed for this assignment, but will likely prove useful later.
Performance Evaluation
- Generally speaking, this is about quantifying the performance of a system.
- The first step is to identify the relevant metrics, i.e. measurable quantities that capture properties of interest.
- This could the throughput of a network link, the power consumption of a mobile device, the memory used by a software application, etc.
- For CSLP we are interested in the average trip duration, trip efficiency, percentage of missed requests, average passenger waiting time, average trip deviation.
Metrics
- It is essential to understand the performance evaluation goals, i.e. whether a metric should be small or large.
- It is also important to be aware of the goals of the evaluation:
- Improve the dimensioning/parametrisation of a system or process.
- Compare how different designs perform under different inputs and chose the best one.
Methodologies
When designing a system, performance evaluation can be conducted through one or more of the following methodologies:
- Numerical analysis - plugging some numerical values into a mathematical model of the system and computing the metrics of interest.
- Simulation - constructing a simplified model of a more complex real system and simulating its behaviour; typically fast, but neglecting certain practical aspects.
- Experimentation - Analysing the performance of a system via measurements. Assessing performance under exceptional circumstances may be infeasible.
Accuracy
- It is advisable that the assumptions made for the evaluation campaign are well documented, to ensure the tests performed are reproducible.
- You are working with a stochastic simulator and thus there will be some variability in the results of different tests with the same input.
- For this practical you have been asked to give average values of a set of metrics.
- In rigorous studies, it is necessary to also provide some confidence intervals for the results.
Summary Statistics
Histograms are graphical representations of the distribution of a set of measurements.
Example: distribution of the h-index of Nobel-prize recipients in Physics between 1985-2005.
Source: J.E. Hirsch, "An index to quantify an individual's scientific research output", Proc. NAS, 2005.
h-index: number of papers with h or more citations.
Histograms
- In mathematical terms, the histogram is a function that counts the number of observations in different categories (bins)
- The number of bins is typically computed as
where n is the number of samples in the data set x.
Mean and Standard Deviation
Computing the mean (average) of a set of measurements is straightforward:
The standard deviation gives a measure of the variation of the measurements from the mean:
Confidence Intervals
- These can be used to quantify the uncertainty about the average of a set of measurements subject to randomness.
- When computing averages across multiple simulations, you are gathering samples to estimate an unknown population mean.
- You choose the significance level that will reflect how confident you can be that the true value lies within that interval,
- E.g. for a significance level of 0.05, you will obtain a 95% confidence interval (typically used in practice).
Confidence Intervals
- The width of the confidence is affected by:
- sample size,
- population variability (standard deviation),
- confidence level chosen.
- Central Limit Theorem: For a large sample size, the sampling distribution of the mean will approach a normal distribution.
- The sample mean and the mean of the population are identical.
Confidence Intervals
A quick method to compute a CI is:
where zα/2 is the critical coefficient corresponding to a confidence level α and is obtained from z-score tables.
Example: Sample size 20, mean 10, standard deviation 1.45, 95% confidence level, i.e. a critical coefficient corresponding to a z-score of 0.475, which is 1.96.
CI is 20±0.02
i.e. [19.8, 20.2]
Confidence Intervals
Plotting CIs
Questions?
Planning for the remaining duration of the semester
- 13 Nov – No lecture (next week).
- 20 Nov – Manipulating graphs and final points.
- 27 Nov – Guest lecture: Dr George Hazel, Scottish Enterprise (will speak about efforts to implement on demand mobility schemes in Scotland.)
- Reminder: Deadline for submitting Part 2 is the
21st December at 16:00. - Feedback by 21 January.
Path Finding and Graph Traversal
Path Finding and Graph Traversal
- Path finding refers to determining the shortest path between two vertices in a graph.
- We discussed the Floyd–Warshall algorithm previously, but you may achieve similar results with the Dijkstra or Bellman-Ford algorithms.
- Graph traversal refers to the problem of visiting a set of nodes in a graph in a certain way.
- You can use depth- or breadth-first search algorithms to traverse an entire graph starting from a given "root" (source vertex).
Path Finding and Graph Traversal
- Perhaps more useful to you are methods for finding traversable paths between multiple points.
- You have probably looked for such algorithms already. Today we will discuss one possible approach, namely the A* (A star) search algorithm.
- Key idea: Find the least-cost path from a source to one destination, out of one or more possible ones.
- Effectively builds a tree of partial paths, whose leaves are stored in a priority queue.
- Vertices are ordered in the queue according to a cost that consists of the distance travelled from source and an estimate of the distance to a goal (destination).
A* Search
- Formally, the cost function for a vertex n is expressed as:
- g(n) is the cost of getting from the source to n and is tracked by the algorithm.
- h(n) is a heuristic that estimates the cost from n to any possible goal.
- h(n) must be admissible, that is it should never overestimate the cost of reaching a goal (destination).
- One possibility is to compute h(n) as the shortest distance between any two vertices.
f(n) = g(n) + h(n).
A* Search
Operation:
- First search routes most likely to lead to destination.
- This goes beyond best-first search, as it also considers the distance travelled so far.
- Maintain a priority queue of traversed vertices (open set/fringe). Low f(n) corresponds to high priority.
- At each step, remove node with lowest f from queue, update the f (and g) values of their neighbours, and add neighbours to the queue.
- Stop when a goal node has a value f lower than any other nodes in the queue, or queue is empty.
A* Search
Important remarks:
- Remember to set g(n) = 0 when n is a goal.
- To reconstruct the path, each node must keep track of its predecessor.
- You may want to perform some pre-processing on the graph at the start of the simulation (e.g. build the equivalent complete graph), to improve efficiency.
Example
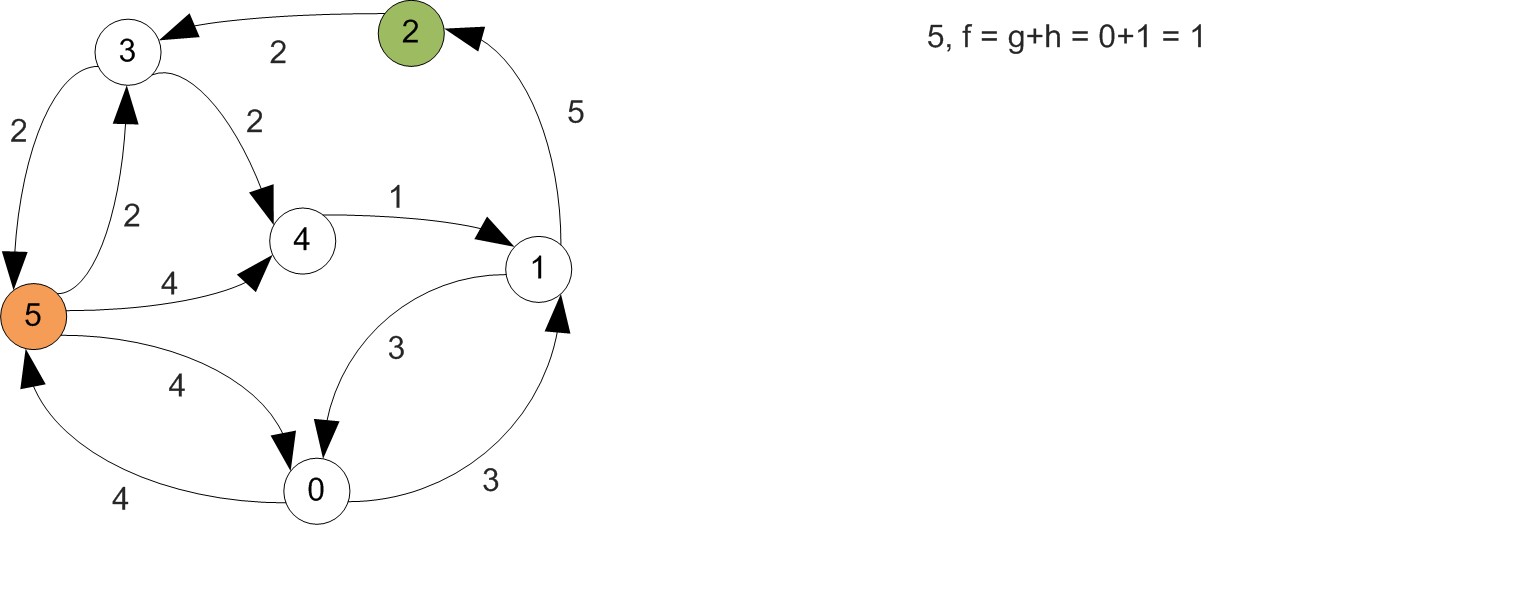
Example
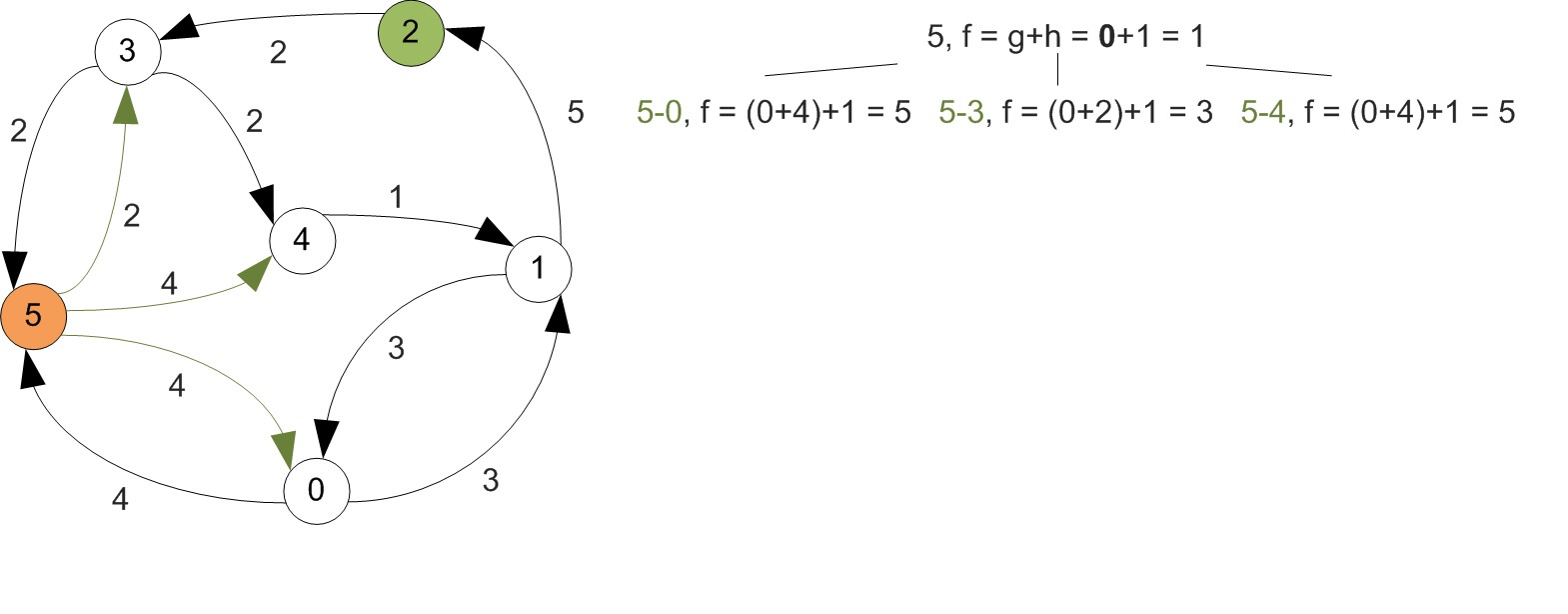
Example
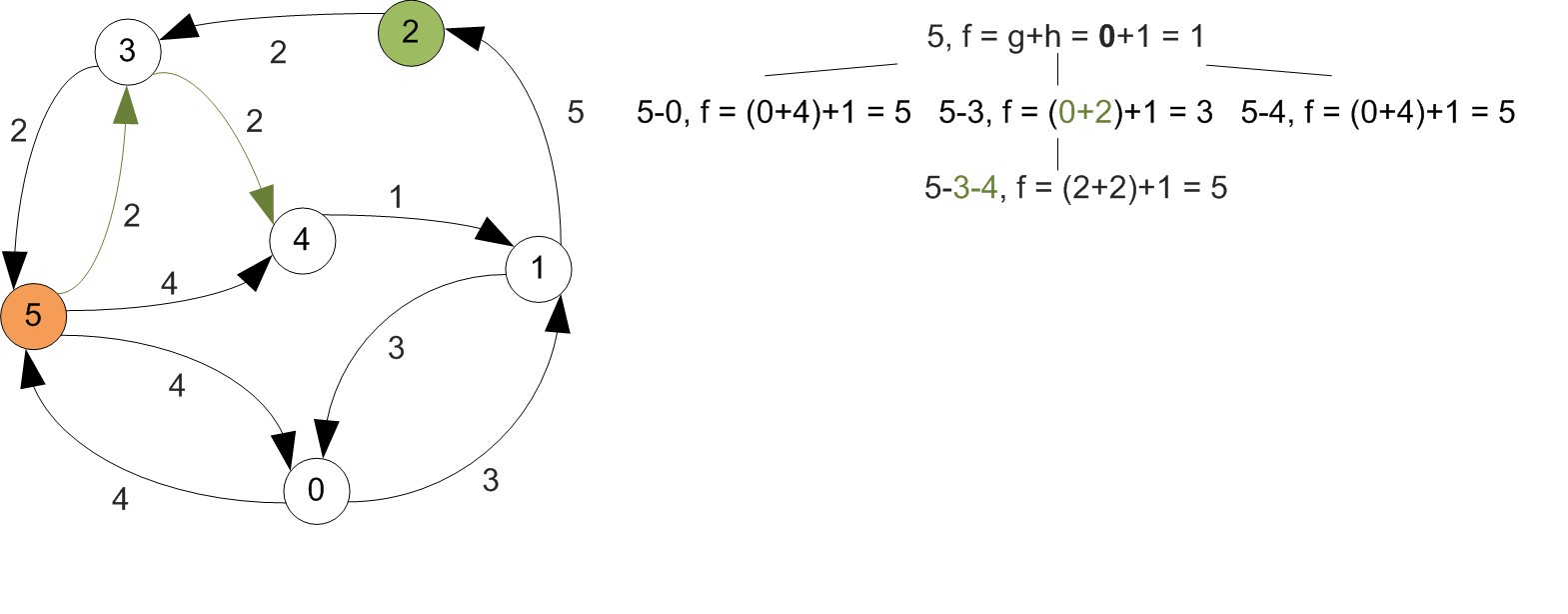
Example
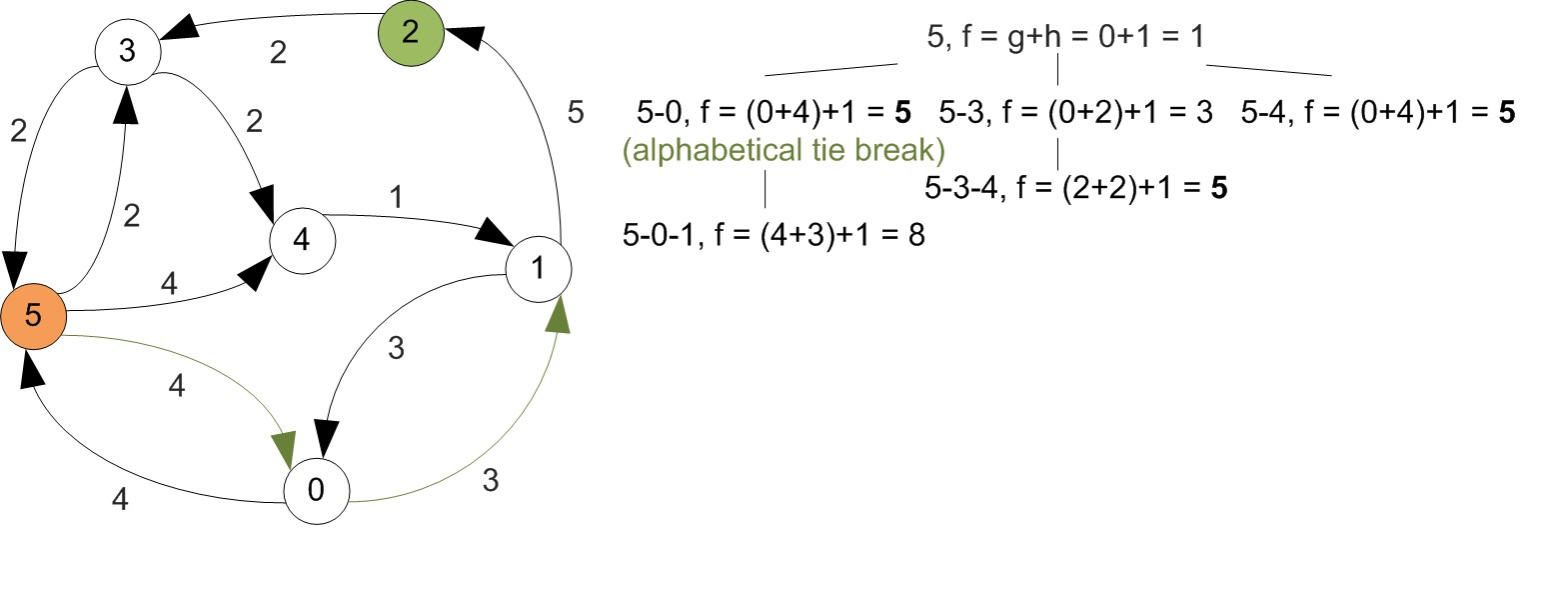
Example
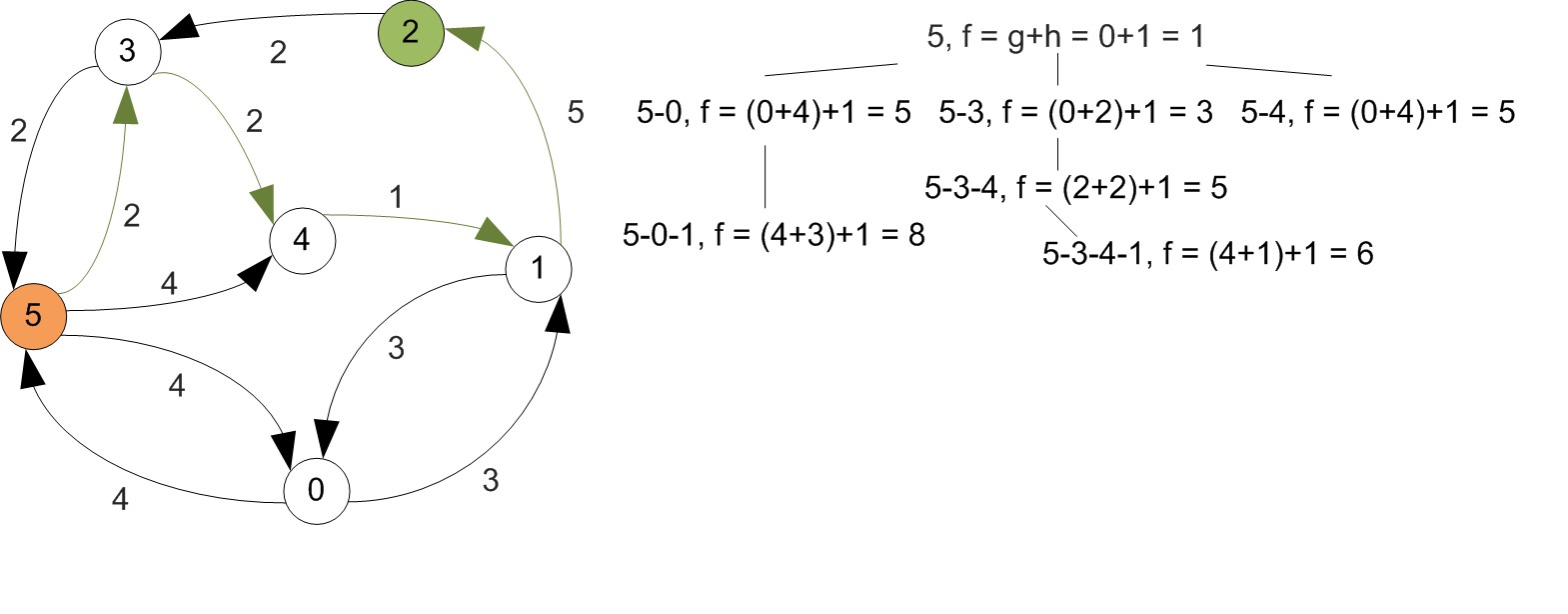
Example
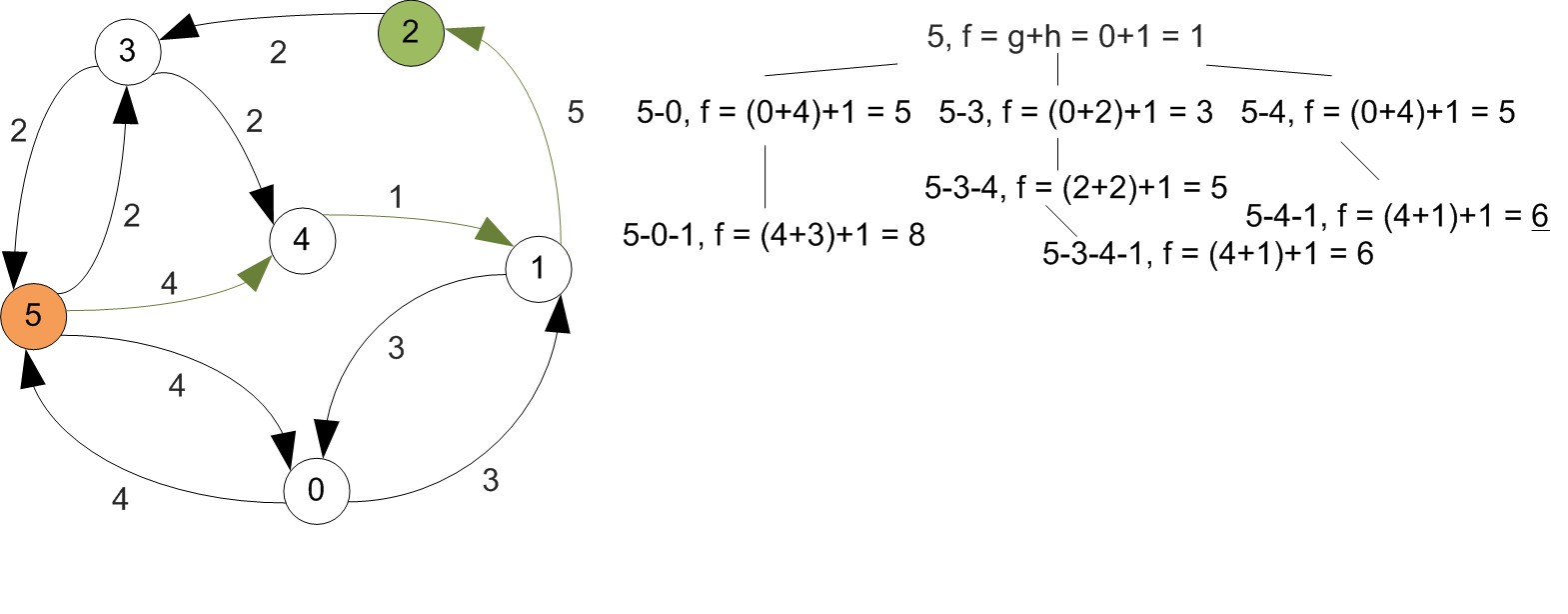
Example
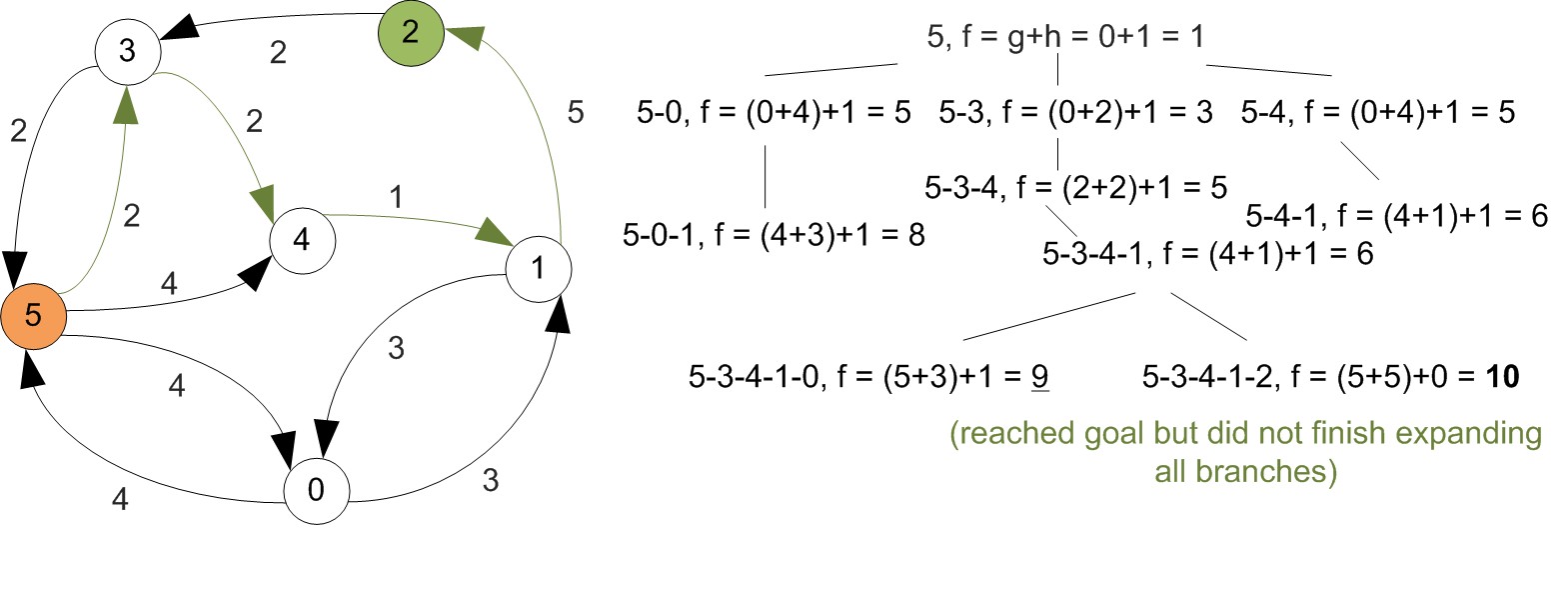
Example
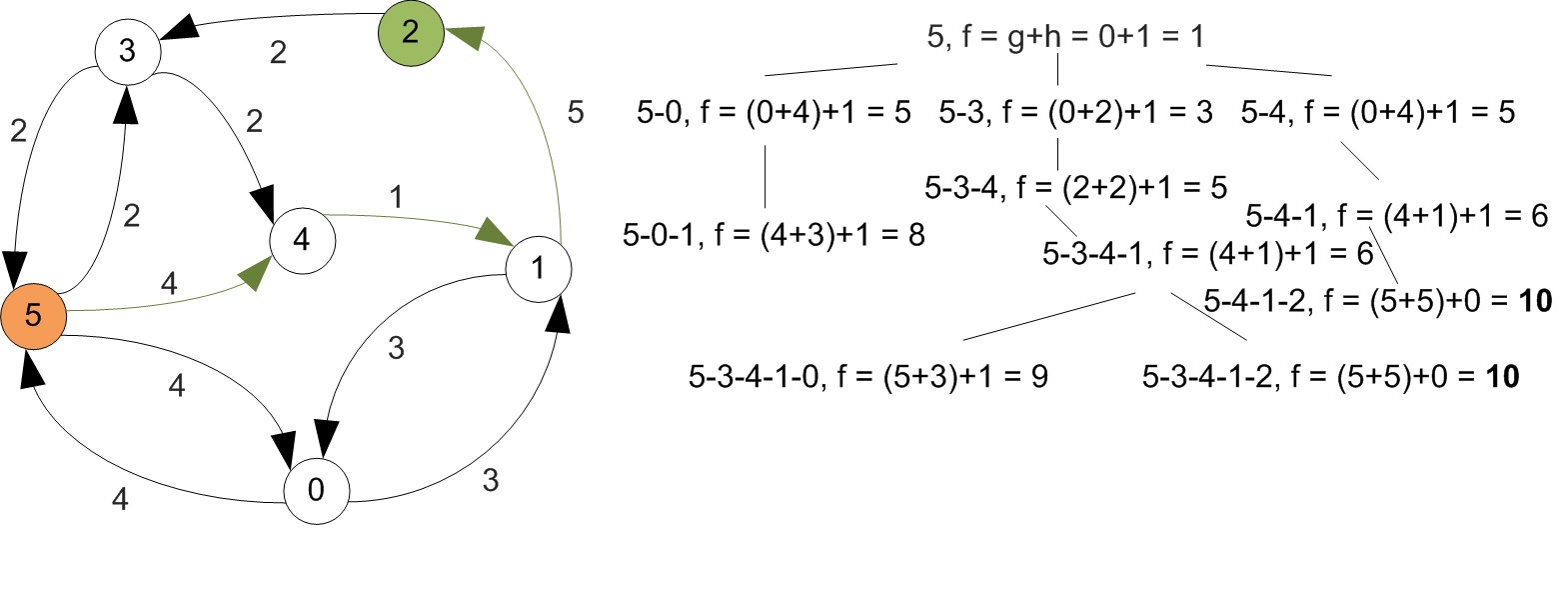
Example
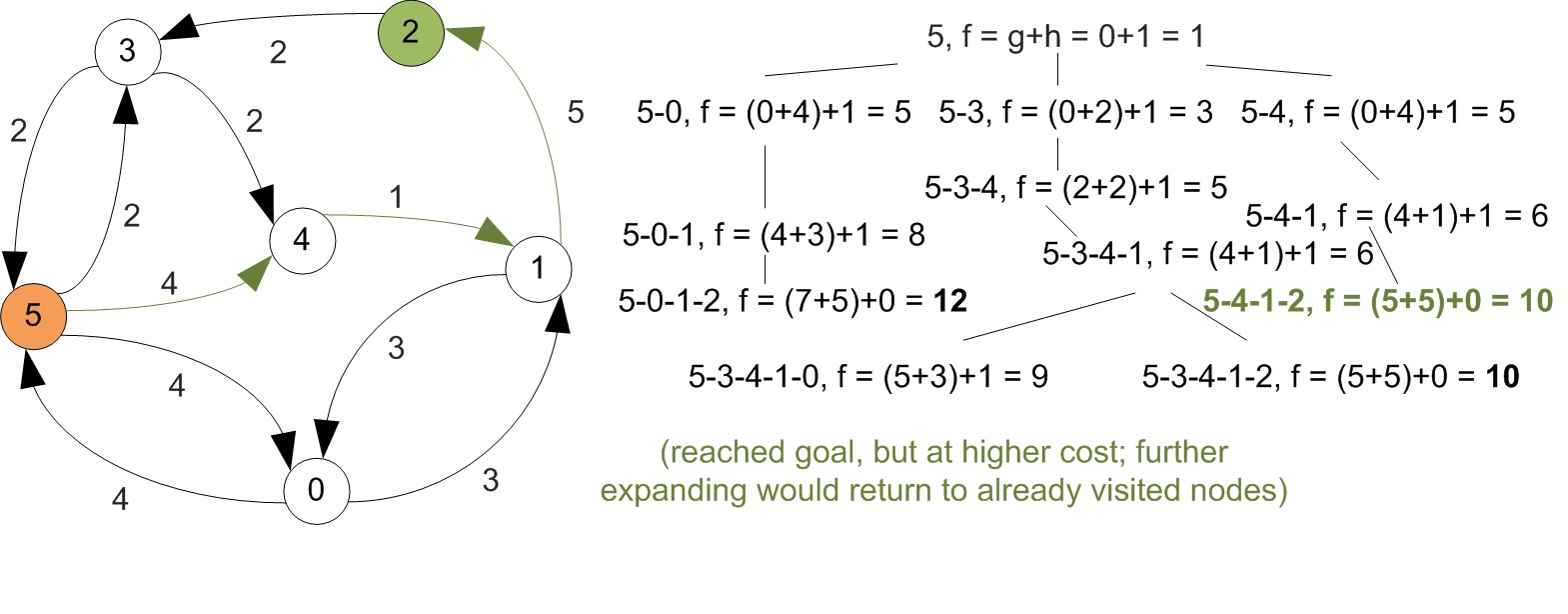
A* Search
Optimising the execution time is possible by working with a so called closed list:
- Start with an empty list.
- Add the nodes that have been expanded to the closed list.
- Do not explore other branches of a node that is already in the closed list.
Pseudo-code
create closed list; initialise empty
create open list of vertices we currently work on; initialise with source
while (goal not reached) {
consider best node in open list (lowest f value)
if (goal reached) {
done, return;
} else {
move current node to closed list and examine all its neighbours
for (each neighbour) {
if (in closed list current g value is lower) {
update neighbour with the new, lower, g value
change neighbour's parent to current node
} else if (neighbour in open list and current g value is lower) {
update neighbour with the new, lower, g value
change neighbour's parent to current node
} else { // neighbour in neither open or closed list
add neighbour to open list and set its g value
}
}
}
}
Review of Part 1
Submissions
- 36 out of 82 students submitted at least something.
- That's 44% submission rate –was expecting something slightly above 50%.
- Many of you did not ask any explicit questions nor highlighted any aspects on which you wanted feedback.
- A couple of submissions did not compile!
Multiple Files
- There seems to be a preference for using a relatively large number of files, given the small size of this project.
- There is nothing wrong with that, but pay attention to memory management.
- Using more/less files will not be penalised – just explain why you chose to implement things in a certain way.
- If refactoring is a reason, do emphasize that.
The READMEs
- Ranged from very basic ones, containing a couple of lines, to very detailed ones.
- Most of them explained how to build and execute the simulator, which is good. For Part 2 submit a makefile.
- Some acknowledged the limitations of the code and problems known at the time of submission.
- Some did not state explicitly at which stage of the development they were.
- Some did not submit a README – you will be losing points if this happens for Part 2.
Random Goodness
- “I was pushing the submission to the last possible moment, in (vain) hope that I will be able to debug the program. ”
Random Not-So-Goodness
- Low-level coding decisions:
- Prone to change and you will forget to update the README
- Should be in comments in the source code file concerned – some code lacked commenting altogether.
- High-level structure: you are more likely to remember to change the README in case of a major re-structuring.
Random Not-So-Goodness
- Make sure you read carefully the requirements
- On one occasion the first command line parameter was not the input script, but a keyword that introduced the input script.
- Although working to some extent, some did not implement any command line parsing at all.
- One submission was prompting the user for input after the execution started – remember that your code will be automatically tested.
Refactoring
- Only a small number of READMEs contained mentions of refactoring,
- Both with reference to future refactoring:
- Either promising to refactor later or
- Done a good bit of refactoring already, but planning to do more.
- It was still early days; however, refactoring is something you should be trying to do constantly.
Invalid Input
- Try to think of exceptions which you really do not believe can happen under normal executing conditions.
- The user may simply make some typing errors when producing the input.
- Some parameters may have been given in an order different than the expected one.
- When is this a serious problem?
- Distinguish between warnings/errors where possible.
Invalid Input
- What should you do if you discover you have incomplete information during a simulation run?
- For example, you attempt to retrieve the
noBusesand find that this was not given. - This is not problematic for parsing, because the user may have simply forgotten to specify the fleet size.
- However, if you validate the input before running the simulation, then it really becomes a problem to find you have no buses to schedule during the simulation.
- The simulation should not have been started since the validation should have uncovered the error.
Further checks
- Check the sign of numbers.
- Check whether it is indeed numbers you find when numbers are expected.
- Check if a number has the type you expect (integer/real).
- Be careful with hours/minutes/seconds conversions.
Input scripts
- You have not spend much time authoring input scripts.
- I recently made some examples available, but it is essential that you produce your own test scripts.
- Network size is not the only thing that matters.
- Think of scenarios where e.g. route planning algorithms may have a hard time.
Final Advice
Final Advice (I)
- I said this already, but read the handout carefully again
- Submit a README file and explain your design choices and main building blocks therein, as well as any known bugs, limitations, and requirements not implemented or additional features implemented.
- Include a Makefile. Running 'make' in the root directory of your project should be enough to build an executable.
- Make sure you expect an input script as a command line parameter and check that the one specified by the user actually exists.
Final Advice (II)
- Do not prompt the user for input.
- Implement a parser. If you do not manage to get this working, not much can be tested.
- Conform to the output specification (remember the automated testing).
- Build a set of tests and submit them as evidence of testing. Explain briefly what you tested for with each.
- Comment your code, though not excessively.
- Clean up your code, have consistent spacing, remove commented out blocks.
In Summary...
- Strive at least for a half decent simulator.
- Make sure it compiles and runs on DiCE, and it does not require super-user privileges!
- As a backup plan, have at least a planning algorithm that works in a taxi fashion (one bus allocated to each request, if possible).
- There is no minimum page requirement for the report: "Demonstrate you are familiar with discrete-event stochastic simulations, you can interpret the output, understand the system’s performance and you can present your results in a clear and concise manner."