Introduction
Computer Science Large Practical
Organisational Matters
- Me: Allan Clark
- Email: a.d.clark@ed.ac.uk
- Website: http://www.inf.ed.ac.uk/teaching/courses/cslp/
- There is one lecture per week
- Fridays at 12:10-13:00
- At 7 Bristo Square - Map lecture theatre 4
- Coursework: Accounts for 100% of your mark for the course
- No required textbook
- No scheduled office hours, please email at any time
Restrictions
- CSLP is a third-year undergraduate course only available to third-year undergraduate students.
- CSLP is not available to visiting undergraduate students, or to fourth-year undergraduate students and MSc students, who have their own individual projects.
- Third-year undergraduate students should choose at most one
large practical, as allowed by their degree regulations.
- Computer Science, Software Engineering and Artificial Intelligence large practicals
- On most degrees a large practical is compulsory.
- On some degrees (typically combined Honours) you can do the System Design Project instead, or additionally.
- See the Degree Programme Tables (DPT) in the Degree Regulations and Programmes of Study (DRPS) for your degree for clarification.
The Computer Science Large Practical Requirement
- The requirement for the Computer Science Large Practical is to create a command-line application.
- The purpose of the application is to implement a
stochastic, discrete-event, discrete-state, continuous time simulator
- I'll explain these words further below
- This will simulate the progression of buses through a network of stops specified by the input
- The output will be the sequence of events that have been simulated as well as some summary statistics.
- The input and output formats are specified in the coursework handout together with several other requirements
- It is your responsibility to read the requirements carefully
Today's Lecture
- Today I will discuss:
- Context for the practical, timing and deadlines
- Motivation for the simulation of a bus network
- The simulation algorithm used
- The main requirements for the practical
- Kinds of simulators and in particular the kind that you are being asked to produce
Context
- So far most of your practicals have been small exercises
- Next year, you will undertake an honours project
- This practical represents something in between those
- It is larger and less rigidly defined than your previous course works
- It is more rigidly defined and smaller than your honours project
- The CSLP tries to prepare you for
- The System Design Project (in the second semester)
- The Individual Project (in fourth year).
Requirements
- The requirements are more realistic than most coursework
- But still a little contrived in order to allow for grading
- There is:
- a set of requirements (rather than a specification);
- a design element to the course; and
- more scope for creativity.
How much time should I spend?
- 100 hours, all in Semester 1, of which
- 8 hours lecture/demonstrating
- 92 hours practical work, of which
- 70 hours non-timetabled assessed assignments
- 22 hours private study/reading/other
How much time is that really?
- There are 13 weeks remaining in semester 1 (Weeks 2 to 14)
- 7 * 13 = 91 hours
- So you can think of it as 7 hours per week in the first semester
- This could be one hour a day including weekends
- You could work 7 hours in a single day
- for example work 9:00-17:00 with an hour for lunch
Managing your time
It is unlikely that you will want to arrange your work on your large practical as one day where you do nothing else, but one day per week all semester is the amount of work that you should do for the course.
Scheduling work
Course lecturers have been asked not to let deadlines overlap Weeks 11-14 because students are expected to be concentrating on their large practical in that time.Deadlines
The Computer Science Large Practical is split in two parts:- Part 1
- Deadline:Thursday 24th October, 2013 at 16:00
- Part 1 is zero-weighted: it is just for feedback.
- Part 2
- Deadline: Thursday 19th December, 2013 at 16:00
- Part 2 is worth 100% of the marks.
Scheduling work
- It is not necessary to keep working on the project right up to the deadline.
- For example, if you are travelling home for Christmas you might wish to submit the project early.
- In this case you need to ensure that you start the project early.
- The coursework submission is electronic so it is
possible to submit remotely.
- But you must make sure that your submission works as expected on DiCE
- This might be easier to do locally
- But see working remotely and in-beta remote graphical login
Early submission credit
- In order to motivate good project management, planning, and efficient software development, the CSLP reserves marks above 90% for work which is submitted early (specifically, one week before the deadline for Part 2).
- Work submitted less than a week before the deadline does not qualify as an early submission, and the mark for this work will be capped at 90%. Thus, the mark may be 90%, but it may not be higher than this.
- Regardless of when it is submitted, every submission is assessed in exactly the same way, but submissions which attract a mark of above 90% which were not submitted early have this mark brought down to 90%.
Early submission credit
- Question:
- Can I submit both an early submission version and a version for the end deadline and have the marks for whichever is highest?
- Answer:
- No. Before the early submission deadline you have to choose whether or not you are going to hope for a mark above 90% then, or have an extra week to accumulate more marks up to 90%. The submission marked will be the latest one made before the deadline. Hence if you submit both before and after the early submission deadline, only the last submission will be marked and it will be capped to 90%.
Extensions
- Do not ask me for an extension as I cannot grant them
- The correct place is the ITO who will pass this on to the year organiser (Vijay Nagrajan)
- Link to the policy on late coursework submission
Implementation Language
- You may choose whichever programming language you deem most suitable.
However:
- Your application should compile and run on DiCE
- Here is an obvious list of languages which should work on DiCE without any problems: C, C++, C#, Haskell, Java, Python, Objective-C, Ruby. However care should be taken with versions.
- If you wish to use something else it would probably be prudent to ask me first.
Implementation Language
- You may choose whichever programming language you deem most suitable.
However:
- Your application should compile and run on DiCE
- I am even open to installing a compiler and/or runtime on my DiCE installation but this is entirely at my discretion.
- It is up to you to choose a suitable language
- Your choice will not be judged, however if you choose poorly, this will not be reflected in more lenient marking.
- Whatever choice you make, you must live with
Source Code Control
- For this project source code control is mandatory
- You will have to use the
git- This is somewhat realistic
- Any project you join will likely already have some form of source code control set up which you will have to learn to use rather than any system you might already be familiar with
- See the git homepage
Source Code Control
- The practical is not looking for you to become an expert in
git - You will not need to be able to perform complicated branches, merges or rebasing
- This is, afterall, an individual practical
- What is key, is that your commits are appropriate:
- Small frequent commits of single units of work
- Clear, coherent and unique commit messages
Getting Started
Do this today.
$ mkdir simulator
$ cd simulator
$ git init
$ editor README.md
$ git add README.md
$ git commit -m "Initial commit including a README"
Code Sharing Sites
- Code sharing sites are a great resource but please refrain from using
them for this practical. This is an individual practical so code sharing
is not allowed. Even if you are not the one benefiting.
- This is a bit of a shame, but again somewhat realistic
- It is at least somewhat likely that in the future you will be unable to publicly share all of the code you produce at your place of employment.
Motivation - Simulators
- It is common in both academic and industrial contexts to author some kind of simulator
- Simulators can save time, money, effort and even lives
- Simulators allow the very low cost running of experiments that might otherwise be infeasible
- However, the catch is that unless the simulator is an appropriate model for the real system under investigation, the results may be worthless
Middle-lane Hogging


A recent BBC news article on the proposed government crackdown on middle-lane hoggers
Middle-lane Hogging
- The government recently announced a ‘crackdown’ on middle-lane hoggers on motorways
- Is this a money-making scheme? Is it a publicity scheme? Is it truly a worthwhile policy?
- Difficult to know. A first step is deciding whether or not middle-lane hoggers cause significant delay and/or danger
- It's difficult to gather data, how would you know how many people are middle-lane hogging?
Middle-lane Hogging
- Even if you could count them, how could change this number?
- Even if you could change (or wait for them to change) how could keep all other conditions the same?
- With simulation it's possible to do both
- Hence with simulation this is the first step towards answering the question of how much middle-lane hoggers cost
Why Simulate Buses?
- City based transport is a huge problem in many parts of the world
- Different people wish for different outcomes:
- Passengers do not wish to wait long for a bus, they hope buses are not too full
- Bus companies do not like empty buses, and would rather run as few as possible (whilst still having the same number of passengers)
- Citizens wish for less congestion and pollution
Why Simulate Buses?
- Some of these are complementary some are contradictory
- With simulation we can try out different policy ideas and see which desires are affected
- Only recently however have we begun to be able to obtain large amounts of related data: times, queues, passengers etc.
- In this practical we will be interested in bus queues at bus stops
Why care about Bus Queues?
- In this practical we are mostly going to be focused on the queue of buses at each bus stop
- NOTE that is the queue of buses and not the queue of passengers
- The queue of passengers at a bus stop is almost irrelevant
- Provided a passenger does get on the next bus, it doesn't really matter when, and the whole queue is dequeued at more or less the same time
- However, if a bus arrives at a bus stop, only to find a previous bus currently using it (to board and disembark passengers) the new bus is stuck waiting doing nothing productive
- This is bad, for pretty much every player in the game
Why care about Bus Queues?
- One possibility is to change the charging model
- It takes time for passengers to board the bus because they all have to pay the driver
- Alternatively we could move to a pre-pay scheme, with inspectors that check people have valid tickets and dispense fines for offenders
- Or simply have an extra conductor on every bus who deals with payment
- In order to evaluate these possibilities we first need to work out how much of a problem is bus queueing
Your Simulator
- Your simulator will be a command-line application
- It will accept a text file with a description of the input network
- This text file specifies, the routes, buses, rates and other entities required to simulate a given bus network
- It should output a list of events which occur
- The strict formats for both input and output are described in the coursework handout
- In the second part you will analyse the sequence of events to obtain statistics about the input network
Simulation Algorithm
The underlying simulation algorithm is itself quite simple:
WHILE {time ≤ max time}
Choose an event and time for it based on the current state
Update the state based on the event
ENDWHILE
Simulation Algorithm
The underlying simulation algorithm is itself quite simple:
WHILE {time ≤ max time}
From the current state calculate the set of events which may occur
total rate ← the sum of the rates of those events
delay ← choose a delay based on the total rate
event ← choose probabilistically from those events
modify the state of the system based on the chosen event
time ← time + delay
ENDWHILE
Simulation Algorithm
WHILE {time ≤ max time}
...
delay ← choose a delay based on the total rate
...
ENDWHILE
- To choose a delay we sample from the exponential distribution
- I'll say more about this later, but for now it can be done by:
- −(mean) ∗ log(random(0.0, 1.0))
- Where mean is the average delay, which is the reciprocal of the total rate
Simulation Algorithm
WHILE {time ≤ max time}
...
event ← choose probabilistically from those events
...
ENDWHILE
- Similarly this means with respect to the rates of those events
- So if two events a and b are enabled at rates 2.0 and 1.0 respectively, then:
- Choose in such a way that a is twice as likely as b to be chosen
Components of the Simulation
- Input network description:
- Stops
- Routes
- Roads
- Dynamic state components:
- Buses
- Passengers
Components of the Simulation
Stops
- Stops have a queue of buses
- And a set of passengers waiting to board buses which pass through the stop
- Passengers can only board the bus at the head of the queue
Components of the Simulation
Routes
- Routes consist of a sequence of stops
- Routes are implicitly circular in that the next stop after the last stop is the first stop
Components of the Simulation
Roads
- Between any two stops which occur adjacently on at least one route there is a road
- Including between the last and first stops of each route
- Each road has an average rate at which buses can traverse it
- We simplify things by saying buses may traverse a road at the same speed regardless of how many buses are on that road
Components of the Simulation
Buses
- Each bus is associated with exactly one route, but there may be many buses associated with that route
- Each bus has a number unique among the buses which traverse the same route
- Hence a bus can be uniquely identified by its route and number
- The bus 31.4 is the fifth bus on route 31
- Each bus has an associated capacity
Components of the Simulation
Buses
- A bus is always either at a stop or on a road between stops
- At a stop it might not be at the head of the queue but behind other buses
- A bus should not leave a stop if there are passengers wishing to board or disembark from it
- A bus may leave a stop if there are waiting passengers if:
- The bus is full, and
- No passenger on board wishes to disembark
Components of the Simulation
Passengers
- Each passenger has an origin stop and a destination stop
- At any one time a passenger is either waiting at a stop or on board a particular bus
- New passengers enter the simulation at any time at a specified rate
- New passengers are randomly assigned to origin and destination stops but it must be a valid route
Components of the Simulation
Events
- Your simulator will produce a sequence of events
- A bus may arrive at a stop
- A bus may leave a stop
- A passenger may board a bus
- A passenger may disembark from a bus
- A new passenger may enter the simulation at a particular stop
Components of the Simulation
Events
- Your simulator will produce a sequence of events looking like:
Bus ‹bus› arrives at stop ‹stop› at time ‹time› Bus ‹bus› leaves stop ‹stop› at time ‹time› Passenger boards bus ‹bus› at stop ‹stop› with destination ‹stop› at time ‹time› Passenger disembarks bus ‹bus› at stop ‹stop› at time ‹time› A new passenger enters at stop ‹stop› with destination ‹stop› at time ‹time›
Components of the Simulation
Events
- In reality of course you will replace the ‹bus›, ‹stop› and ‹time› parts with real values:
Bus 1.2 leaves stop 3 at time 99.498 Bus 1.2 arrives at stop 4 at time 99.692- This is valid output in the sense that it is formatted correctly
- It may be invalid for other reasons, for example route 1 may not pass through stop 3
Part One and Part Two
- For part one, you need only have a working simulator
- For part two, there are additional requirements:
- Output of analysis, such as average number of queued buses
- Experimentation support, varying rates to see how those affect the network
- Parameter Optimisation, finding the best rates
- Validation, checking that the input is valid
- These are all specified in the coursework handout
Coursework Handout
- The above is a brief summary of the major components of the simulation
- It is no substitute for reading the coursework handout
- Available at: www.inf.ed.ac.uk/teaching/courses/cslp/coursework/cslp-2013.pdf
Definitions
- In the requirements I stated that your simulator will be a:
- stochastic,
- discrete event, discrete state,
- continuous time
- I will now define these terms
I finished the first lecture here.
Stochasticity
- Don't worry, it essentially just means “non-deterministic”
- This means that if you run your simulator more than once you might not get the same results
- This also means that you can use your simulator to obtain some statistics
- Remember, these are statistics about the model:
- You hope that the real system exhibits behaviour with similar statistics
Discrete Events, Discrete State
- It is possible to have discrete events and continuous state or vice-versa
- But is common that either both are discrete or both continuous
- This means that each event either takes place or it does not, there is no aggregation of multiple events
- This generally means that the state could be encoded as an integer
- Usually it is encoded as a set of integers, possibly coded as a different data types
- This means there is no ‘fluid-flow’
- An entity, such as a person, is in a particular place, and cannot be divided up into fractions of a person in multiple places at once
Discrete State vs Continuous State
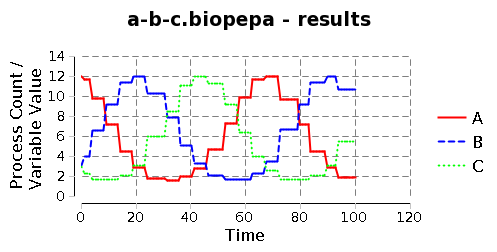
Continuous Time
- Some simulations use a discrete number of time points:
- Days, Weeks, Months, Years
- Can also be logical time points:
- Moves in a board game
- Communications in a protocol
- These would be examples of discrete time simulators
- Your task is to write a continuous time simulator
- An event could therefore happen at any particular time
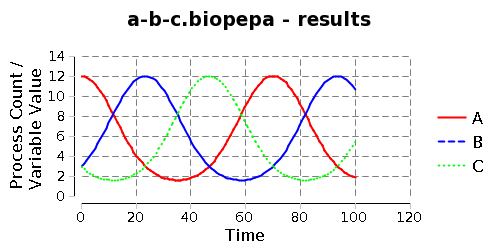
The Exponential Distribution


- Both graphs describe probability X at time x related to an event which occurs at a rate of λ
- The left graph depicts the probability density function
- The right graph depicts the cumulative distribution function
The Exponential Distribution
- The PDF is given by: F(x,λ) = λe-λx ∀ x > 0
- Describes the relative likelihood that an event with rate λ occurs at time x
- A time point is infinitesimally small
- The integral of this gives the probability that it occurs within two time bounds
- But you can largely ignore all this
The Exponential Distribution
- The CDF is given by: F(x,λ) = 1 - e-λx ∀ x > 0
- So if something happens at a rate of 0.5 per unit of time, then the probability that we will observe it occurring within 1 time unit is: F(1, 0.5) = 1 - e0.5*1 = 0.393
- The exponential distribution has a couple of excellent properties for the use of simulation
The Exponential Distribution
- The mean or expected value is given by the reciprocal of the rate parameter
- In plain English this means that if something occurs at rate r then we can expect to wait time units on average to see each occurrence
- If something occurs 7 times per week, you can expect to wait of a week (or a full 24 hours) on average between each occurrence
The Exponential Distribution
- Even better it is memoryless
- Formally:
Pr(X > s + t | X > s) = Pr(X > t)
s, t > 0 - Less formally: The time that we can expect to wait for the next occurrence of some (exponentially distributed) event, is unaffected by how long we have already been waiting for it
- In the 7 times a week example, if it has been 24 hours since the last occurrence, the expected additional time I have to wait is still 24 hours
- A quick note, don't confuse these two properties:
- Correct Pr(X > 100 | X > 80) = Pr(X > 20)
- Incorrect Pr(X > 100 | X > 80) = Pr(X > 100)
The Exponential Distribution
Memorylessness
- Why is this so great?
- During simulation, the simulator can choose an event based on the current rates of possible events
- Those rates are based on the current state of the simulation
- As a result of firing that event, the global state of the simulation changes
- However local states may not have changed, in our case for example there may still be two buses at stop 8
- When we choose the next event, we can simply re-calculate the rates of possible events based on the new state of the simulation
- We need not remember how long a particular event has been enabled for
Your Simulators
- Will be Discrete event simulators
- Will be Discrete state simulators
- Will be Continuous time simulators
- Will make use of the exponential distribution
Coursework Handout
- Do not forget to read the coursework handout
- Available at: www.inf.ed.ac.uk/teaching/courses/cslp/coursework/cslp-2013.pdf
Any Questions?
Source Code Control
Computer Science Large Practical
Quick Introduction to SCC
- Source Code Control or Version Control Software is used for two main
purposes:
- To record a history of the changes to the source code that have lead to the current version
- To allow multiple developers to develop the same code base concurrently and merge their changes
- Since this is an individual practical we will concentrate on the first of these two
A common error
/*
* 12/26/93 (seiwald) - allow NOTIME targets to be expanded via $(<), $(>)
* 01/04/94 (seiwald) - print all targets, bounded, when tracing commands
* 12/20/94 (seiwald) - NOTIME renamed NOTFILE.
* 12/17/02 (seiwald) - new copysettings() to protect target-specific vars
* 01/03/03 (seiwald) - T_FATE_NEWER once again gets set with missing parent
* 01/14/03 (seiwald) - fix includes fix with new internal includes TARGET
* 04/04/03 (seiwald) - fix INTERNAL node binding to avoid T_BIND_PARENTS
*/
Basic Source Code Control
As I stated previously the first thing to do is to initialise your repository
$ mkdir simulator
$ cd simulator
$ git init
$ editor README.md
$ git add README.md
$ git commit -m "Initial commit including a README"
The main point
- After each portion of work, commit to the repository what you have done
- Everything you have done since your last commit, is not recorded
- You can see what has changed since your last commit, with the status and diff commands:
$ git status
# On branch master
nothing to commit (working directory clean)
Staging and Committing
- When you commit, you do not have to record all of your recent changes. Only changes which have been staged will be recorded
- You stage those changes with the
git addcommand. - Here I have modified a file but not staged it
$ editor README.md
$ git status
# On branch master
# Changed but not updated:
# (use "git add ‹file›..." to update what will be committed)
# (use "git checkout -- ‹file›..." to discard changes in working directory)
#
# modified: README.md
#
no changes added to commit (use "git add" and/or "git commit -a")
Unrecorded and Unstaged Changes
- A
git diffat this point will tell me the changes I have made that have not been committed or staged
$ git diff
diff --git a/README.md b/README.md
index 9039fda..eb8a1a2 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,2 @@
This is a stochastic simulator.
+It is a discrete event/state, continuous time simulator.
To Add is to Stage
- If I stage that modification and then ask for the status I will be told that there are staged changes waiting to be committed
- To stage the changes in a file use
git add
$ git add README.md
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD ‹file›..." to unstage)
#
# modified: README.md
#
Viewing Staged Changes
- At this point
git diffis empty because there are no changes that are not either committed or staged - Adding
--stagedwill show differences which have been staged but not committed
$ git diff # outputs nothing
$ git diff --staged
diff --git a/README.md b/README.md
index 9039fda..eb8a1a2 100644
--- a/README.md
+++ b/README.md
@@ -1 +1,2 @@
This is a stochastic simulator.
+It is a discrete event/state, continuous time simulator.
New Files
- Creating a new file causes git to notice there is a file which is not yet tracked by the repository
- At this point it is treated equivalently to an unstaged/uncommitted change
$ editor mycode.mylang
$ git status
# On branch master
# Changes to be committed:
# (use "git reset HEAD ‹file›..." to unstage)
#
# modified: README.md
#
# Untracked files:
# (use "git add ‹file›..." to include in what will be committed)
#
# mycode.mylang
New Files
- Slightly tricky,
git addis also used to tell git to start tracking a new file - Once done, the creation is treated exactly as if you were modifying an existing file
- The addition of the file is now treated as a staged but uncommitted change
$ git add mycode.mylang
# On branch master
# Changes to be committed:
# (use "git reset HEAD ‹file›..." to unstage)
#
# modified: README.md
# new file: mycode.mylang
#
Committing
- Once you have staged all the changes you wish to record,
use
git committo record them - Give a useful message to the commit
$ git commit -m "Added more to the readme and started the implementation"
[master a3a0ed9] Added more to the readme and started the implementation
2 files changed, 2 insertions(+), 0 deletions(-)
create mode 100644 mycode.mylang
A Clean Repository Feels Good
- After a commit, you can take the status, in this case there are no changes
- In general though there might be some if you did not stage all of your changes
$ git status
# On branch master
nothing to commit (working directory clean)
Finally git log
- The
git logcommand lists all your commits and their messages
$ git log
commit a3a0ed90bc90e601aca8cc9736827fdd05c97f8d
Author: Allan Clark ‹author email›
Date: Wed Sep 25 10:26:57 2013 +0100
Added more to the readme and started the implementation
commit 22de604267645e0485afa7202dd601d7c64c857c
Author: Allan Clark ‹author email›
Date: Wed Sep 25 10:17:45 2013 +0100
Initial commit
More on the Web
- Clearly this was a very short introduction
- More can be found at the git book online at:
- And countless other websites
The Point
- Don't forget that the point of all this is to record a history of changes to the code
- This allows you to revert to previous versions in order to locate when a bug was introduced
- This can help greatly in locating the source of a bug
- This history of changes also helps other people (including your future self) understand why the code is the way it is
- This is very helpful when you wish to change something without breaking anything
Debugging Help
- Suppose you write some new test input, try it out, and find that it causes your application to crash
do{ revert to previous commit/version
re-compile and re-run your new test
flag = does the program still crash
} while(flag)
Git Blame
Not relevant for this individual project, but when it comes time to do your System Design Project, keep in mind git blame:
$ git blame sbsi_numeric_devel/Template/main_Model.c
352c44 (ntsorman 2010-07-08 14:03:43 +0000 5) #ifndef NO_UCF
352c44 (ntsorman 2010-07-08 14:03:43 +0000 6) #include
352c44 (ntsorman 2010-07-08 14:03:43 +0000 7) #endif
352c44 (ntsorman 2010-07-08 14:03:43 +0000 8)
815381 (allanderek 2011-08-30 13:24:45 +0000 9) #include "MainOptimiseTemplate"
352c44 (ntsorman 2010-07-08 14:03:43 +0000 10)
Committing
- When and what to commit?
- The easy answer is it should be “one unit of work”
- Defining one unit of work is difficult but if you have to use the word ‘and’ to describe it, there is a good chance you have more than one commit there
- Note that my previous example was therefore bad
$ git commit -m "Added more to the readme and started the implementation" [master a3a0ed9] Added more to the readme and started the implementation 2 files changed, 2 insertions(+), 0 deletions(-) create mode 100644 mycode.mylang - It is bad because it is doing two separate things, indicated by the use of the word ‘and’, not because it updates more than one file
Committing
- Your commit should be improving the project. It should be improving
one portion of it:
- The code
- The documentation
- The tests
- And it should be improving that one part in one way:
- Improving functionality
- Improving readability
- Improving maintainability
- Improving performance
XKCD Signal
- XKCD is a popular web comic
- It has an associated IRC channel
- As with many large communities it faced a problem of a large noise to signal ratio
- A large part of the problem is that frequently asked questions are not read and hence re-asked
- Commmon debates are hence frequently re-hashed
XKCD Signal
- In a blog post the xkcd creator outlines a proposal to deal with this
- It has been implemented as the ROBOT9000 bot-moderator
- The rule it enforces is a simple one:
- ”You are not allowed to repeat anything anyone has already said”
XKCD Signal
- You can read about the specifics here
- But some obvious questions arise:
- Question: Isn't this limiting?
- Answer: You're underestimating the versatility of natural language and the sheer number of possible sentences
XKCD Signal
- You can read about the specifics here
- But some obvious questions arise:
- Question: Can't I just game it by tagging extra nonsense on?
- Answer: Yes, but the focus is on dealing with unwitting noise generators. Those who are actively attempting to destroy the conversation can be otherwise banned.
XKCD Signal
- You can read about the specifics here
- But some obvious questions arise:
- Question:What happens if I just want to answer someone with a yes/no?
- Answer: Expand slightly e.g. “I agree, ... because ...”
What has this got to do with SCC?
- A persistent problem is the lack of meaningful commit messages
- “fixed a bug”
- “More work”
- “Fixes.”
- “Updates”
- “big commit of all outstanding changes”
- “commit everything”
- “commit”
What has this got to do with SCC?
- I hope to give some good advice on this writing good commit messages
- But it is notoriously difficult to enforce
- One could easily enforce a minimum length, but this would only solve part of the problem and in some cases would not actually be appropriate
- A sneakier idea; copy the “Do not repeat” rule from XKCD-Signal
- “Do not use a commit message which has been used previously”
Non-repeating Commit Messages
- When I say “used previously” do I mean in the same repository?
- Beginner level: yes, I mean in the same repository
- Advanced level: no, I mean in any repository that exists for any project
- It should not really matter, it is hard to accept that a commit message used for an entirely different project is appropriate for your one
Non-repeating Commit Messages
- Said in a whingey voice: “But I really did just fix a typo in the README”
- You can probably expand on that a little
- However, of course some violations of this rule will be worse than others
- Similarly just because you pass this rule, does not mean you have a useful commit message
- Gaming this by adding superfluous characters is definitely wrong
Non-repeating Commit Messages
- In order to check the advanced level I will need a corpus of repositories
- I might use github for this. You certainly should not be repeating a commit message used for an entirely different repository
- But I will at least check your commit messages against all other repositories submitted for this practical
- Bear in mind, you're all implementing the same requirements
More Advice
- The commit message should be a summary of the actual ‘diff’
- Part of the point of the commit message is so that a reader can avoid looking at the actual ‘diff’
- The reader is looking in the history for a reason. Most likely they are trying to find the source of an issue. Help them.
More Advice
- You should at least make clear the purpose of the commit
- Is it?
- A bug fix
- A feature addition
- A conflict resolution between two branches
- Style enhancements
- On what scale? A single fixed spelling error, or reformating all of the code?
- A refactor of some portion of the code
- Addition of a test
- Updating of documentation
- Optimisation
More Advice
- Even once the purpose is described, try to explain the reason for that purpose
- Some times this will be obvious, for example if the purpose of the commit is to fix a bug
- Even then, you may wish to explain why that is fixable now rather than earlier
- Others, really require an associated why. In particular a refactor.
Summary of the Main Advice
- Small frequent commits. Each commit should do one thing
- Ask yourself is it plausible that you might wish to revert some of the
changes in a commit but not all of them?
- If so, you almost certainly have more than one commit's worth of work
- A person looking through your history is most likely looking for the source of a bug, or trying to figure out why a certain bit of code is the way it is. In either case help them.
- Some people branch for any new unit of work. You should at least branch if you start doing two things at once
Micro Commits
- It is possible to commit too little a portion of work
- But for this practical we will ignore that possibility (unless you're clearly gaming the system)
- Just a note: small style enhancements are usually not too small
- “I just fixed a small typo in a comment, no one could possibly wish to revert to
the code before I fixed the typo”
- Probably not, but what are you about to do?
- Someone may well wish to revert to the code immediately after you fixed the typo
Micro Commits
- If you commit code such that the “build is broken”
it is certainly not an appropriate commit
- If the code fails to compile, or has a syntax error (for dynamic languages)
- If this is the case you are likely committing too little
- Though this could also be caused by over-shooting an appropriate commit
- In other words you have 1 and a half commits worth of work
- Or 2 and a half, or X plus 1/y commits worth of work
Branching

Branching
- This occurs in software development frequently
- In particular, you aim to add a new feature only to discover that the supporting code does not support your enhancement
- Hence you need to first improve the supporting code, which may itself depend on supporting code which may itself require modification
- Branching, is the software solution to this problem that most other projects do not have available to them
- Because it is pretty easy to copy the current state of a project and work on the copy and then merge back in the results if the work is successful
Branching - The Basic Idea
When commencing a unit of work:- Begin a branch, this logically copies the current state of the project
- The original branch might be called ‘master’ and the new branch ‘feature’
- Complete your work on the ‘feature’ branch
- When you are happy merge the results back into the ‘master’ branch
Branching - First Reason
- Mid-way through, should you discover that your new feature is ill-conceived,
- or, your approach is unsuitable,
- You can simply revert back to the master branch and try again
- Of course you can revert commits anyway, but this means you're not entirely deleting the failed attempt
- You can also concurrently work on several branches and only throw away the changes you do not want to keep
Branching - Second Reason
Should you discover that there is some other enhancement required before your proposed enhancement can be delivered:- Create a new branch (let's say ‘sub-feature’) from ‘master’
- This new branch does not contain any of the work you have done on ‘feature’
- Complete your requirements on ‘sub-feature’
- Once you are happy, merge those results with ‘master’
- You can now rebase the ‘feature’ branch which essentially pretends that you created it from ‘master’ after the work done on ‘sub-feature’ was merged
Branching
- It is possible to do these steps retrospectively
- But it is easier to stay organised
- One approach is to have a newly named branch for each feature
- This has the advantage that multiple features can be worked upon concurrently
- Usually each feature branch is deleted as soon as it is merged back into ‘master’
- A more lightweight solution is to develop everything on a branch named ‘dev’
- After each commit, merge it back to ‘master’ you then always have a way of creating a new branch from the previous commit
With Regards to Grading
- Advice about branch and rebasing etc. is worthwhile and may help you
- However, I won't be specifically testing you on it
- The main thing I wish to see is appropriate commits, both the work done in a commit and the commit message
- These can be retroactively “fixed up”
- There is no penalty for this. Though I advise that you attempt to render it unnecessary by keeping organised
External Git Advice
- There are literally millions of web pages offering git support and advice
- Go forth and explore
Any Questions?
Languages
Computer Science Large Practical
Language Choice
- I stated that you were free to choose which ever language you wish
- For anyone who has not yet started this lecture may help you decide
- For those of you who have, it probably is not too late to switch
- In any case it won't do you any harm to justify your choice and/or utilise your choice appropriately
Language Choice
Languages come in many varieties, here are some of the distinctions made:- Compiled vs Interpreted
- Strongly typed vs Weakly typed
- Statically type vs Dynamically typed
- Functional vs Imperative
- Object Oriented vs Classless
- Lazy vs Eager
- Managed vs Unmanaged
For the most part these are independent of each other giving us 27 (128) possibilities
Language Choice
- Before I start though, don't forget
- Despite being labelled large, this is a short term project
- As such, it's okay to choose language X because:
- “I know X better than any other language”
Compiled vs Interpreted
- Many languages will claim to be either a “compiled language” or an “interpreted language”
- The distinction is intended to be simple:
- Either the source code is translated into machine code and then run or:
- An interpreter reads the source code and executes each line of code dynamically
Advantages of Interpreters
- An interpreter is a less complicated piece of machinery to implement than is a compiler
- Interpreters are generally more portable than compilers are re-targetable
- An interpreter also works well as a debugger
Advantages of Compilers
- The interpreter need not be installed on users' machines
- The generated machine code is generally less expensive to run than is interpreting the original source code
- Significant and complicated transformations can be implemented in the
compiler, so even if the above were not true, compiled code should
still be faster
- This is because it represents code which has been automatically optimised
Bytecode
- Many language implementations therefore implement something of a compromise
- The language is compiled to a portable bytecode
- This bytecode is then interpreted on the user machines
- Even this compromise solution is further modified with the use of Just In Time compilers
- This is now so common that the distinction between compiled and interpreted languages is debatable
|
|
Small Rebuttal
- “The compiler can perform expensive automatic optimisations that the interpreter cannot”
- However, one might suggest that such expensive optimisations can be performed at the source code level, hence the interpreter can still benefit from them
- But, whilst some transformations can be performed at the source code level, not all can
- Source to source optimisations are not common. Likely because if efficiency is a large factor, then a compiler is used
Compiled/Interpreted Language?
- There is not really any such thing as a “compiled language” or an “interpreted language”
- There are compiler or interpreter implementations
- A language may have one particularly official implementation
- Interpreters are nearly always implemented via some kind of bytecode
- So we only really have compiler implementations, it is just a question of what that compiler targets, physical machines or virtual bytecode machines
Compiled/Interpreted Implementations
- Ocaml has
ocamlbyteandocamlopt - Java is generally compiled to the JVM, but implementations such as gcc-java exist
- C# and some other languages now target the CLR runtime
- Python is generally interpreted but Cython exists (an optimising static compiler)
Compiled vs Interpreted
Conclusion
- The distinction between compiled and interpreted is one of implementation not languages
- However, some language features lend themselves to one more easily than the other
- But, increased runtime sophistication has meant that the line between compiled and interpreted has become increasingly blurred
- Your language choice should probably not focus too heavily on whether the official language implementation is a compiler or an interpreter
Type Systems
- Languages involve expressions which evaluate to values
- It is possible to give a type to those values
- We can then check that operations use values of an appropriate type
- For example we may check that we are not trying to add
a string to an integer:
3 + "hello" - The types may also determine what the operation is:
- Integer addition:
3 + 2 - Floating point addition:
3.0 + 2.0
- Integer addition:
Type Systems
- Some type systems also give types to statements
- For example some type systems determine what exceptions may be raised by a given command (which may be a sequence of commands)
- Some such type systems oblige the user to declare these exceptions
- For our purposes we will concentrate on the typing of expressions/values
Strongly typed vs Weakly typed
- This is often confused as a distinction between statically and dynamically typed languages but this distinction is quite separate
- One can have static-strong, static-weak, dynamic-strong, dynamic-weak
Strongly typed vs Weakly typed
- Strongly: Objects of the wrong, or incompatible types cause an
error:
3 + "5" = error, as seen in C++, Java, Python, Ocaml
- Weakly: Objects of the wrong, or incompatible types are converted:
3 + "5" = "35"in Javascript3 + "5" = 8in PHP, Perl5, Tcl
Advantages of Strong Typing
- When something goes wrong, the error is produced as soon as it is discovered
- This makes it easier to investigate the source of the error
- Additionally, you are less likely to calculate incorrect results
- Often, incorrect results are worse than no results
Advantages of Weak Typing
Uhm?
Advantages of Weak Typing
- Occasionally completing a computation and obtaining a result is better than obtaining no result
- Even if the result you obtain is wrong
- Displaying a web page wrongly is generally better than not displaying it at all
- You can implement this in either a strongly or weakly typed language but it is easier in a weakly typed one
Strong vs Weak Typing
Conclusion
- You're writing a simulator, do you think that any result, no matter how incorrect, is better than no result?
- Most of the advice I will give you here is of the annoyingly non-committal variety
- In this case though, unless there are rather compelling reasons to decide otherwise: use a strongly typed programming language
- But do not confuse weak typing with other type system distinctions, such as nominative, structural, duck typing
Statically typed vs Dynamically typed
- A statically typed language specifies that the typing of expressions should be done before the program is run
- A dynamically typed language specifies that the typing of values should be done whilst the program is run
Statically typed vs Dynamically typed

Source: TIOBE language index
Statically typed vs Dynamically typed
- One reason to type expressions is to aid compilation
- Recall the typing of the operands to an addition operator meant that we could determine what kind of addition is required
- We might also need to know the size of the computed value so that we know where it might be stored
- Obviously, if the purpose of the types is to aid compilation, the type checking will have to be done statically
- More importantly the typing of expressions and values is done to avoid the computation of incorrect results
Advantages of Static Typing
- Type errors are caught before you attempt to run the program
- This means for example that type errors should not occur mid-run on a user's machine
- Even during development, perhaps you have a program that:
- takes seconds to compile,
- minutes/hours to run
- and a type error in the final printing of the result
- Using static types you will be alerted to the type error after the compile
- Using dynamic types you will be alerted at the end of a first run
Advantages of Static Typing
- You may be releasing a library, which isn't “run”
- Of course you should have a test suite with 100% code coverage
- That does not always mean the tests are particularly useful
- What you should have and what you do have are not always the same
- Static typing gives you some kind of guarantee for “free”
Advantages of Dynamic Typing
- Static type checking is necessarily conservative
- This means it will reject some programs that ultimately would not, when run, have resulted in a type error
- During development you can avoid type checking code you know will not be run, this is a subtle point
Example of Subtle Point
Suppose you have a method to create some data type:
void create_character(int initial_health){ ... }
void create_character(int initial_health, Gender gender){ ... }
Example of Subtle Point
Unfortunately calls to this method are spread throughout your code
void restart_game (...){
... create_character(100); ... }
void respawn(...){
... create_character(80); ... }
void duplicate_cheat(...){
... create_character(100); ... }
Example of Subtle Point
With a static compiler you will have no choice but to update each call anyway
void restart_game (...){
... create_character(100, character.current_gender); ... }
void respawn(...){
... create_character(80, character.current_gender); ... }
void duplicate_cheat(...){
... create_character(100, character.current_gender); ... }
Example of Subtle Point
Worse, you might not yet have reasonable values so you just do this:
void restart_game (...){
... create_character(100, None); ... }
void respawn(...){
... create_character(80, None); ... }
void duplicate_cheat(...){
... create_character(100, None); ... }
Example of Subtle Point
void restart_game (...){
... create_character(100, None); ... }
void respawn(...){
... create_character(80, None); ... }
void duplicate_cheat(...){
... create_character(100, None); ... }
create_character
Example of Subtle Point
Some languages have optional parameters or default arguments:
void create_character(int initial_health, Gender gender=Female){ ... }
Two Competing Forces
- When programmers learn static type systems it often feels like you are getting more program correctness for free
- It seems as though it is not quite for free, and that the static type system does hamper productivity in the short term
- It also seems likely that static type systems can save on some kinds of work in the future
- The question is, does short term loss in productivity repay for itself with long term increase in productivity?
Philosophy of Typing
- Just as I suggested that a language can be neither a compiled nor interpreted language it is also something of an implementation issue as to when typing is performed
- However, there is generally a type system attached to each language
- Some type systems are very difficult or even impossible to fully check statically
- Some type systems deliberately ensure that it is possible to statically type check the language
Soft Typing
- Soft typing is something of a compromise between static and dynamic typing
- The idea of soft typing is to statically type as much of the program as is possible
- Where the type system cannot determine that an expression or operation will never cause a type error, it inserts a run-time check
- In this sense a dynamic type system is an extreme example of a soft-typing system that is not very good at determining any expressions which will never produce a type error
Soft Typing
- In a sense many of our supposedly static type systems are in fact soft type systems which need few checks
- Commonly, array indexes are not statically checked to be within the bounds of the size of the array
- Instead a dynamic run-time check is inserted for this purpose
- Additionally cast operations are generally checked at runtime as they cannot be statically checked to be valid
Static Analysers
- When a type is not used by the compiler, then ultimately the static type checker is simply a static analyser
- We can deploy many static analysers
- We can also, omit to run any or all of them during a development run
- Personally, I'm a big fan of static analysers
- Static type systems are no exception, but I think they should be optional
Statically Typed vs Dynamically Typed
Conclusion
- The distinction between statically typed and dynamically typed is in theory one of implementation, but in practice one of language
- The distinction though is softer than some may suggest
- It is more of a gradient than a dichotomy
- For this project, either kind of type system will be fine
- But, whichever choice you make, I recommend making use of additional static analysers
- And, whichever choice you make, you should write some tests
Functional vs Imperative
- This distinction is somewhat disputed
- The main idea is that a functional language computes values of expressions, but does not modify state
- An imperative language is simply a non-functional language, that is, one which allows/encourages the programmer to directly modify state
Functional vs Imperative
- It turns out, that a lot of programs involve a lot of functional computation, with a very small amount of state modification
- Hence, the term functional is often relaxed to include those languages that discourage state modification
- More importantly, such languages, encourage
declarative code.
- That is, code which does not modify the state
Functional Programming
- I tend to describe any language with proper support and syntax for nested, higher-order functions to be functional
- A higher-order function is simply one that:
- Takes one or more functions as parameters
- Returns a function as a result
- In general treating functions as any other kind of value is known as providing first class functions
- If the language also allows nested functions which can access the scope of containing functions, the implementation requires function closures
- The provision of nested, higher-order functions usually encourages declarative programming
Functional Programming
- Languages which entirely forbid state updates I describe as strictly functional
- Even this is a little confusing because some people describe eager evaluation as strict evaluation
- So I might also say a pure functional language or simply a pure language
Functional Advantages
- The key advantage of a functional programming language is the hugely pretentious phrase “referential transparency”
- I'm not sure, but I suspect this phrase is one reason functional programming languages are not more widely adopted
- It means, that an expression evaluates to the same result regardless of the time, or state, in which it is evaluated
- In particular invoking a function:
some_fun(args)with the same argumentsargswill always produce the same result
Functional Advantages
- This makes testing and/or reasoning about the correctness of code much easier
- In theory, it means code is more re-usable
- This is debatable, and not, to my knowledge, demonstrated (either way) satisfactorily
- But it's certainly plausible
Functional Advantages
In theory, this additionally allows for some interesting compiler optimisations, consider the following double transformation over a list of items:
some_list = map f (map g original_list)
Functional Advantages
some_list = map f (map g original_list)
fg = f . g
some_list = map fg original_list
f . g is the composing of two functions together. This is
faster because it only loops over the list once.
Functional Advantages
some_list = map f (map g original_list)
fg = f . g
some_list = map fg original_list
f does not modify state which g
references or vice-versa. In a functional language this is both, more likely and
easier to automatically check.
Functional Advantages
fg = f . g
some_list = map fg original_list
- Similarly if you have multiple processors, you could begin the second map operation in parallel as soon as the first transforms the first item.
- Again, only if you can determine that there are no state dependencies.
- In general parallel programming can in theory be advanced by limiting state updates
Imperative Advantages
- With no state modifications all information required by any function must be passed in as an argument
- This can arguably make the code more complicated
- Worse, it can require a large refactoring in order to make a relatively simple change
Imperative Advantages
- However, recall that my definition of a functional programming language did allow for state modifications.
- It only required nested, higher order functions
- It's hard to argue that not providing these is an advantage to the programmer
- One could argue that the implementation (of the language) is simpler
- It is debatable, but one can certainly argue that the implementation of nested higer-order functions, requires a performance degradation
- Functions are more heavyweight and hence more expensive to invoke
Functional vs Imperative
Conclusion
- You could certainly use either a functional or an imperative language for this practical
- You're probably best off with whichever you prefer
Object Oriented vs Classless
- Given my glowing recommendation for higher-order functions why are they not more commonly used?
- Classes, or objects, allow for a similar abstraction
- An object is really a collection of state together with operations over that state
Typical Class Definition
class ClassName (ParentClass){
classmember_1 = 0;
classmember_2 = "hello";
void class_method_1(int i){
self.classmember += i;
}
void class_method_2(String suffix){
print_to_screen(self.class_method_2);
print_to_screen(suffix);
}
}
Object Oriented Languages Popularity
| Category | Ratings Sep 2013 | Delta Sep 2012 |
|---|---|---|
| Object-Oriented Languages | 56.0% | -1.1% |
| Procedural Languages | 37.3% | -0.9% |
| Functional Languages | 3.8% | +0.6% |
| Logical Languages | 3.0% | +1.3% |
Advantages of Object-Oriented
- Surprisingly debatable
- Most people agree that there is some value in object-oriented programming
- But when asked to give concrete advantages, most offer:
- Vague perceived benefits, with no logic connecting to OOP:
- Advances reuse
- Better models the real world
- Clear benefits but which are not unique to OOP:
- Polymorphism (fancy word for a specific kind of generality)
- Encapsulation (fancy word for hiding/abstraction)
- Vague perceived benefits, with no logic connecting to OOP:
Advantages of Classless
- No one really argues that the provision of classes is inherently destructive
- In a similar way to higher-order functions, having the ability to utilise classes does not do any harm if you never use them
- However, once the temptation is there, it's easy to go class crazy
- But such arguments are not arguments against the use of an object-oriented language, so much as an argument for careful use of classes
Object Oriented vs Classless
Conclusion
- By all means choose an object-oriented language
- There is little reason not to, but pure languages often do not
have a notion of an object
- This is for good reason and should not put you off choosing a pure language
- If you do choose an object-oriented language, use your classes with care
- Classes are just one way of organising source code.
- There are others which are just as effective
- Using an OOP language will not magically organise your source code for you
Lazy vs Eager

Lazy vs Eager
- Suppose we attempt to enforce the policy: everyone leaves the seat down
- What if two men (or the same man twice) use the toilet in succession
- This means the first man unnecessarily put the seat down only for the second man to put it back up again
Lazy vs Eager
- Suppose we attempt to enforce the policy: everyone leaves the seat up
- Now if two women (or the same woman twice) use the toilet in succession
- This means the first woman unnecessarily put the seat up only for the second woman to put it back down again
- “hugely” wasteful
Lazy vs Eager
- A more efficient strategy: leave the seat as it is
- If two people of the same gender visit successively no unnecessary work is done
- Whenever there is a gender switch the second person must change the state of the seat
- But that would otherwise have been done by the previous visitor anyway
Lazy vs Eager
- The first two inefficient strategies are examples of eager evaluation
- The final more efficient strategy is an example of lazy evaluation
- Essentially lazy evaluation is the policy of only ever computing a value when it is required
Lazy vs Eager
- Remaining in the household, this is equivalent to only washing dirty dishes when you are about to use them
- In this case, you do the same amount of washing up, it is only a question of when
- Unless you have some dish that is used exactly once
- But note, the lazy policy requires more space next to the sink
Lazy vs Eager
- Laziness is awesome
- But, there are some significant caveats to that
- I'll try to describe why I think laziness is an excellent feature
- But then also why it is not widely available
I stopped here at the lecture on October 4th
A common argument
You can compute infinite values
primes = [ x | x ‹- [2..], is_prime x ]
get_prime x = primes !! x
Consider
Imagine you are writing software to statically analyse a programming language. You can imagine many such analyses, and you wish that the user can turn on or off various analyses as they see fit. Suppose you first attempt to check if there are any calls to methods which are undefined:
if (analyse_called_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
for name in called_names{
if name ∉ method_names{
report_error()
}
}
}
Being Concise
I'm going to keep everything on one slide so I'll pretend we have some set based operators:
if (analyse_called_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
if (called_names ⊈ method_names){
report_error () }
}
Adding A Second Analysis
Now you wish to check if there are any methods which are defined but never used. Note that this might be considered more of a warning than an error:
if (analyse_called_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
if (called_names ⊈ method_names){
report_error () }
}
if (analyse_uncalled_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
if (method_names ⊈ called_names){
report_error () }
}Computing Sets Twice
This means if the user wants both analyses we are computingmethod_names and called_names twice.
if (analyse_called_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
if (called_names ⊈ method_names){
report_error () }
}
if (analyse_uncalled_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
if (method_names ⊈ called_names){
report_error () }
}
Only Compute What We Need
Any attempt to only compute the stuff you need gets complicated:
if (analyse_called_names || analyse_uncalled_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..)
if (analyse_called_names && called_names ⊈ method_names)
{ report_error() }
if (analyse_uncalled_names && method_names ⊈ called_names)
{ report_error() }
}
analyse_(un)called_names twice.
A Third Analysis
Let's add another analysis that checks if method names overlap class names:
if (analyse_called_names || analyse_uncalled_names || analyse_class_names){
method_names = gather_method_names(..)
called_names = gather_called_names(..) // Hmm?
if (analyse_called_names){
if (called_names ⊈ method_names) { report_error() }
}
if (analyse_uncalled_names){
if (method_names ⊈ called_names) { report_error() }
}
if (analyse_class_names){
class_names = gather_class_names(..)
if (method_names ∩ class_names != {}){ return error() }
}
}
A Third Analysis
Let's add another analysis that checks if method names overlap class names:
if (analyse_called_names || analyse_uncalled_names || analyse_class_names){
method_names = gather_method_names(..)
if (analyse_called_names){
called_names = gather_called_names(..)
if (called_names ⊈ method_names) { report_error() }
}
if (analyse_uncalled_names){
called_names = gather_called_names(..)
if (method_names ⊈ called_names) { report_error() }
}
if (analyse_class_names){
class_names = gather_class_names(..)
if (method_names ∩ class_names != {}){ return error() }
}
}
Worse
- Imagine I now add another analysis that uses the set of
class_namesbut not either of the other two - We can use a thunk pattern, but that is still complicating the code a little
Lazy Implements Thunk Anyway
In a lazy language I just do this:
method_names = gather_method_names(..)
called_names = gather_called_names(..)
class_names = gather_class_names(..)
if (analyse_called_names && called_names ⊈ method_names){
report_error() }
if (analyse_uncalled_names && method_names ⊈ called_names){
report_error() }
if (analyse_class_names && method_names ∩ class_names){
report_error() }
Advantages of Eager Evaluation
- So why are not all languages lazy?
- Lazy evaluation removes the predictability of when an expression may be evaluated
- Hence if your language allows side effects, lazy evaluation does not really work
- So lazy evaluation only really works together with a purely functional language
- Haskell is lazy, Ocaml is not
Lazy vs Eager
Conclusion
- There is no reason really to choose a lazy or eager language for this practical
- In any case your choice is more or less made up for you by your other choices
- If you like Haskell, Clean, Miranda or Hope, you will compute values lazily, most other languages are eager
Managed vs Unmanaged
- Automatic memory management, sometimes called garbage collection
- Without this, whenever you need to store a value in memory, you must first ask for the space in memory
- When a value in memory is no longer useful, you should give back the space in memory that it used
- If you let the last reference to a value go out of scope, without freeing up the associated memory, you will not ever do so, hence you have a space-leak
- Unfortunately, if you give back the memory too soon, you may subsequently try to reference the value, this may cause a segmentation fault
Advantages of Memory Management
- You need not manage the memory yourself, this is hugely liberating
- I believe there is much gained productivity associated with:
- Object Oriented Languages
- Dynamically/Statically typed languages
- Lazy languages
- Reflection
- I'm not saying these things do not also improve productivity
Advantages of Memory Management
- I can say
f(g(x))and not have to think about whether the intermediate result produced bygneeds to be cleaned-up - I can
returnfrom anywhere I like in the middle of a method, without worrying about all paths re-joining to free-up used memory- Honestly: “Only One Return” was a common coding rule
- Sometimes called “Single Entry, Single Exit”
Advantages of Manual Memory Management
- Nostalgia
- In theory you can implement manual memory management more efficiently
- This is a bit debatable
- In any case, the improved productivity gained through the use of an automatic garbage collector, can be put to use in optimising the rest of your code
- In particular better algorithms rather than faster implementation of the same one
Advantages of Manual Memory Management
- Predictability, it can be difficult to know when the garbage collector might run
- So real-time systems which must respond to incoming external events may suffer
- But there is much research into automatic garbage collection, and real-time garbage collectors do exist

Managed vs Unmanaged
Conclusion
- Choose a managed language
- If you are only familiar with an unmanaged language either:
- learn a new managed one or
- use a conservative garbage collector
- Don't complain that I haven't given you any concrete advice
Other Distinctions
- Low-level vs High-level
- This is mostly a distinction made from a combination of those above
- Significant Whitespace or not:
- Personally I love it, but it is syntax it does not matter
- If it bothers you that much you can always write a parser for a different syntax
- Scripting vs Systems:
- If you must distinguish these you can interoperate between them
What is the Best Language?
Main Conclusion
- In general, it is less what the language provides and more what libraries are available in that language
- This practical however, does not require the use of any major libraries
- Hence you are somewhat more free to choose based on the criteria I have discussed above
- Good Luck!
Summary and Conclusions
- My hard advice can be summarised as:
- Choose a strongly typed language
- Choose a language with automatic memory management
- It may be a useful thing to report in your README why you have chosen the language you have
- A perfectly valid reason is:
- “Language X is my favourite language which I know better than all others”
Any Questions?
Structure & Strategy
Computer Science Large Practical
This Lecture
- In this lecture I will try to give some helpful advice about the structure of your source code and your stategy
Overall Structure
- I do not wish to give too much advice since I do not want a set of near identically structured solutions
- Part of the practical is structuring it yourself. However, it seems
likely you will want at least the following components:
- A parser
- A representation of the state of a simulation
- Operations over that state
- The simulation algorithm
- Something to handle output
- Something to analyse results
- A test suite
Overall Structure
- I call these components, I do not call them:
- Classes, Instances, Objects, structs
- Interfaces, signatures, prototypes, aspects
- Methods, functions
- Modules, packages, functors
- Types, type classes
- This is not because I did not specify the source language
- It is because they could reasonably be any of these things
- It is up to you to decide what is most appropriate
Some Obvious Decisions
- Do you want to parse into some abstract syntax data structure
and then convert that into a representation of the initial state
- Or you could parse directly into the representation of the initial state
- Do you wish to print out events as they occur during the simulation
- Or record them and print them out later
- Do you wish to analyse the simulation events as the simulation proceeds
- Or analyse the events afterwards
- By recording them, or you could write a parser for the events
- You could write the simulator and events analyser as two completely separate programs, even in different languages
Parsing
- You do not need to start with the parser
- The parser produces some kind of data structure. You could instead start by hard coding your examples in your source code
- But the parsing for this project is pretty simple
- Hence I would start with the parser, even if I did not complete
the parser before moving on
- I find hard coding data structure instances laborious
- But doing so would ensure your simulator code is not heavily coupled with your parser code, if you decide that is important
Software Construction
- Software construction is relatively unique in the world of large projects in that it allows a great deal of back tracking
- Many other forms of projects, such as construction, event planning, and manufacturing, only allow for backtracking in the design phase.
- Because of this, traditional project planning advocates a large amount of up-front design
- When computer programming projects first started to grow beyond the remit of a single week, such techniques were applied
- We now know that often this is something of a waste of this unique ability to allow backtracking
Software Construction
- Another way to view this:
- Construction projects cannot afford to change the design once construction has begun
- Hence, the design phase consists of building the object virtually (on paper, on a computer) when backtracking is inexpensive
- Software projects do not produce physical artifacts, so the construction of the software is mostly the design
Refactoring
- Refactoring is the process of changing code such that it computes exactly the same function (of inputs to outputs), but has a better design.
- This is tremendously powerful, because it allows us to try out various designs, rather than guessing which one is the best
- It allows us to determine whether something is possible, without necessarily building it in the best way
- It allows us to design retrospectively once we know significant details about the problem at hand.
- It allows us to avoid the cost of full commitment to a particular solution which, ultimately, fails.
Suggested Strategy
- Note that this is merely a suggested strategy
- Start with the simplest program possible
- Incrementally add features based on the requirements
- After each feature is added, refactor your code
- This step is important, it helps to avoid the risk of developing an unmaintainable mess
- Additionally it should be done with the goal of making future feature implementations easier
- This step includes janitorial work (see below)
Suggested Strategy
- At each stage, you always have something that works
- Although you need not specifically design for later features you do at least know of them, and hence can avoid doing anything which will make those features particularly difficult.
Alternative Inferior Strategy
- Design the whole system before you start
- Work out all components and sub-components you will need
- Start with the sub-components which have no dependencies
- Complete each sub-component before moving on to the next
- Once you have developed all the dependencies of a component you can now choose that component to develop
- Finally, put everything together to obtain the entire system
- Test the entire system
Janitorial Work
- Wish to discuss two points:
- Real and Logical Time
- How to break a rule
- To do so I'll need the notion of janitorial work
- Examples of Janitorial
- Reformating
- Commenting
- Changing Names
- Tightening
Janitorial Work
Reformating
void method_name (int x)
{
return x + 10;
}
void method_name(int x) {
return x + 10;
}
Janitorial Work
Reformating
- Refomatting is entirely superficial
- It is important to consider when you apply this
- Reformatting can result in a large ‘diff’
- This may well conflict with other work performed concurrently
- Reformatting should be largely unnecessary, if you keep your code
formatting correctly in the first place
- More commonly required on group projects
Janitorial Work
Commenting
- I hope I needn't re-iterate the importance of writing good comments in your source code
- When done as janitorial work this can be particularly useful
- You can comment on the stuff that is not obvious even to yourself as you read it. This is much more difficult when writing new code
- The important thing to comment is not what or how but why
- Try not to have redundant information in your comments:
// the first integer argument - The fancy XML formatting does nothing to save this comment
Janitorial Work
Commenting
Ultra bad:
// increment x
x += 1;
// Since we now have an extra element to consider
// the count must be incremented
x += 1;
Janitorial Work
Changing Names
- The previous example used
xas a variable name - Unless it really is the x-axis of a graph, choose a better name
- This is of course better to do the first time around
- However as with commenting, unclear code can often be more obvious to its author upon later reading it
Janitorial Work
Tightening
void main(...){
run_simulation();
}
void main(...){
try{
run_simulation();
} catch (FileNotFoundException e) {
// Explain to the user ..
}
}
Janitorial Work
Tightening
- For some this is not janitorial work, since it actually changes in a non-superficial way the function of the code
- I place it here, since similar to other forms it is often caused by being unable to think of everything when writing new code
Janitorial Work
- Most of this work is work that arguably could have been done right the first time around when the code was developed
- However, when developing new code, you have limited cognitive capacity
- You cannot think of everything when you develop new code, janitorial work is your time to rectify the minor stuff you forgot
- Better than trying to get it right first time is making sure you later review your code
Janitorial Work
- “Refactoring is the process of changing code such that it computes exactly the same function (of inputs to outputs), but has a better design.”
- Strictly speaking janitorial work is not refactoring
- It should not change the function of the code
- Tightening might, but generally for exceptional input
- But neither does it make the design any better
- It should not change the function of the code
- In common with refactoring you should not perform janitorial work on pre-existing code whilst developing new code
- It will not do you any harm to use the phrase “janitorial work” in your commit messages
Janitorial Work
- Suppose I'm implementing some new feature and I come across this
// prase the 'validate' command
// parse the 'validate' command
Real and Logical Time
- The answer is, I fix it right now in real time, but use SCC to avoid doing two things at once in logical time
- You should be on a development branch and do this:
$ git checkout master # go back to the master branch
$ editor mycode.cobol # Fix the typo
$ git commit -a -m "Fixed a prase->parse typo"
$ git checkout dev # go back to your development branch
$ git rebase master # pretend you fixed the typo before
How to Break a Rule
- “you should not perform janitorial work on pre-existing code whilst developing new code”
- If this is “too much work right now” then just fix the typo rather than leave it as is
- In other words, if you must break the rule, break it such that the code is still fixed
- This is especially true if the fix is some form of tightening
- Of course if the fix itself is too much work for right now, then it should go in a bug tracker
More About Refactoring
- Refactoring is a term which encompasses both factoring and defactoring
- Generally the principle is to make sure that code is written exactly once
- We hope for zero duplication
- However, we would also like for our code to be as simple and comprehensible as possible
Factoring and Defactoring
- We avoid duplication by writing re-usable code
- Re-usuable code is generalised
- Unfortunately, this often means it is more complicated
- Factoring is the process of removing common or replaceable units of code, usually in an attempt to make the code more general
- Defactoring is the opposite process specialising a unit of code usually in an attempt to make it more comprehensible
I ended the lecture on October 11th here
Breaking (Bad) Methods
Here is a question posted to stack overflow:When is a function too long? [closed]
35 lines, 55 lines, 100 lines, 300 lines? When you should start to break it apart? I'm asking because I have a function with 60 lines (including comments) and was thinking about breaking it apart
long_function(){ ... }
into:
small_function_1(){...}
small_function_2(){...}
small_function_3(){...}
The functions are not going to be used outside of the long_function, making smaller functions means more function calls, etc.
When would you break apart a function into smaller ones? Why?
A Blog Post
Long methods and classes are evil
See the original here.- Any method should fit into your IDE window ... I strive for an average of not more than 5 lines of code per method
- Too many private members .. say greater than 10
- The size of the code file. Offhand, I’d say any class over 10k in size ...
- Exception handling code and instrumentation tend to push methods to be much larger. Invest some thought in how to segregate this type of code away from the main functionality
- Reduce the number of public methods in a class. Just picking a number, I would say less than 10 in most cases.
Common Rules
These are some common rules:- “Methods should have no more than X lines of code”
- “Classes should have no more than X methods/private variables”
- “Files should have no more than X lines of code”
Ignore Such Rules
- Most such rules are well intentioned
- The are supposed to be easy to adhere to and check
- But unless you understand the motivation behind such a rule, following it will do you no good
- These rules tell you what not to write, but they do not explain what you should write instead
- Not to mention the fact that most good rules have some exceptions
Example (long methods)
integer my_long_method(int input){
int x = 0;
...
// Do some stuff
...
// Do some other stuff
...
// Finally return
return x;
}
Example (long methods)
void do_some_stuff(int x, int y){
// Do some stuff
}
integer do_some_other_stuff(int x, String star){
// Do some other stuff
return x
}
integer my_long_method(int input){
int x = 0;
...
do_some_stuff(x, 0);
x = do_some_other_stuff(x, input_string);
// Finally return
return x;
}
Factoring
void primes(int limit){
integer x = 2;
while (x <= limit){
boolean prime = true;
for (i = 2; i < x; i++){
if (x % 2 == 0){ prime = false; break; }
}
if (prime){ System.out.println(x + " is prime"); }
}
}
Factoring
void print_prime(int x){
System.out.println(x + " is prime");
}
void primes(int limit){
x = 2;
while (x <= limit){
... // as before
if (prime){ print_prime(x); }
}
}
Factoring
To make it more general we have to actually parameterise what we do with the primes once we have found them.
interface PrimeProcessor{
void process_prime(int x);
}
class PrimePrinter implements PrimeProcessor{
public void process_prime(int x){
System.out.println(x + " is prime");
}
}
void primes(int limit, PrimeProcessor p){
x = 2;
while (x <= limit){
... // as before
if (prime){ p.process_prime(x); }
}
}
Factoring
If I wish to store the primes instead:
class PrimeRecorder implements PrimeProcessor{
public LinkedList primes;
public PrimeRecorder(){
self.primes = new LinkedList();
}
public void process_prime(int x){
self.primes.append(x);
}
}
Factoring
I can go further and factor out the testing as well:
interface PrimeTester{
boolean is_primes(int x);
}
class NaivePrimeTester implements PrimeTester{
public boolean is_prime(int x){
for (i = 2; i < x; i++){
if (x % 2 == 0){ return false; }
}
return true;
}
}
void primes(int limit, PrimeTester t, PrimeProcessor p){
x = 2;
while (x <= limit){
if (t.is_prime(p)){ p.process_prime(x); }
}
}
Factoring
Now that I've factored out the test, it does not have to be used solely for primes
interface IntTester{
boolean property_holds(int x);
}
class NaivePrimeTester implements IntTester{
public boolean property_holds(int x){
for (i = 2; i < x; i++){
if (x % 2 == 0){ return false; }
}
return true;
}
} // Similarly for PrimeProcessor to IntProcessor
void number_seive(int limit, IntTester t, IntProcessor p){
x = 0;
while (x <= limit){
if (t.property_holds(p)){ p.process_integer(x); }
}
}
Factoring
Print the perfect numbers:
interface IntTester{
boolean property_holds(int x);
}
class PerfectTester implements IntTester{
public boolean property_holds(int x){
return (sum(factors(x)) == x);
}
} // Similarly for PerfectProcessor
void number_seive(int limit, IntTester t, IntProcessor p){
x = 0;
while (x <= limit){
if (t.property_holds(p)){ p.process_integer(x); }
}
}
Factoring
We might find the two extra parameters a bit ugly, no problem:
public abstract class NumberSeive{
abstract boolean property_holds(int x);
abstract void process_integer(int x);
abstract int start_number;
void number_seive(int limit){
x = self.start_number;
while (x <= limit){
if (self.property_holds(p)){ self.process_integer(x); }
}
}
}
Factoring
Here is the code for printing the primes:
public abstract class NumberSeive{
abstract boolean property_holds(int x);
abstract void process_integer(int x);
abstract int start_number;
void number_seive(int limit){
x = self.start_number;
while (x <= limit){
if (self.property_holds(p)){ self.process_integer(x); }
}}} // Close all the scopes
public class PrimeSeive inherits NumberSeive{
public boolean property_holds(int x){
for (i = 2; i < x; i++){
if (x % 2 == 0){ return false; }
} return true; }
void process_integer(int x) { System.out.println (x + " is prime!"); }
int start_number = 2;
}
Factoring
Print the perfect numbers:
public class PerfectSeive inherits NumberSeive{
public boolean property_holds(int x){
return (sum(factors(x)) == x); }
void process_integer(int x) { System.out.println (x + " is perfect!"); }
int start_number = 2;
}
Factoring
So which version do we prefer? This one:
public abstract class NumberSeive{
abstract boolean property_holds(int x);
abstract void process_integer(int x);
abstract int start_number;
void number_seive(int limit){
x = self.start_number;
while (x <= limit){
if (self.property_holds(p)){ self.process_integer(x); }
}}} // Close all the scopes
public class PrimeSeive inherits NumberSeive{
public boolean property_holds(int x){
for (i = 2; i < x; i++){
if (x % 2 == 0){ return false; }
} return true; }
void process_integer(int x) { System.out.println (x + " is prime!"); }
int start_number = 2;
}
Factoring
Or the original version?
void primes(int limit){
integer x = 2;
while (x <= limit){
boolean prime = true;
for (i = 2; i < x; i++){
if (x % 2 == 0){ prime = false; break; }
}
if (prime){ System.out.println(x + " is prime"); }
}
}
Factoring
Something in between?
LinkedList get_primes(int limit){
int x = 2; LinkedList results = new LinkedList();
while (x <= limit){
boolean prime = true;
for (i = 2; i < x; i++){
if (x % 2 == 0){ prime = false; break; }
}
if (prime){ results.append(x); }
}
}
void primes(int limit){
for x in get_primes(limit){
System.out.println(x + " is prime");
}
}
Factoring
- The answer of course depends on the context
- How likely am I to need more number seives?
- How likely am I to do something other than print the primes?
- The compromise is surely slower for printing the primes out
- But it is very adaptable
Defactoring
- Numbers such as the number 20 can be factored in different ways
- 2,10
- 4,5
- 2,2,5
- If we have the factors 2 and 10, and realise that we want the number
4 included in the factorisation we can either:
- Try to go directly by multiplying one factor and dividing the other
- Defactor 2 and 10 back into 20 and then divide 20 by 4
Defactoring
- Similarly your code is factored in some way
- In order to obtain the factorisation that you desire, you may have to first defactor some of your code
- This allows you to factor down into the desired components
- This is often easier than trying to short-cut across factorisations
Sieve of Eratosthenes
- Create a list of consecutive integers from 2 to n: (2, 3, 4, ..., n)
- Initially, let p equal 2, the first prime number
- Starting from p, count up in increments of p and mark each of these
numbers greater than p itself in the list
- These will be multiples of p: 2p, 3p, 4p, etc.; note that some of them may have already been marked.
- Find the first number greater than p in the list that is not marked
- If there was no such number, stop
- Otherwise, let p now equal this number (which is the next prime), and repeat from step 3
Sieve of Eratosthenes
void primes(int limit){
LinkedList prime_numbers = new LinkedList();
boolean[] is_prime = new Array(limit, true);
for (int i = 2; i ‹ Math.sqrt(limit); i++){
if (is_prime[i]){
prime_numbers.append(i);
for (j = i * i; j ‹ limit; j += i){
is_prime[j] = false;
}
Defactoring
- Defactoring then can be used as the first step of refactoring
- It might also simply be that you feel the current factored version is over-engineered
- Flexibility is great, but it is generally not without cost
- The cognitive cost associated with understanding the more abstract code
- If the flexibility is not now or unlikely to become required then it might be worthwhile defactoring
- Don't be shy in explaining your reasoning in comments and commit messages
Refactoring Can Better Document
What does this code do?
r = g.nextDouble();
d = 1.0 - (1.0/x * Math.log(r));
System.out.println (d);
Refactoring Can Better Document
Better?
dice = generator.nextDouble();
delay = 1.0 - (1.0/rate * Math.log(dice));
System.out.println (delay);
Refactoring Can Better Document
How about now?
// Choose a delay from the exponential distribution given the rate
dice = generator.nextDouble();
delay = 1.0 - (1.0/rate * Math.log(dice));
System.out.println (delay);
Refactoring Can Better Document
Do I need a comment?
double calculate_exponential_delay(double rate, Random generator){
dice = generator.nextDouble();
delay = 1.0 - (1.0/rate * Math.log(dice));
return delay;
}
System.out.println (calculate_exponential_delay(rate));
System.out.println (calculate_exponential_delay(rate));
Refactoring Can Better Document
System.out.println (calculate_exponential_delay(rate));
- If your code is highly coupled it will be difficult to extract such self-documenting fragments
- In this case, you have code you should try to re-arrange first before factoring out
- If your factored out method has a ridiculously long name, or many parameters it is a good sign that it is not worth factoring out:
xs = calculate_exponential_delays_from_global_events(rate_function,
generator ,
...);
Refactoring Summary
- Code should be factored into multiple components
- Refactoring is the process of changing the division of components
- Defactoring can help the process of changing the way the code is factored
- Well factored code will be easier to understand
- Do not update functionality at the same time
Common Approach
- There is a common approach to developing applications
- Start with the main method
- Write some code, for example to parse the input
- Write (or update) a test input file
- Run your current application
- See if the output is what you expect
- Go back to step 2.
Do Not Start with Main
- A better place to start is with a test suite
- This doesn't have to mean you cannot start coding
- Write a couple of test inputs
- in separate files or as string literals
- Create a skeleton “do nothing” parse method
- Create an entry point which simply calls your parse method on your test inputs (all of them)
- Watch them fail
Do Not Start with Main
DataStructure parse_method(String input_string){
return null;
}
void run_test(input){
try { result = parse_method(input);
if (result == null){
System.out.println("Test failed by producing null");
} else { System.out.println("Test passed"); }
}
catch (Exception e){
System.out.println("Test raised an exception!");
}}
test_input_one = "...";
test_input_two = "...";
void test_main(){
run_test(test_input_one);
run_test(test_input_two);
...
}
Do Not Start with Main
- Code until those tests are green
- Including possibly refactoring
- Without forgetting to commit to git as appropriate
- Consider new functionality
- Write a method that tests for that new functionality
- Watch it fail, whether by raising an exception or simply not producing the results required
- Return to step 1.
- You can write your
mainmethod any time you like- It should be very simple, as it simply calls all of your fully tested functionality
Do Not Start with Main
- Any time you run your code and examine the results, you should be examining output of tests
- If you are examining the output of your program ask yourself:
- Why am I examining this output by hand and not automatically?
- If I fix whatever is strange about the output can I be certain that I will never have to fix this again?
- Of course sometimes you need to examine the output of your program to determine why it is failing a test. This is just semantics (it is still the output of some test)
Do Not Start with Main
Summary
- Everything your program outputs should be tested
- Intermediate results that you might not output can still be tested as well
- Run all of your tests, all of the time
- They may take too long to run them all for each development run
- In which case, run them all before and after each commit
Optimisation
- Re-usability can conflict heavily with readability
- Similarly optimised or fast code can conflict with readability
- You are writing a simulator which may have to simulate millions of events
- In order to obtain statistics, it may then have to repeat the simulation thousands of times
- Optimised code is generally the opposite of reusable code
- It is optimised for its particular assumptions which cannot be violated
Premature Optimisation
- The notion of optimising code before it is required
- The downside is that code becomes less adaptable
- Because the requirements on your optimised piece of code may change, you may have to throw away your specialised code and all its optimisations
- Note: I do not mean the requirements of the project
- In a realistic setting they may, but not here
- It is the requirements of a particular portion of your code which may change
Premature Optimisation
- Worse than throwing away your own optimisations, you may instead elect to work around your specialised and optimised section of code
- Thus your premature optimisation has negatively effected other parts of your code
Timely Optimisation
- So when is the correct time to optimise?
- Refactoring is done in between development of new functionality
- Recall this makes it easier to test that your refactoring has not changed the behaviour of your code
- This is also a good time to do some optimisation
- You should be in a good position to test that your optimisations have not negatively impacted correctness
- This has the additionally bonus that since you are refactoring at a similar time you should already be considering the adaptability and readability of your code
Timely Optimisation
- The absolute best time to optimise code is when you discover that it is not running fast enough
- Often this will come towards the end of the project
- It should certainly be after you have something deployable
- After you have developed and tested some major portion of functionality
A Plausible Strategy
- Perform no optimisation until the end of the project once all functionality is complete and tested
- This is a reasonable stance to take, however:
- During development, you may find that your test suite takes days to run
- Even one simple run to test the functionality you are currently developing may take minutes or hours
- This can seriously hamper development, so it may be best to do some optimisation at that point
How to Optimise
- The very first thing you need before you could possibly optimise code is a benchmark
- This can be as simple as timing how long it takes to run your test suite
- O(n2) solutions will beat O(n log n) solutions on sufficiently small inputs, so your benchmarks must not be too small
How to Optimise
- Once you have a suitable benchmark then you can:
- Run your benchmark on a build from a clean repository recording the run time
- Perform what you think is an optimisation on your source code
- Re-run your benchmark and compare the run times
- If you have successfully improved the performance of your code commit your changes, otherwise revert them
- Do one optimisation at a time
How to Optimise
- “This can be as simple as timing how long it takes to run your test suite”
- However, bear in mind that you are writing a stochastic simulator
- This means each run is different and hence may take a significantly different time to run
- Even if the code has not changed or has not changed in a way that significantly affects the run time
- Simply running several inputs or the same input several times should be enough to reduce or nullify the effect of this
Interacting Optimisations
- Word of caution: some optimisations may interact with each other, so you
may wish to evaluate them independently as well as in conjunction
- As always source code control can empower you to do this
High-level vs Low-level Optimisations
- It is usually more productive to consider high-level optimisations
- The compiler is often good at low-level optimisations
- It is often better to call a method fewer times, than to optimise the code within a method
Profiling
- Profiling is not the same as benchmarking
- Benchmarking:
- determines how quickly your program runs
- is to performance what testing is to correctness
- Profiling:
- is used after benchmarking has determined that your program is running too slowly
- is used to determine which parts of your program are causing it to run slowly
- is to performance what debugging is to correctness
- Without benchmarking you risk making your program worse
- Without profiling you risk wasting effort optimising a part of your program which either already fast or rarely executed
Documenting Optimisations
- Source code comments are a good place to explain why the code is the way it is
- Source code control commits are a good place to document why you performed the optimisations including benchmark/profiler results etc.
Summary
- I have mostly talked about strategy rather than structure
- Structure is difficult to give concrete advice about
- Refactoring is the most important thing you can learn from this lecture:
- Refactoring allows us to avoid doing a large amount of upfront design and also avoid producing a a big hairy mess
- Do not change functionality whilst refactoring
- You code should be adaptable
- Do not start with
mainwrite a test suite instead - Do not optimise blindly, benchmark and profile
- There is not a thing on this page that your source code control will not make easier
Any Questions?
General Tips & Assessment
Computer Science Large Practical
A Small Story
Any Normal Person Would Do
My Message

Response
Reply to Response

Results
Exasperation
The Lesson
- Aside from the obvious business lesson
- This tells me that the developers of the website and app are not users
- They have developed the website for one user story:
- “I know which film I want to watch I want to book it now”
- They have developed the app for a different user story:
- “I might go to the cinema tonight, what's on?”
Assessment Criteria
- Implementation of requirements:
- Parsing
- Correct simulation & correct output
- Summary statistics of simulation results
- Experimentation implementation
- Parameter optimisation implementation
- Input Validation
- Use of source code control
- Documentation, including source comments
- Testing, including sample test input scripts
- Maintainable code
- Evidence of benchmark/profile-based optimisation
- Any additional features
- Early submission
Objective & Subjective Criteria
- Some of the items on the above list are objective whilst some are subjective
- Objective criteria are those which are testable
- Subjective criteria are those which are, at least partially,
based upon opinion
- Whether or not the criteria is matched is open to debate
Objective Assessment Criteria
- The most objective assessment criteria is:
- Early submission
- Either you submit it before the early submission deadline or you do not
- Though arguably this is not really an assessment criteria
Objective Assessment Criteria
This first list of implementation requirements are all relatively objective:- Parsing
- Correct simulation & correct output
- Summary statistics of simulation results
- Experimentation implementation
- Parameter optimisation implementation
- Input Validation
Objective Assessment
- These will be marked almost entirely algorithmically
- This means your application will be put through my own suite of test inputs
- Some of these test inputs will be inputs you have seen, some will be new
- Part of the exercise is for you to foresee possible inputs for which
your application would fail
- Either by crashing, or by producing incorrect output
- There may be some non-algorithmic marking to this should your application
fail any tests
- In which case I have to figure out why your application is failing
Parsing
- Your parser should be able to parse all syntactically valid input scripts
- I cannot say it much simpler than that
- There won't be any deliberately tricky tests
Correct Simulation & Output
- Here I'm testing whether your simulator correctly follows the requirements
- The simulator is tested via its output, so these are tested at the same time
- Having said that, where the output is not correct, the code is inspected to determine why
- Minor syntactic issues with the output will be judged leniently
- This part of the reason your code must compile on DiCE
- It certainly won't hurt your grade to get it correct
Summary Statistics
- Similarly this will test for correctly calculating and reporting the specified summary statistics
- It is possible to get the simulation incorrect but the summary statistics correct
- A small tip is to make sure your reported statistics are consistent
with each other:
- I will say more about this later
- It might be that you are getting inconsistent results because your simulation is incorrect, in which case you should note this in your README
Experimentation Implementation
- Whether or not you correctly implement the experimentation of rates and numbers
- As before it is possible to get this correct, without getting either (or both) of the simulation and the summary statistics correct
- As before, if you are getting inconsistent results you should at least note that in your README
Parameter Optimisation
- Similarly parameter optimisation should be handled correctly
- Similarly it is possible to implement this correctly with everything above implemented incorrectly
- Again, similarly if you get inconsistent results you should at least have noted this in your README.
Input Validation
- This is the first task which is not finely specified
- Here you have to demonstrate some ingenuity to conjure up your own rules for what should and should not be valid input
- You also have to decide which kinds of inputs result in
warnings or errors, although this is specified there is
still some scope for interpretation
- Specifically those in which the simulation could be started but may result in an error
- This may depend upon the structure of your simulator
Noting Deficiencies
- Use your README file to catalog any deficiencies which are aware of
- Or a more sophisticated form of bug database, but please not a public one
- In general any implementation errors will be viewed significantly more leniently if they are known about
- Known bugs are better than unknown bugs
- Even better if you additionally avoid the output of erroneous results
How to Fail
- Remember, it is generally worse to produce incorrect output than no output at all
- This will generally require defensive programming
Subjective Assessment
The remaining items are mostly judged subjectively- Use of source code control
- Documentation, including source comments
- Testing, including sample test input scripts
- Maintainable code
- Evidence of benchmark/profile-based optimisation
- Any additional features
Source Code Control
- I've spoken about this at length already
- Keep your commits small
- Write good commit messages
- Don't be shy, I'm sure I will enjoy reading your commit messages
- If you know you're committing something you shouldn't at least say so in the commit message
Source Code Control
- One more thing about source code control
- Should you commit commented out code?
- Some people's reaction:
- I'm a little more mellow, certainly no huge swathes of commented out code
- But the occasional line of code used as part of a comment explanation is fine

Documentation
- Mostly of your source code
- You may develop additional features which, if you do not document, I may not even know about
- This is not at all unrealistic
Testing
- Last year, on another course, I asked students to write a simulator for a distributed network protocol
- The intention of the coursework was not to produce a good simulator
- It was to investigate the properties of the network protocol
- Some students returned a simulator with exactly one test input
- The one I had supplied as an example
Testing
- For you, the practical is indeed to write a good simulator
- You can at least strive for “half decent”
- Either way, running one test input, is woefully insufficient
Maintainable Code
- Highly subjective
- Remember, reusable code is more difficult to understand
- But reusable code is easier to, well, reuse
- Reused code is easier to maintain
- What is a poor developer to do?
- Try to imagine what you might wish to do in the future
Maintainable Code
Specific Example
- How should I write my parser?
- Simple string interrogation
- Regular expressions
- Handwritten parser using, for example, functions
- Use a parser-generator in style of flex and bison
- The simple question you have to ask yourself is this:
- “What kind of updates to the parser am I (or someone else) likely to do in the future?”
Maintainable Code
- Highly subjective
- Trying to justify some of your choices is likely a good thing
- Even if your reasoning is flawed, it demonstrates that you have thought about how to design/arrange your source code
- And that you probably could have implemented it in other way, but specifically chose not to
- A future maintainer at least knows why you made that choice, if they disagree, they can change the code without fear of some other reason they have not yet uncovered
Additional Features
- This is your change to stop being an automaton and mindlessly implementing requested features
- It perhaps requires some imagination, but imagine you were really going to use your simulator to investigate some real (or other) network
- What would be useful to you?
- The evidence of mindless developers writing to specifications are all around you, once you notice it.
README
- Don't forget to provide me with a README
- In general this can only help your grade:
- It lets me know good things are deliberate and not fortunate
- It lets me know that deficiencies are at least known about
Final Point
- Students are often worried about losing marks
- Indeed our own assessment descriptions often talk of losing marks
- But let's not forget, you start with zero
Test Strategies
- Two obvious test strategies:
- Test for expected output. A given input should give predictable
output
- This is slightly more tricky for a program that makes use of random numbers
- You have a stochastic simulator which is not expected to generate the same set of events for identical input
- Test for expected properties:
- This is often used in conjunction with generating random inputs for which you do not know the output
- If you used
quickcheckin Inf1-FP, you have experience with this form of testing
- Test for expected output. A given input should give predictable
output
Random Numbers
- Computers are great at computing deterministic results
- Not quite so good at generating a sequence of random numbers
- You are going to need a sequence of random numbers
- Generally this is done using a Pseudo Random Number Generator
- This is really hard
- It must avoid, periodicity as well as a biased distribution
PRNG
- John von Neumann, suggested an approach in 1946:
- Start with some 4 digit number say 6843
- Square it, 46826649
- Take the middle 4 digits as the next random number
- It also serves as the seed for the next random number
- A few problems, many seeds repeat; 0000, repeats very immediately
- Much better ones exist today and thankfully you should not need to implement one yourself
- Generally a PRNG relies on a seed number
- Where Rn is the nth random number and
Sn is the nth seed:
- Rn, Sn = f(Sn-1)
PRNG
class Random{
constructor(int seed){
self.random_seed = seed
}
int random(){
// Update the random seed
self.random_seed = self.random_seed * 1103515245 +12345;
// Generate and return a new random number
return (self.random_seed / 65536) % 32768; }
}
}
Halo
Replays
- The replays are stored as one number, plus the sequence of key/button presses made by the user
- When a replay is run, the sequence of events which take place as a result of those button presses is recomputed
- Replays are not stored as videos
- Unless you explicitly ask for that in order to share it
- This is why you can change the camera position when viewing a replay
Replays - But Wait
- Are there not some random elements to the sequence of events?
- Where all players are human this varies from game to game
- But AI players almost always incorporate some probabilistic decision making
- So how does this work with the replay?
Replays - PRNG
- Pseudo random number generators are not really generating a random sequence of numbers
- Recall: Rn, Sn = f(Sn-1)
- If you know S0 the rest of the sequence is entirely deterministic
- Hence the one number stored with the sequence of input events is the initial random number generator seed
- Halo uses only one seed for all “random” numbers generated
Recall Two Forms of Testing
- Test for expected output. A given input should give predictable output
- Now you have a handle on this:
- Allow yourself to specify the seed used for a simulation
- Now your testing routine can specify a seed for which it knows what the output should be
- This is at least regression testing
- Of course your production main either chooses a seed randomly or does not specify one and allows your simulation routine to choose one
- Test for expected properties:
Expected Properties
- This kind of testing is used for stochastic programs a lot, including the random number generators themselves
- It is up to you to come up with your own set of properties
- But to start you off, consider:
- Events should be ordered according to the simulated time at which they have occurred
- A bus should never have more passengers than its capacity suggests
- Your summarised statistics should be consistent:
- eg. The number of missed passengers in total should be greater than or equal to the number of missed passengers for any single route
Expected Properties
- New passengers is an event that is always enabled and occurs at
a constant rate:
- This means that the number of occurrences should be at close to the simulation time divided by the mean delay
- The mean delay is simply 1 over the rate
- If the rate is 1.0 and the simulation time is 100, you should expect that it occurs approximately 100 times
Testing Floating Point Numbers
GHCi, version 7.4.2: http://www.haskell.org/ghc/ :? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Prelude> 1.0 - 0.95
Testing Floating Point Numbers
GHCi, version 7.4.2: http://www.haskell.org/ghc/ :? for help
Loading package ghc-prim ... linking ... done.
Loading package integer-gmp ... linking ... done.
Loading package base ... linking ... done.
Prelude> 1.0 - 0.95
5.0000000000000044e-2
Prelude>
Testing Floating Point Numbers
public class Floating {
public static void main(String[] args) {
System.out.println(1.0 - 0.95);
}
}
mimi:tmp$ javac Floating.java
mimi:tmp$ java Floating
0.050000000000000044
Testing Floating Point Numbers
public class Floating {
public static void main(String[] args) {
System.out.println(1.0 - 0.95);
System.out.println(0.05);
}
}
mimi:tmp$ javac Floating.java
mimi:tmp$ java Floating
0.050000000000000044
0.05
Testing Floating Point Numbers
- In your tests you might not be able to use equality to test for the floating point numbers that you expect
void test_some_bit_of_code(...){
// might not work
assert_equal(2.0, some_bit_of_code(...));
}
void approximately_equal_simple(x, y){
return absolute(x - y) < 1.0E-8;
}
Testing Floating Point Numbers
A fancier version
// atol is the absolute tolerance
// rtol is the relative tolerance
void approximately_equal(x, y, rtol, atol){
return absolute(a - b) <= (atol + rtol * absolute(b))
}
- You can probably get by with the simple version
- In any case it is worth reading What Every Computer Scientist Should Know About Floating-Point Arithmetic
Review of Part One
Computer Science Large Practical
Submissions
13 out of 22 students submitted at least something:- 2 out of 13 zipped up their submission directory
- No need to do this, just submit the directory
- You will save me the effort of unzipping it
- 1 out of 13 submitted for part 2
Submissions
13 out of 22 students submitted at least something:| Language | Number of Submissions |
| Python | 7 |
| Java | 4 |
| C# | 1 |
| Perl | 1 |
One Brave Sole Chose Perl
- I did warn you not to choose a weakly typed language
- However, I also said I would not judge your choice of language
- As a bit of extra help, I'll recount the tale of the Nancy bug
The Nancy Bug
- Once upon a time, there was an expert system developed in Perl
- An expert system is an artificial intelligence kind of program designed to mimic human decision making
- This means it is quite tricky to debug, since you expect it to be wrong sometimes
- One component of this system, relied on checking whether two names were equal
- It was discovered that this system was frequently suggesting that two names were equal, when they were not, giving many false positives
The Nancy Bug
- But there were also the occasional false negative
- As you might have guessed “Nancy” was a false negative
| John | George | Apparently Equal |
| Paul | Ringo | Apparently Equal |
| Emma | Geri | Apparently Equal |
| Melanie | Victoria | Apparently Equal |
| Nancy | Nancy | Apparently Not Equal |
The Nancy Bug
- String equality in Perl is written as
s1 eq s2 - Unfortunately the expert system had accidentally used integer equality
s1 == s2 - Provided with two strings, Perl converted these to integers
- Since most names do not represent a reasonable number,
each name generally got mapped to 0
- Hence all the false positives
- "John" == "George" is the same as 0 == 0
- So how come
"Nancy" != "Nancy"
The Nancy Bug
- Perl tries to parse as much of the string as an integer as is possible
- "Nan" parses as not-a-number
- Most people agree that not-a-number does not equal itself
- Hence
"Nancy" == "Nancy"becomesnan == nan- Which is correctly False
- Hence the false-negative
"Nancy" != "Nancy"
The READMEs
- Ranged from very basic containing a couple of lines to very detailed.
The READMEs - Language Choice
- 0 out of 13 explained the choice of language
- 10 out of 13 specified the choice of language with no explanation
- 3 out of 13 implied the choice of language
- The source files are right there
- This is a bit of an artificial requirement. It might just force me to view some design decisions differently (and hence increase your mark).
- I think it is something of a good exercise though
- “I picked Python as my programming language because it's nice.”
Random Goodness
- “Please do not change the test files because that would cause the unit tests to fail”
- “To compile this ....”
- “To run this ... ”
- “Such and such does not yet work ...”
Random Fussiness
- One person managed to note down their matriculation number incorrectly
- Don't worry someone else has a directory named “scr”
- In general don't fuss too much about spelling and grammar, I'm pretty immune to such “errors”
Random Not-So-Goodness
- Low-level coding decisions:
- Are apt to change and you will forget to update the README
- Should be in comments in the source code file concerned
- “Most of the logic in the simulation is in the objects (Stop, Bus, Passenger) themselves”
- High-level structure that is less likely to change is absolutely fine
- You are more likely to remember to change the README in the event of a major re-structuring
- One person had both a README.md and a Readme.txt which were identical
Random Comments
- “this might or might not be the worst-looking
code you have ever seen”
- Unlikely. I've seen some pretty hellish code
Git Status
- 6 out of 13 have some unstaged modifications
# On branch master
# Changed but not updated:
# (use "git add/rm file..." to update what will be committed)
# (use "git checkout -- file..." to discard changes in working directory)
# modified: src/Event.java
# modified: src/Simulator.java
# On branch master
# Untracked files:
# (use "git add file..." to include in what will be committed)
#
# simulator/input.txt
nothing added to commit but untracked files present (use "git add" to track)
- Including our Perl user
Untracked Files
- This did not necessarily correspond to a release or a good stopping place
- Git helpfully outputs all untracked files, ask yourself:
- Should they be tracked? You can always remove them later
- Can they simply be deleted?
- Can they be put in the .gitignore?
- Good for editor save files, compiled files etc.
# Editor save files *~ *.swp *.swo # Compiled source # ################### *.class *.pyc *.exe
Tip
Copy this into your.bashrc (or .brc on DiCE):
#
# Colors
#
RED="\[\033[0;31m\]"
YELLOW="\[\033[0;33m\]"
GREEN="\[\033[0;32m\]"
NORMAL="\[\033[0m\]"
#
# Prompt Setup
#
function parse_git_in_rebase {
[[ -d .git/rebase-apply ]] && echo " REBASING"
}
function parse_git_dirty {
[[ $(git status 2> /dev/null | tail -n1) != "nothing to commit (working directory clean)" ]] && echo "*"
}
function parse_git_branch {
branch=$(git branch 2> /dev/null | grep "*" | sed -e s/^..//g)
if [[ -z ${branch} ]]; then
return
fi
echo " ("${branch}$(parse_git_dirty)$(parse_git_in_rebase)")"
}
export PS1="$RED\u@\h:$GREEN\W$YELLOW\$(parse_git_branch)$NORMAL\$ " # Add git info to the prompt

Generated Files
- At least one person had generated files in their repository
$ git ls-files
README.md
bin/Bus.class
bin/Event.class
...
# On branch master
# Changed but not updated:
# (use "git add/rm file..." to update what will be committed)
# (use "git checkout -- file..." to discard changes in working directory)
#
# modified: bin/Event.class
# modified: bin/Simulator.class
Generated Files
Unanimous opinion on storing generated files in your repository:
# Compiled source #
###################
*.class
Git Commits
Git Lines
Git Lines
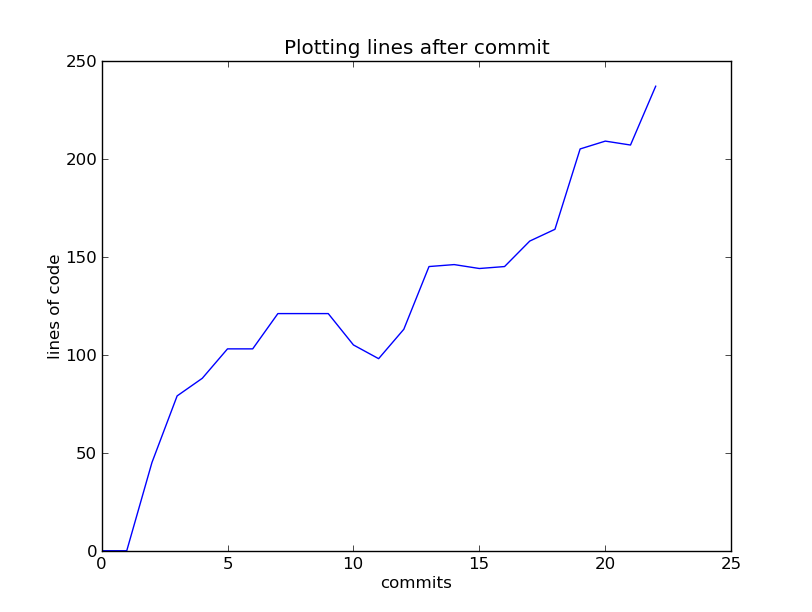
Git Lines
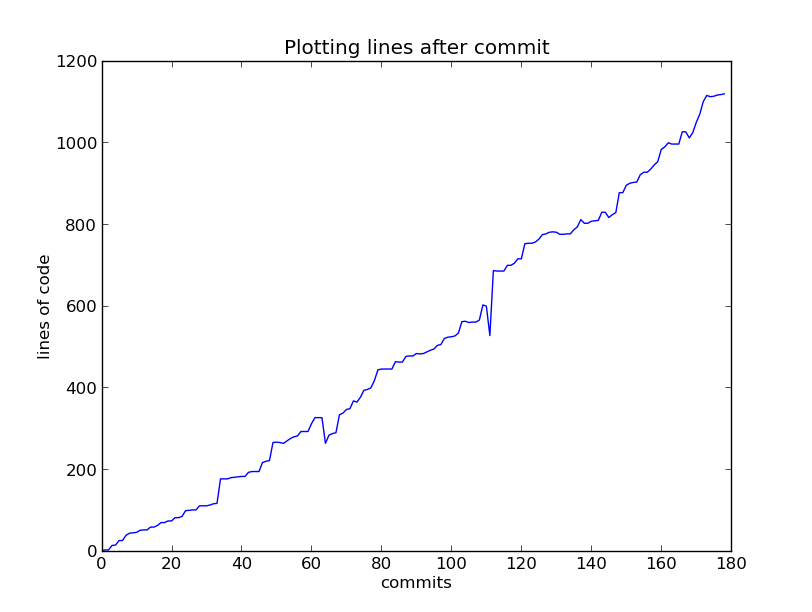
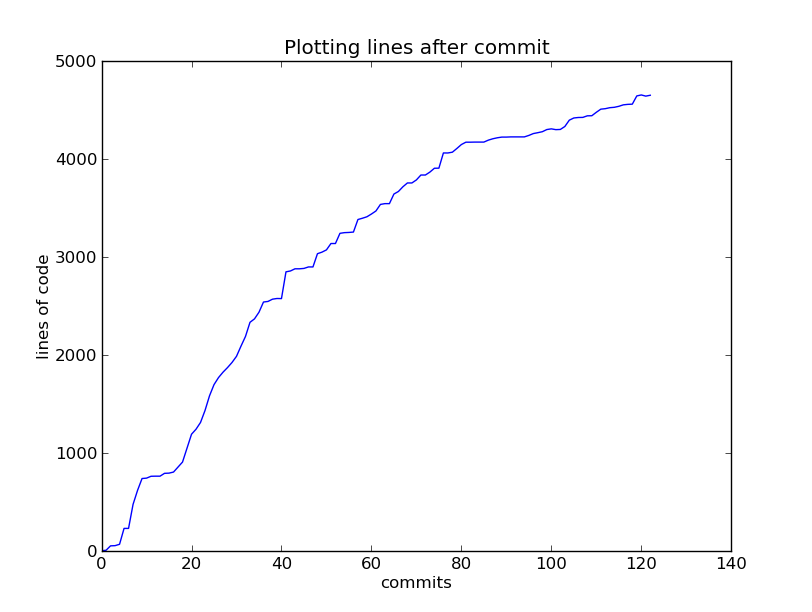

Git Lines
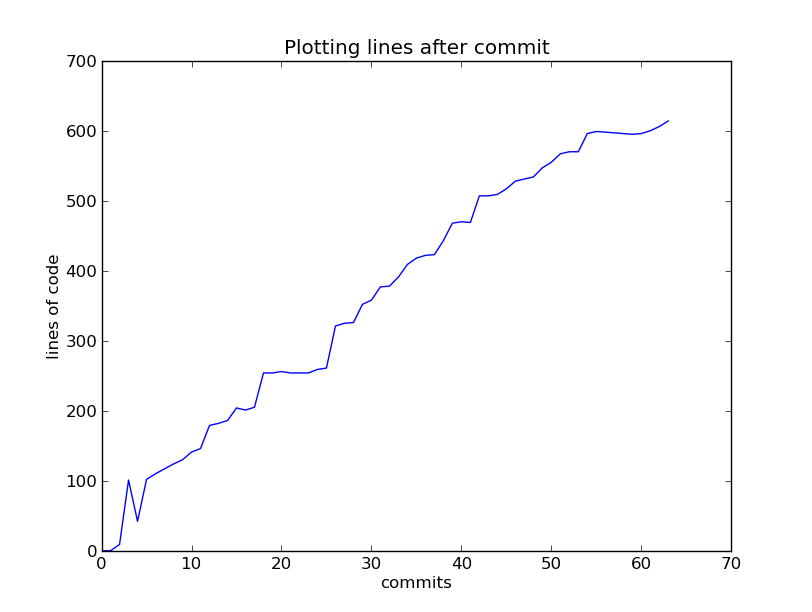
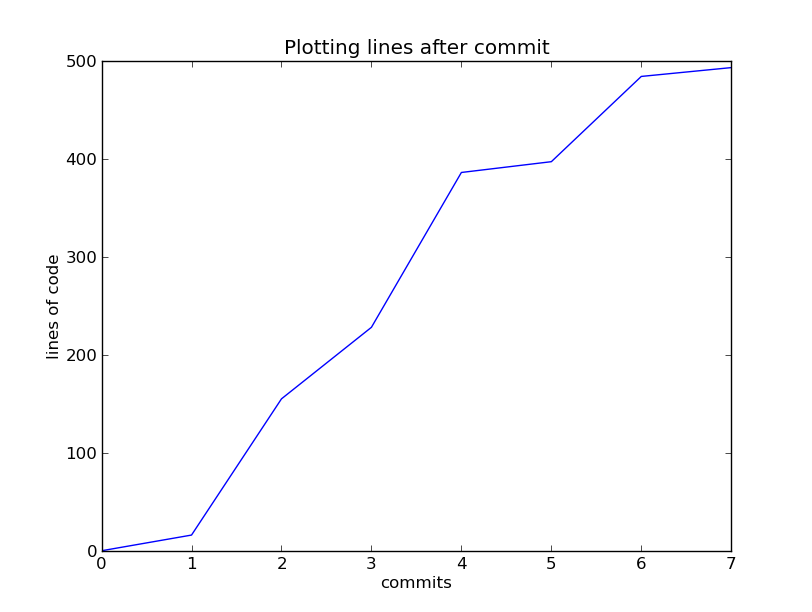
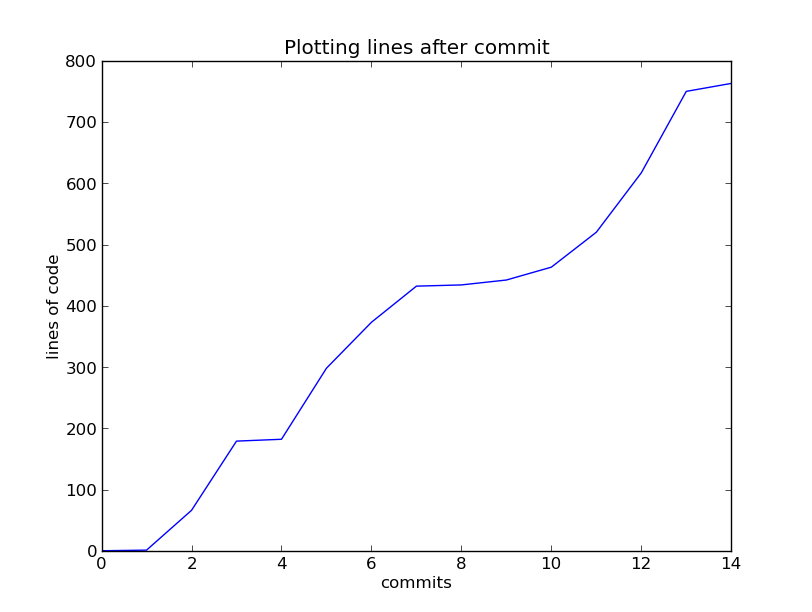
Git Lines
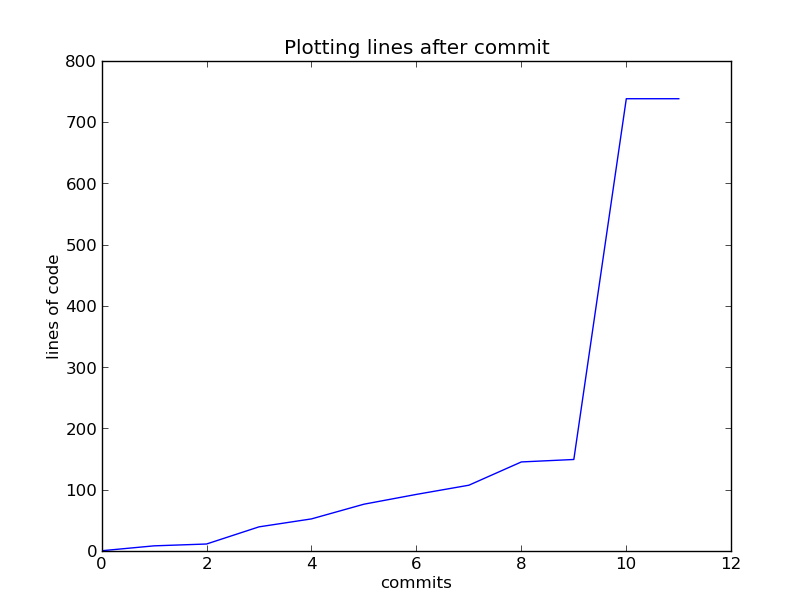
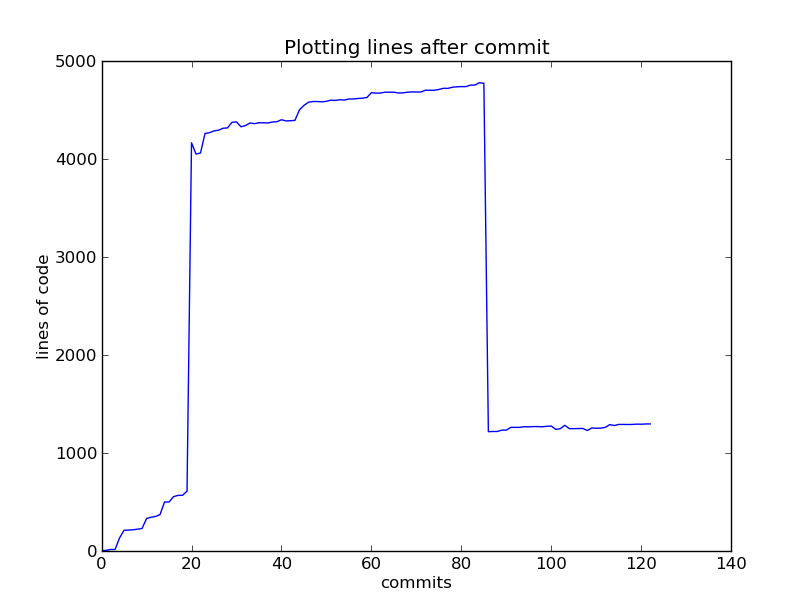
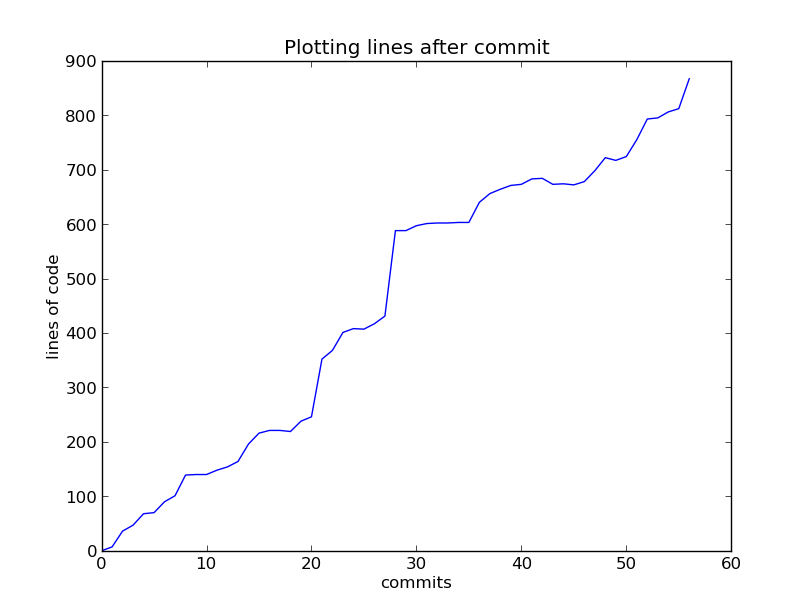
Git Lines
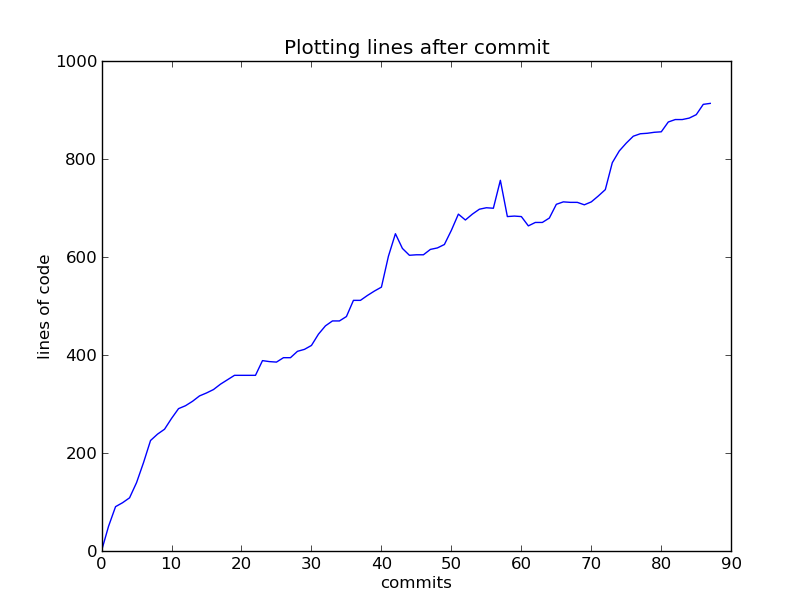
Refactoring
- 4 out of 13 logs contained any mention of refactoring
- 2 of those 4 was with reference to future refactoring:
- Either promising to refactor later or
- Explaining some code saying that it will make future refactoring easier
- It's early days yet, but still, refactoring is something you should be trying to do constantly
Command-line Applications
- NO: “To run this open up Eclipse and ...”
- Your program must be scriptable, so that I can run an external test suite over it
- In the real world, many apps are command-line apps:
- Even obviously GUI apps that run on your smartphone often communicate with some server
- You can run them remotely, for example on a web server
- You can run them on large computing clusters
- You can script them to add multiple-run functionality
Command-line Applications
- NO: “To run this open up Eclipse and ...”
- Here (briefly) is how to do this in Eclipse:
- Right click your project and select “Export”
- Select “JAR file”
- Select which packages to export (likely only one)
- Run it from the command line:
java -jar myprogram.jar args - More detailed instructions available here
Command-line Applications
- NO: “To run this open up Eclipse and ...”
- Alternatively try this:
$ javac *.java
$ java MyMainClass args
What's Wrong?
string num = "th";
int day = Convert.ToInt16(DateTime.Now.ToString("dd"));
switch(day)
{
case 1:
num = "st"; break;
case 21:
num = "st"; break;
case 31:
num = "st"; break;
case 2:
num = "nd"; break;
case 22:
num = "nd"; break;
case 3:
num = "rd"; break;
case 33:
num = "rd"; break;
default:
num = "th"; break;
}
What's Wrong?
string num = "th";
int day = Convert.ToInt16(DateTime.Now.ToString("dd"));
switch(day)
{
case 1:
case 21:
case 31:
num = "st"; break;
case 2:
case 22:
num = "nd"; break;
case 3:
case 33:
num = "rd"; break;
default:
num = "th"; break;
}
At Least
- Could stack the cases rather than copy-pasta code
33is arguably allowable but not at the expense of23- The date is converted to a string, which is then converted back to a number,
this will presumably then be converted back to a string to attach it to
num
Worst Error
- Of course the whole code is entirely unnecessary as there surely exists a library function to do the job for you
- The easiest code to write, is that which you do not have to write yourself
- It's also easier to maintain
- It's also probably more bug-free
- It also doesn't clutter up your source code repository
A More Subtle Error
string num = "th";
int day = Convert.ToInt16(DateTime.Now.ToString("dd"));
switch(day)
{
case 1:
case 21:
case 31:
num = "st"; break;
case 2:
case 22:
num = "nd"; break;
case 3:
case 33:
num = "rd"; break;
default:
num = "th"; break;
}
A More Subtle Error
- Initial setting of
num = "th" - In this case this is needless because of the
defaultclause - This is common, what does it guard against?
- The logic usually suggests that it guards against not setting
numwithin the switch and hence getting anuninitialised variableerror - When could that happen? When you have a bug!
- Again, better to return no value than an incorrect one
- You should defensively program against an uninitialised variable:
- What would you rather:
- “Monday the 23” or
- “Monday the 23th”
- What would you rather:
Multiple Files
- Quick Pop Quiz: Should you spread your implementation across multiple source code files?
Multiple Source Files
Common reasons given:- It increases code reusability
- It reduces compile time
- Encapsulation (remember, when someone says this, they are most likely bluffing)
- It makes code easier to find
Going File Crazy
- I'm not saying you should not, but do so for a good reason
Many Files
147 Bus.java
74 Event.java
132 Main.java
102 Network.java
46 Passenger.java
26 Road.java
28 Route.java
555 total
Many Files
public class Road {
private int firstStop; // Initial stop of the road
private int endStop; // Ending stop of the road
private float rate; // Rate of a bus traversing the road
// Basic constructor
public Road (int fs, int es, float r) {
this.firstStop = fs;
this.endStop = es;
this.rate = r;
}
// Getter Functions
public int firstStop() {
return this.firstStop;
}
public int endStop() {
return this.endStop;
}
public float rate() {
return this.rate;
}
}
Many Files
Not just the Java developers:
34 bus.py
19 event.py
58 passenger.py
8 road.py
25 route.py
113 simulation_execution.py
101 simulation_instance.py
114 simulator_io.py
12 simulator.py
27 stop.py
12 unit_tests_main.py
314 unit_tests.py
837 total
Many Files
class Road:
def __init__(self,first_stop,second_stop,rate):
assert (first_stop.routes & second_stop.routes) != set([]) ,
"road must be between two stops who are adjacent on at least one route"
assert rate > 0 , "rates of roads must be positive"
self.first_stop = first_stop
self.second_stop = second_stop
self.rate = rate
Personally
- I try to use a few files as possible
- New classes are simply written where required
- I only move them out to their own file when that seems necessary
Getter Functions
What is the purpose of a getter function?
// Getter Functions
public int firstStop() {
return this.firstStop;
}
public int endStop() {
return this.endStop;
}
public float rate() {
return this.rate;
}
Getter Functions
- Generally to avoid making the field in question public
- Why? So that later if you wish to make this a computed value you can
- Is it likely the “firstStop” will ever become a computed value?
- If it does, you can replace the field with a method and the static type checker will show you all the references you have to change
- In fairness, the getter, means that the consumer cannot update
the value:
- Since you do not wish to update it privately either you could just make it an immutable field
- The fact that you cannot mark something as only privately mutable is something of a flaw in the language
- You could be developing an API
Object Sequences
- A few people have done something like this:
...
some_object = SomeClass(...);
some_object.do_something(..);
some_object.do_next_thing(..);
some_object.do_the_final_thing(..);
...
Object Sequences
- More concretely, a few people did this:
...
simulation = Simulator(...);
simulation.set_up(..);
simulation.run_simulation(..);
simulation.conclude(..);
...
Premature Optimisation
- A few did something like the following:
- I see that there are many events which are all currently possible
- When I select one, and update the state accordingly, that often does not affect the others
- Therefore I should memorise the list of possible actions and only remove those that the current action makes impossible
- This is not a bad idea
- It does seem a little premature when the rest of your simulation is not yet working
- Tip: What happens when a bus with capacity N boards its Nth customer?
Simulator and State
- What is a Simulator?
- What is the state of the simulator?
- Are they one and the same thing?
- Many of you, even though you have not gotten as far as implementing experimentation, seem to be worried by this
- Correctly so, it could prove tricky
- The simulation algorithm must operate over the state of the simulation
- How can you be sure that the ending state of one experiment does not affect the starting state of the next experiment run?
- Do you require multiple simulators to run multiple simulations?
Things Which Should Not Happen
Here is a bit of code from one student's submission
private int getStopIndexByID(int id) {
for .... {
if ...{
return correctId;
}
}
return -1; // if all the other code is correct
// that should never happen
}
Here's the calling code:
// update stop buses here
stops[getStopIndexByID(b.currentStop)].addBus(b);
What's Wrong with it?
private int getStopIndexByID(int id) {
for .... {
if ...{
return correctId;
}
}
return -1; // if all the other code is correct
// that should never happen
}
- Remember the golden rule:
- “Better to return no answer than an incorrect answer”
Two Ways to Fix This
- Return some type which forces you to check if there was an error
- This is surprisingly tricky in most object-oriented languages
- Functional languages have this done well, with
OptionorMaybe
match getCorrectId(name) with | None -> print_error(str(name) + " not ...") | Some v -> do_something(v) - I cannot
do_something(v)without pattern matching against the Option type
Two Ways to Fix This
- Return some type which forces you to check if there was an error
Nulldoes not quite fill this need- Because it does not force you to check that the value returned is not Null
- Returning
Nullas an error value is generally the wrong thing to do - At worst the
Nullmight be later interpreted incorrectly as meaning something, e.g. an empty list - At best you will ultimately raise a NullPointerException
- You can avoid the uncertainty by:
Two Ways to Fix This
- Throw an exception
private int getStopIndexByID(int id) {
//blah blah might return correctId
throw new IdNotFound(..); // Should never ...
}
The Original Case
If the id is not found, anOutOfBounds array access exception
will be raised.
// update stop buses here
stops[getStopIndexByID(b.currentStop)].addBus(b);
- So you end up raising an exception anyway
- But here you get an
OutOfBoundserror report rather thanIdNotFounderror report - Why make things difficult for yourself
- Additionally if this calling code changes we may end up simply giving an incorrect answer
Exceptions
- Exceptions are both loved and loathed
- Part of the reason for the loathing is the “non-obvious control paths” which can result
- Try to use exceptions for things which you really do not believe can can happen under any normal executing conditions
- Essentially, they are for things that you would like the type system to ensure can never happen, but for which the type system is not sophisticated enough
- Rather less appropriate for errors made by the user, for example errors in the input
Exceptions and Validation
- Given this definition what should you do if you discover you have incomplete information during a simulation run?
- For example, you attempt to retrieve the
rateassociated with a road and find that it is unavailable - This is not exceptional, because the user may have simply forgotten to specify the rate for that particular road
- However, if you validate the input before running the simulation, then it really is exceptional to find a missing rate during the simulation
- Because the simulation should not have been started since the validation should have uncovered the error
YAGNI
- A final piece of advice
- Try to keep things simple: Do the simplest thing that could work
- Then rethink/refactor if it does not work
- YAGNI: You Aren't Gonna Need It
- Try not to over-complicate things by over-anticipating future requirements
Any Questions?
Going Class Crazy
- A really good video on why writing classes can be harmful
- Main piece of advice; “If you see a class with one method consider re-writing it as a function”
- A good rebuttal
Going Class Crazy
- Partly class craziness may be attributed to the popularity of Java
- Which does not have first class functions
- Just a way of saying functions can be passed around as normal values
- You can fake this in Java by creating a simple class containing that function
- So to pass a function in as a parameter in Java, one must:
- Create a class
- Create an instance of that class
- This has caused many to believe that creating classes is the way to go for all manner of things
Going Class Crazy
- Here is a good couple of questions to ask yourself:
- What is my class?
- What is an instance of my class?
- If the answer is the same, then at best, you're really just bunching some functions together
Going Class Crazy
- Do not forget, an object is a gathering of state together with behaviour/operations over that state
- If your object lacks either state or behaviour, then it is not an object
- Tip: design your object first and then write your class to produce such objects